In business forecast applications, I often have been asked, “why don’t you forecast the stock market?” It’s almost a variant of “if you’re so smart, why aren’t you rich?” I usually respond something about stock prices being largely random walks.
But, stock market predictability is really the nut kernel of forecasting, isn’t it?
Earlier this year, I looked at the S&P 500 index and the SPY ETF numbers, and found I could beat a buy and hold strategy with a regression forecasting model. This was an autoregressive model with lots of lagged values of daily S&P returns. In some variants, it included lagged values of the Chicago Board of Trade VIX volatility index returns. My portfolio gains were compiled over an out-of-sample (OS) period. This means, of course, that I estimated the predictive regression on historical data that preceded and did not include the OS or test data.
Well, today I’m here to report to you that it looks like it is officially possible to achieve some predictability of stock market returns in out-of-sample data.
One authoritative source is Forecasting Stock Returns, an outstanding review by Rapach and Zhou in the recent, second volume of the Handbook of Economic Forecasting.
The story is fascinating.
For one thing, most of the successful models achieve their best performance – in terms of beating market averages or other common benchmarks – during recessions.
And it appears that technical market indicators, such as the oscillators, momentum, and volume metrics so common in stock trading sites, have predictive value. So do a range of macroeconomic indicators.
But these two classes of predictors – technical market and macroeconomic indicators – are roughly complementary in their performance through the business cycle. As Christopher Neeley et al detail in Forecasting the Equity Risk Premium: The Role of Technical Indicators,
Macroeconomic variables typically fail to detect the decline in the actual equity risk premium early in recessions, but generally do detect the increase in the actual equity risk premium late in recessions. Technical indicators exhibit the opposite pattern: they pick up the decline in the actual premium early in recessions, but fail to match the unusually high premium late in recessions.
Stock Market Predictors – Macroeconomic and Technical Indicators
Rapach and Zhou highlight fourteen macroeconomic predictors popular in the finance literature.
1. Log dividend-price ratio (DP): log of a 12-month moving sum of dividends paid on the S&P 500 index minus the log of stock prices (S&P 500 index).
2. Log dividend yield (DY): log of a 12-month moving sum of dividends minus the log of lagged stock prices.
3. Log earnings-price ratio (EP): log of a 12-month moving sum of earnings on the S&P 500 index minus the log of stock prices.
4. Log dividend-payout ratio (DE): log of a 12-month moving sum of dividends minus the log of a 12-month moving sum of earnings.
5. Stock variance (SVAR): monthly sum of squared daily returns on the S&P 500 index.
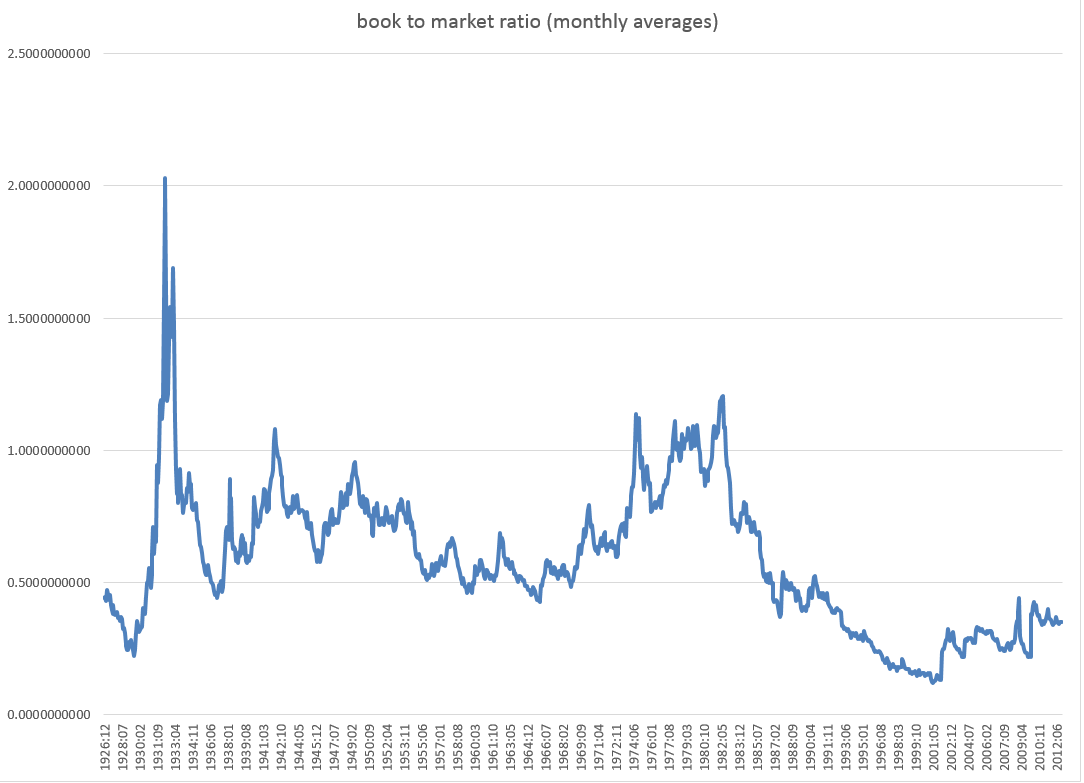
6. Book-to-market ratio (BM): book-to-market value ratio for the DJIA.
7. Net equity expansion (NTIS): ratio of a 12-month moving sum of net equity issues by NYSE-listed stocks to the total end-of-year market capitalization of NYSE stocks.
8. Treasury bill rate (TBL): interest rate on a three-month Treasury bill (secondary market).
9. Long-term yield (LTY): long-term government bond yield.
10. Long-term return (LTR): return on long-term government bonds.
11. Term spread (TMS): long-term yield minus the Treasury bill rate.
12. Default yield spread (DFY): difference between BAA- and AAA-rated corporate bond yields.
13. Default return spread (DFR): long-term corporate bond return minus the long-term government bond return.
14. Inflation (INFL): calculated from the CPI (all urban consumers
In addition, there are technical indicators, which are generally moving average, momentum, or volume-based.
The moving average indicators typically provide a buy or sell signal based on a comparing two moving averages – a short and a long period MA.
Momentum based rules are based on the time trajectory of prices. A current stock price higher than its level some number of periods ago indicates “positive” momentum and expected excess returns, and generates a buy signal.
Momentum rules can be combined with information about the volume of stock purchases, such as Granville’s on-balance volume.
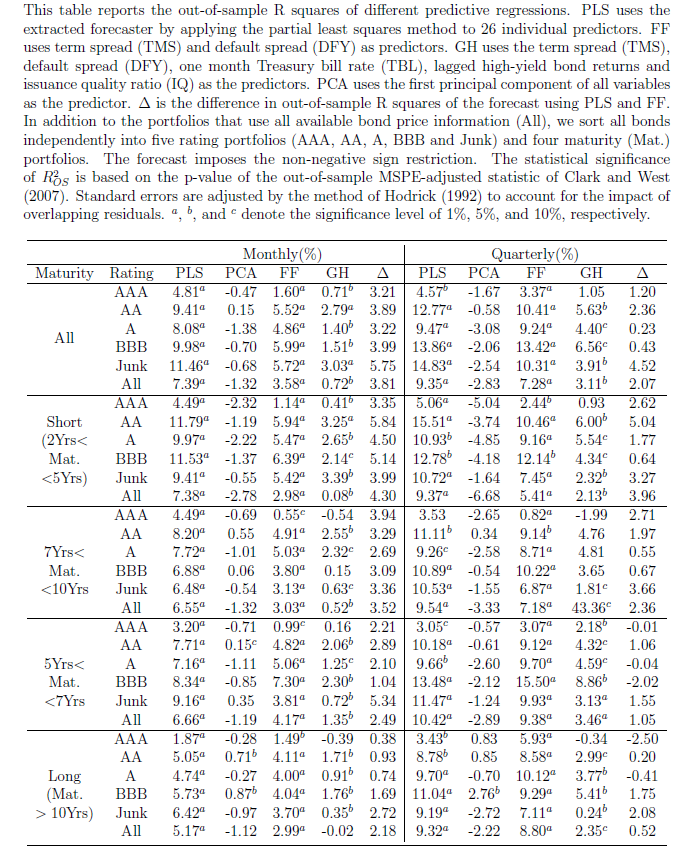
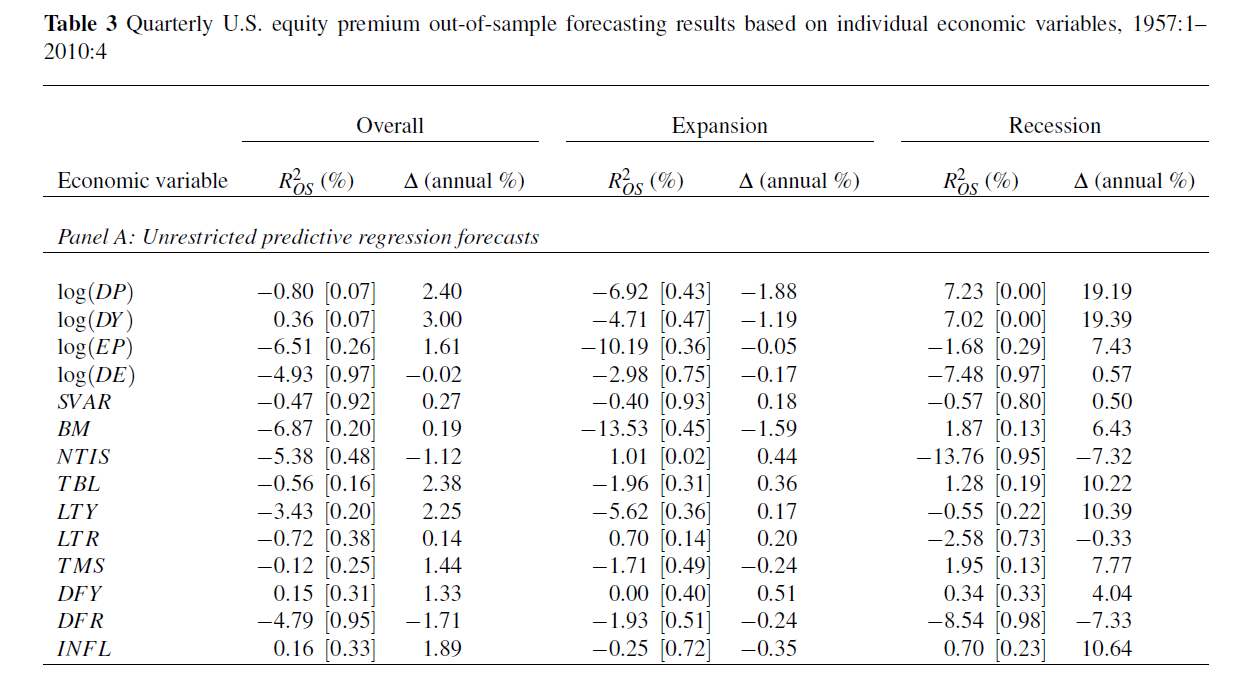
Each of these predictors can be mapped onto equity premium excess returns – measured by the rate of return on the S&P 500 index net of return on a risk-free asset. This mapping is a simple bi-variate regression with equity returns from time t on the left side of the equation and the economic predictor lagged by one time period on the right side of the equation. Monthly data are used from 1927 to 2008. The out-of-sample (OS) period is extensive, dating from the 1950’s, and includes most of the post-war recessions.
The following table shows what the authors call out-of-sample (OS) R2 for the 14 so-called macroeconomic variables, based on a table in the Handbook of Forecasting chapter. The OS R2 is equal to 1 minus a ratio. This ratio has the mean square forecast error (MSFE) of the predictor forecast in the numerator and the MSFE of the forecast based on historic average equity returns in the denominator. So if the economic indicator functions to improve the OS forecast of equity returns, the OS R2 is positive. If, on the other hand, the historic average trumps the economic indicator forecast, the OS R2 is negative.
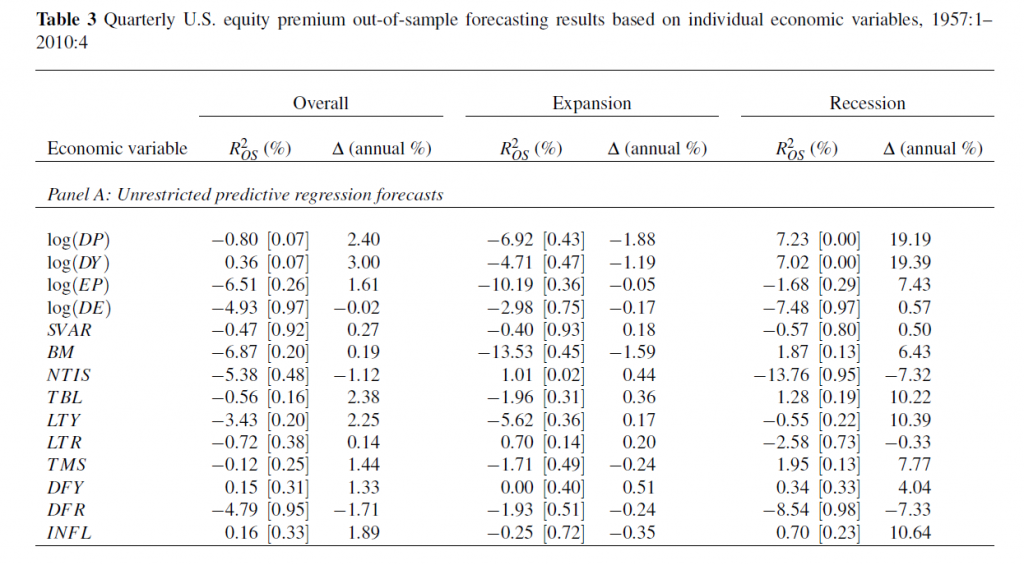
(click to enlarge).
Overall, most of the macro predictors in this list don’t make it. Thus, 12 of the 14 OS R2 statistics are negative in the second column of the Table, indicating that the predictive regression forecast has a higher MSFE than the historical average.
For two of the predictors with a positive out-of-sample R2, the p-values reported in the brackets are greater than 0.10, so that these predictors do not display statistically significant out-of-sample performance at conventional levels.
Thus, the first two columns in this table, under “Overall”, support a skeptical view of the predictability of equity returns.
However, during recessions, the situation is different.
For several the predictors, the R2 OS statistics move from being negative (and typically below -1%) during expansions to 1% or above during recessions. Furthermore, some of these R2 OS statistics are significant at conventional levels during recessions according to the p-values, despite the decreased number of available observations.
Now imposing restrictions on the regression coefficients substantially improves this forecast performance, as the lower panel (not shown) in this table shows.
Rapach and Zhou were coauthors of the study with Neeley, published earlier as a working paper with the St. Louis Federal Reserve.
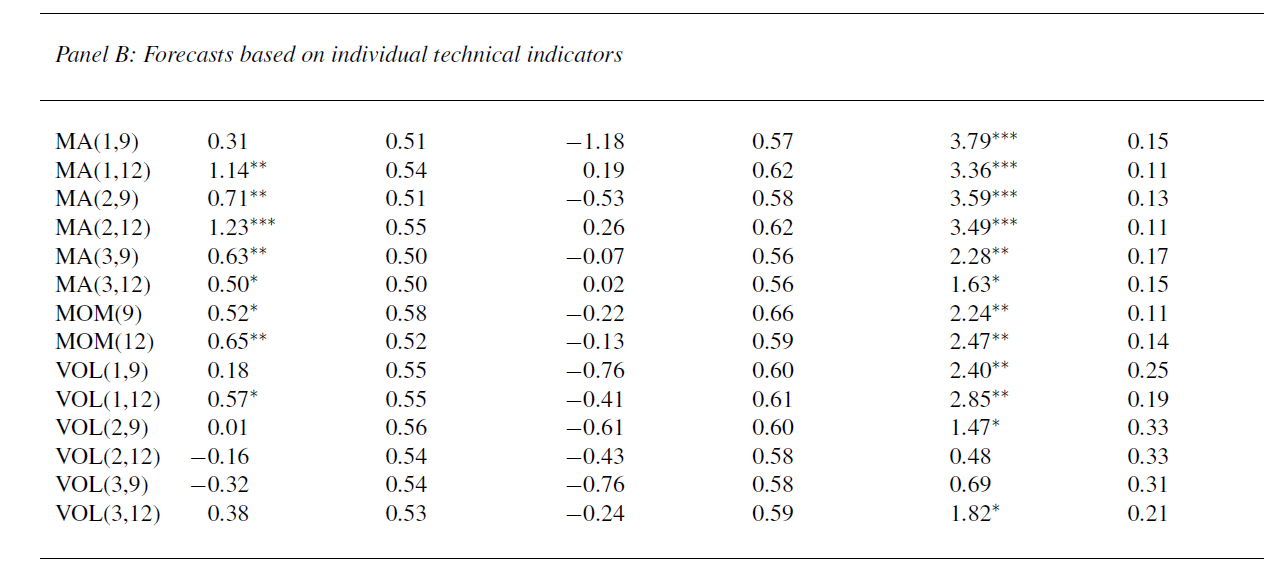
This working paper is where we get the interesting report about how technical factors add to the predictability of equity returns (again, click to enlarge).
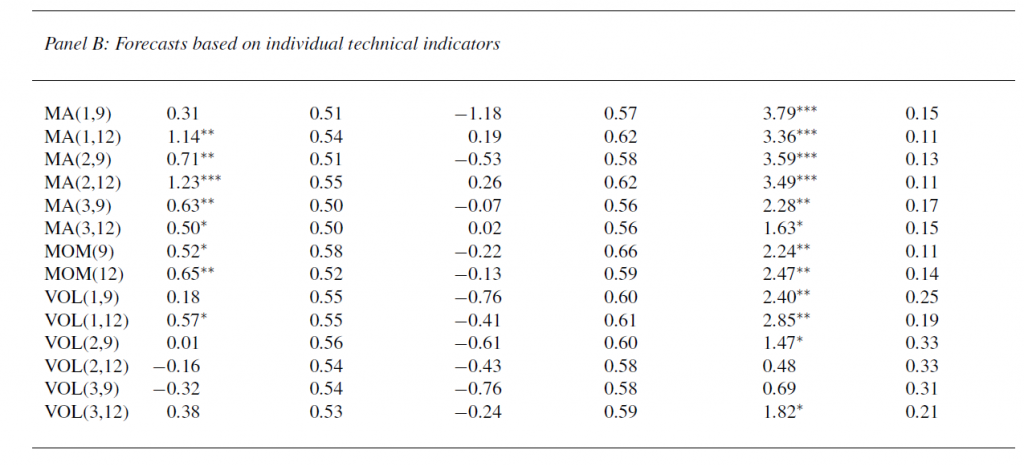
This table has the same headings for the columns as Table 3 above.
It shows out-of-sample forecasting results for several technical indicators, using basically the same dataset, for the overall OS period, for expansions, and recessions in this period dating from the 1950’s to 2008.
In fact, these technical indicators generally seem to do better than the 14 macroeconomic indicators.
Low OS R2
Even when these models perform their best, their increase in mean square forecast error (MSFE) is only slightly more than the MSFE of the benchmark historic average return estimate.
This improved performance, however, can still achieve portfolio gains for investors, based on various trading rules, and, as both papers point out, investors can use the information in these forecasts to balance their portfolios, even when the underlying forecast equations are not statistically significant by conventional standards. Interesting argument, and I need to review it further to fully understand it.
In any case, my experience with an autoregressive model for the S&P 500 is that trading rules can be devised which produce portfolio gains over a buy and hold strategy, even when the R2 is on the order of 1 or a few percent. All you have to do is correctly predict the sign of the return on the following trading day, for instance, and doing this a little more than 50 percent of the time produces profits.
Rapach and Zhou, in fact, develop insights into how predictability of stock returns can be consistent with rational expectations – providing the relevant improvements in predictability are bounded to be low enough.
Some Thoughts
There is lots more to say about this, naturally. And I hope to have further comments here soon.
But, for the time being, I have one question.
The is why econometricians of the caliber of Rapach, Zhou, and Neeley persist in relying on tests of statistical significance which are predicated, in a strict sense, on the normality of the residuals of these financial return regressions.
I’ve looked at this some, and it seems the t-statistic is somewhat robust to violations of normality of the underlying error distribution of the regression. However, residuals of a regression on equity rates of return can be very non-normal with fat tails and generally some skewness. I keep wondering whether anyone has really looked at how this translates into tests of statistical significance, or whether what we see on this topic is mostly arm-waving.
For my money, OS predictive performance is the key criterion.