In thinking about Bayesian methods, I wanted to focus on whether and how Bayesian probabilities are or can be made “intuitive.”
Or are they just numbers plugged into a formula which sometimes is hard to remember?
A classic example of Bayesian reasoning concerns breast cancer and mammograms.
| 1% of the women at age forty who participate in routine screening have breast cancer |
| 80% of women with breast cancer will get positive mammograms. |
| 9.6% of women with no breast cancer will also get positive mammograms |
Question – A women in this age group has a positive mammogram in a routine screening. What is the probability she has cancer?
There is a tendency for intuition to anchor on the high percentage of women with breast cancer with positive mammograms – 80 percent. In fact, this type of scenario elicits significant over-estimates of cancer probabilities among mammographers!
Bayes Theorem, however, shows that the probability of women with a positive mammogram having cancer is an order of magnitude less than the percent of women with breast cancer and positive mammograms.
By the Formula
Recall Bayes Theorem –
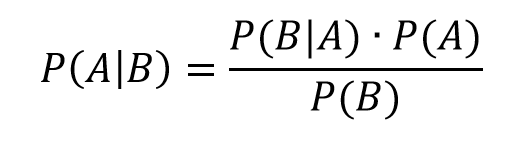
Let A stand for the event a women has breast cancer, and B denote the event that a women tests positive on the mammogram.
We need the conditional probability of a positive mammogram, given that a woman has breast cancer, or P(B|A). In addition, we need the prior probability that a woman has breast cancer P(A), as well as the probability of a positive mammogram P(B).
So we know P(B|A)=0.8, and P(B|~A)=0.096, where the tilde ~ indicates “not”.
For P(B) we can make the following expansion, based on first principles –
P(B)=P(B|A)P(A)+P(B|~A)P(B)= P(B|A)P(A)+P(B|~A)(1-P(A))=0.10304
Either a woman has cancer or does not have cancer. The probability of a woman having cancer is P(A), so the probability of not having cancer is 1-P(A). These are mutually exclusive events, that is, and the probabilities sum to 1.
Putting the numbers together, we calculate the probability of a forty-year-old women with a positive mammogram having cancer is 0.0776.
So this woman has about an 8 percent chance of cancer, even though her mammogram is positive.
Survey after survey of physicians shows that this type of result in not very intuitive. Many doctors answer incorrectly, assigning a much higher probability to the woman having cancer.
Building Intuition
This example is the subject of a 2003 essay by Eliezer Yudkowsky – An Intuitive Explanation of Bayes’ Theorem.
As An Intuitive (and Short) Explanation of Bayes’ Theorem notes, Yudkowsky’s intuitive explanation is around 15,000 words in length.
For a shorter explanation that helps build intuition, the following table is useful, showing the crosstabs of women in this age bracket who (a) have or do not have cancer, and (b) who test positive or negative.
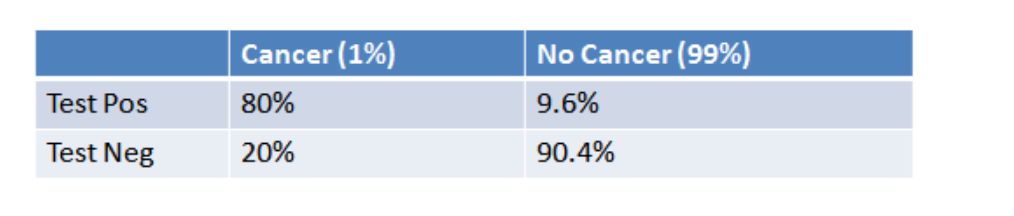
The numbers follow from our original data. The percentage of women with cancer who test positive is given as 80 percent, so the percent with cancer who test negative must be 20 percent, and so forth.
Now let’s embed the percentages of true and false positives and negatives into the table, as follows:
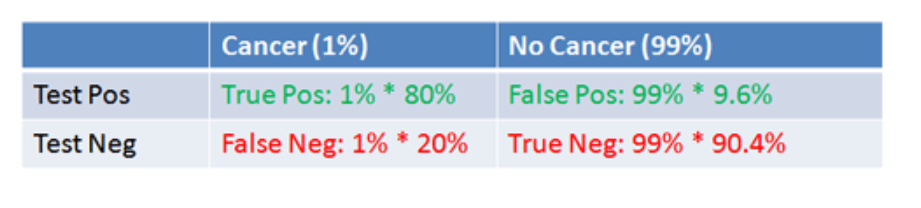
So 1 percent of forty year old women (who have routine screening) have cancer. If we multiply this 1 percent by the percent of women who have cancer and test positive, we get .008 or the chances of a true positive. Then, the chance of getting any type of positive result is .008+.99*.096=.008+.0954=0.10304.
The ratio then of the chances of a true positive to the chance of any type of positive result is 0.07763 – exactly the result following from Bayes Theorem!

This may be an easier two-step procedure than trying to develop conditional probabilities directly, and plug them into a formula.
Allen Downey lists other problems of this type, with YouTube talks on Bayesian stuff that are good for beginners.
Closing Comments
I have a couple more observations.
First, this analysis is consistent with a frequency interpretation of probability.
In fact, the 1 percent figure for women who are forty getting cancer could be calculated from cause of death data and Census data. Similarly with the other numbers in the scenario.
So that’s interesting.
Bayes theorem is, in some phrasing, true by definition (of conditional probability). It can just be tool for reorganizing data about observed frequencies.
The magic comes when we transition from events to variables y and parameters θ in a version like,
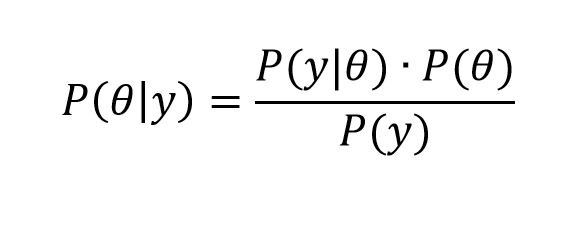
What is this parameter θ? It certainly does not exist in “event” space in the same way as does the event of “having cancer and being a forty year old woman.” In the batting averages example, θ is a vector of parameter values of a Beta distribution – parameters which encapsulate our view of the likely variation of a batting average, given information from the previous playing season. So I guess this is where we go into “belief space”and subjective probabilities.
In my view, the issue is always whether these techniques are predictive.
Top picture courtesy of Siemens