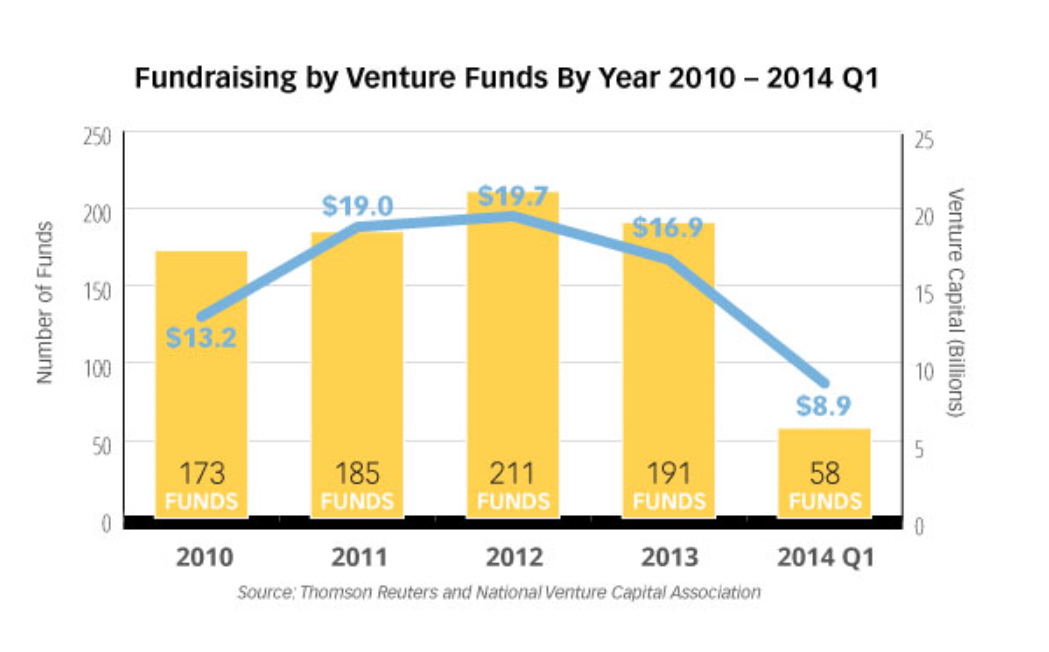
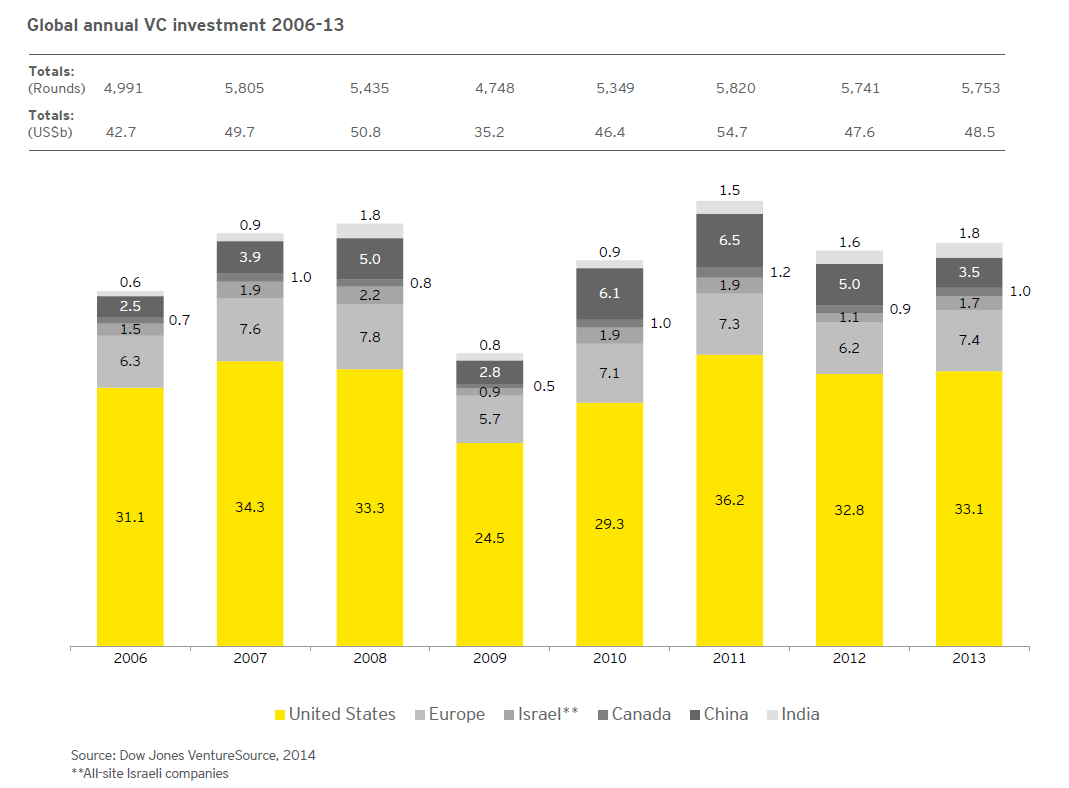
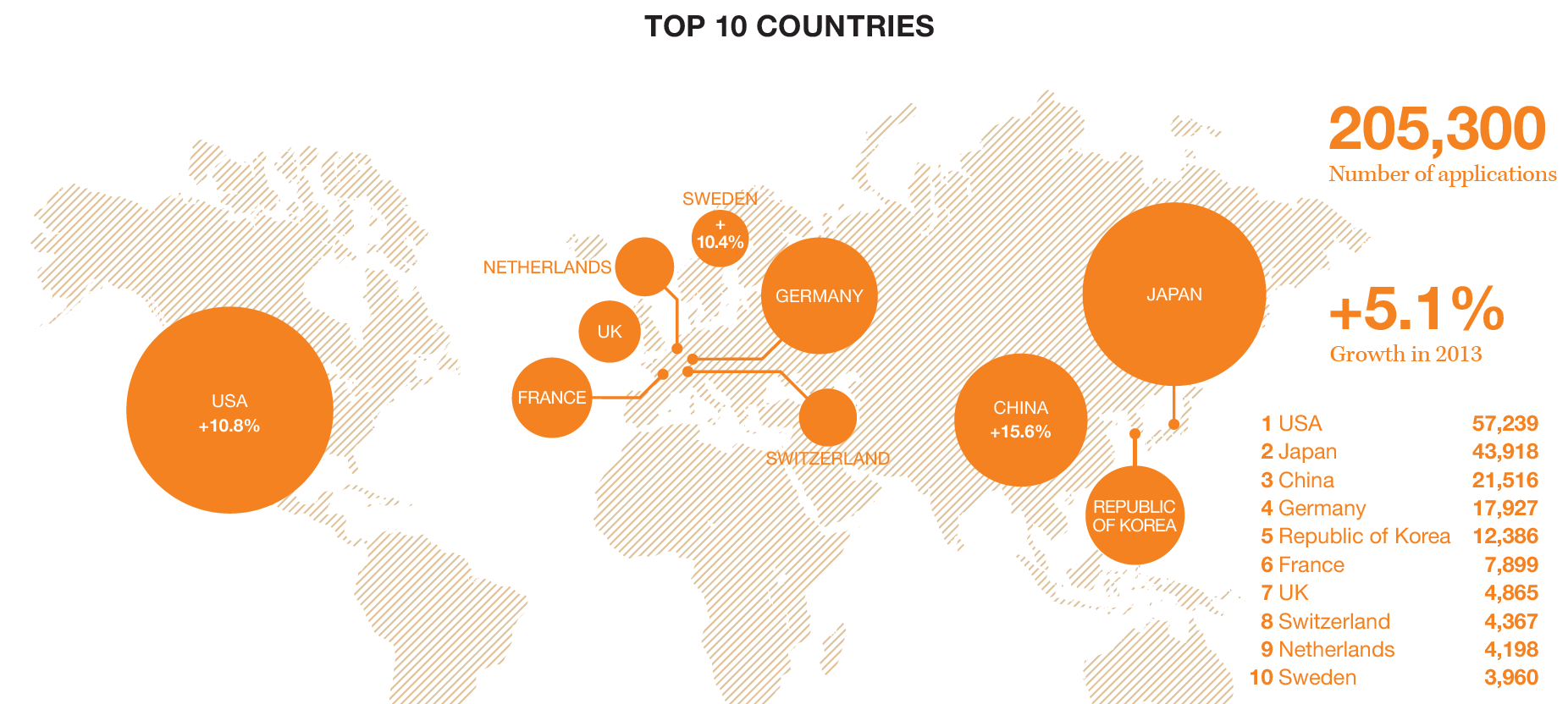
Christof Rühl – Group Chief Economist at British Petroleum (BP) just released an excellent, short summary of the global energy situation, focused on 2013.

Rühl’s video is currently only available on the BP site at –
Note the BP Statistical Review of World Energy June 2014 was just released (June 16).
Highlights include –
- Economic growth is one of the biggest determinants of energy growth. This means that energy growth prospects in Asia and other emerging markets are likely to dominate slower growth in Europe – where demand is actually less now than in 2005 – and the US.
- Tradeoffs and balancing are a theme of 2013. While oil prices remained above $100/barrel for the third year in a row, seemingly stable, underneath two forces counterbalanced one another – expanding production from shale deposits in the US and an increasing number of supply disruptions in the Middle East and elsewhere.
- 2013 saw a slowdown in natural gas demand growth with coal the fastest growing fuel. Growth in shale gas is slowing down, partly because of a big price differential between gas and oil.
- While CO2 emissions continue to increase, the increased role of renewables or non-fossil fuels (including nuclear) have helped hold the line.
- The success story of the year is that the US is generating new fuels, improving its trade position and trade balance with what Rühl calls the “shale revolution.”
The BP Statistical Reviews of World Energy are widely-cited, and, in my mind, rank alongside the Energy Information Agency (EIA) Annual Energy Outlook and the International Energy Agency’s World Energy Outlook. The EIA’s International Energy Outlook is another frequently-cited document, scheduled for update in July.
Price is the key, but is difficult to predict
The EIA, to its credit, publishes a retrospective on the accuracy of its forecasts of prices, demand and production volumes. The latest is on a page called Annual Energy Outlook Retrospective Review which has a revealing table showing the EIA projections of the price of natural gas at wellhead and actual figures (as developed from the Monthly Energy Review).
I pulled together a graph showing the actual nominal price at the wellhead and the EIA forecasts.

The solid red line indicates actual prices. The horizontal axis shows the year for which forecasts are made. The initial value in any forecast series is nowcast, since wellhead prices are available at only a year lag. The most accurate forecasts were for 2008-2009 in the 2009 and 2010 AEO documents, when the impact of the severe recession was already apparent.
Otherwise, the accuracy of the forecasts is completely underwhelming.
Indeed, the EIA presents another revealing chart showing the absolute percentage errors for the past two decades of forecasts. Natural gas prices show up with more than 30 percent errors, as do imported oil prices to US refineries.
Predicting Reserves Without Reference to Prices
Possibly as a result of the difficulty of price projections, the EIA apparently has decoupled the concept of Technically Recoverable Resources (TRR) from price projections.
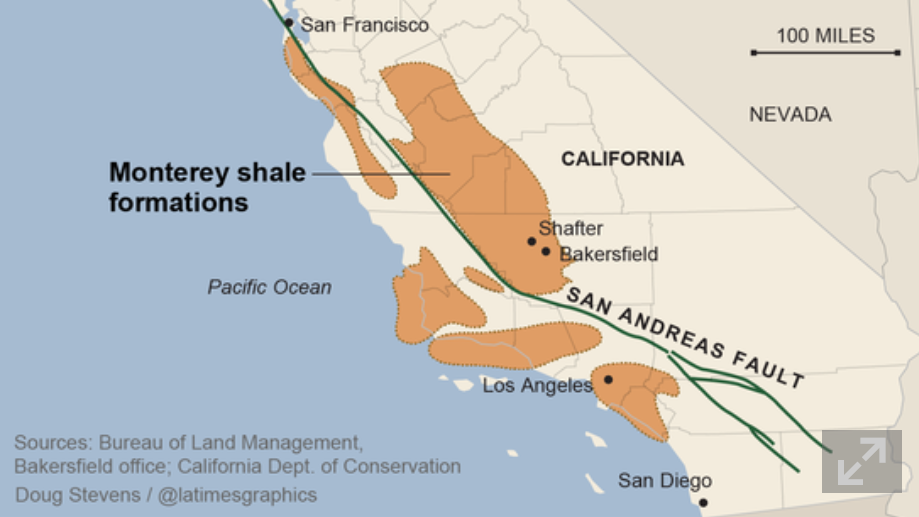
This helps explain how you can make huge writedowns of TRR in the Monterey Shale without affecting forecasts of future shale oil and gas production.
Thus in Assumptions to AEO2014 and the section called the Oil and Gas Supply Module, we read –
While technically recoverable resources (TRR) is a useful concept, changes in play-level TRR estimates do not necessarily have significant implications for projected oil and natural gas production, which are heavily influenced by economic considerations that do not enter into the estimation of TRR. Importantly, projected oil production from the Monterey play is not a material part of the U.S. oil production outlook in either AEO2013 or AEO2014, and was largely unaffected by the change in TRR estimates between the 2013 and 2014 editions of the AEO. EIA estimates U.S. total crude oil production averaged 8.3 million barrels/day in April 2014. In the AEO2014 Reference case, economically recoverable oil from the Monterey averaged 57,000 barrels/day between 2010 and 2040, and in the AEO2013 the same play’s estimated production averaged 14,000 barrels/day. The difference in production between the AEO2013 and AEO2014 is a result of data updates for currently producing wells which were not previously linked to the Monterey play and include both conventionally-reservoired and continuous-type shale areas of the play. Clearly, there is not a proportional relationship between TRR and production estimates – economics matters, and the Monterey play faces significant economic challenges regardless of the TRR estimate.
This year EIA’s estimate for total proved and unproved U.S. technically recoverable oil resources increased 5.4 billion barrels to 238 billion barrels, even with a reduction of the Monterey/Santos shale play estimate of unproved technically recoverable tight oil resources from 13.7 billion barrels to 0.6 billion barrels. Proved reserves in EIA’s U.S. Crude Oil and Natural Gas Proved Reserves report for the Monterey/Santos shale play are withheld to avoid disclosure of individual company data. However, estimates of proved reserves in NEMS are 0.4 billion barrels, which result in 1 billion barrels of total TRR.
Key factors driving the adjustment included new geology information from a U. S. Geological Survey review of the Monterey shale and a lack of production growth relative to other shale plays like the Bakken and Eagle Ford. Geologically, the thermally mature area is 90% smaller than previously thought and is in a tectonically active area which has created significant natural fractures that have allowed oil to leave the source rock and accumulate in the overlying conventional oil fields, such as Elk Hills, Cat Canyon and Elwood South (offshore). Data also indicate the Monterey play is not over pressured and thus lacks the gas drive found in highly productive tight oil plays like the Bakken and Eagle Ford. The number of wells per square mile was revised down from 16 to 6 to represent horizontal wells instead of vertical wells. TRR estimates will likely continue to evolve over time as technology advances, and as additional geologic information and results from drilling activity provide a basis for further updates.
So the shale oil in the Monterey formation may have “migrated” from that convoluted geologic structure to sand deposits or elsewhere, leaving the productive potential much less.
I still don’t understand how it is possible to estimate any geologic reserve without reference to price, but there you have it.
I plan to move on to more manageable energy aggregates, like utility power loads and time series forecasts of consumption in coming posts.
But the shale oil and gas scene in the US is fascinating and a little scary. Part of the gestalt is the involvement of smaller players – not just BP and Exxon, for example. According to Chad Moutray, Economist for the National Association of Manufacturers, the fracking boom is a major stimulus to manufacturing jobs up and down the supply chain. But the productive life of a fracked oil or gas well is typically shorter than a conventional oil or gas well. So some claim that the increases in US production cannot be sustained or will not lead to any real period of “energy independence.” For my money, I need to watch this more before making that kind of evaluation, but the issue is definitely there.