Professor Didier Sornette, who holds the Chair in Entreprenuerial Risks at ETH Zurich, is an important thinker, and it is heartening to learn the American Association for the Advancement of Science (AAAS) is electing Professor Sornette a Fellow.
It is impossible to look at, say, the historical performance of the S&P 500 over the past several decades, without concluding that, at some point, the current surge in the market will collapse, as it has done previously when valuations ramped up so rapidly and so far.

Sornette focuses on asset bubbles and has since 1998, even authoring a book in 2004 on the stock market.
At the same time, I think it is fair to say that he has been largely ignored by mainstream economics (although not finance), perhaps because his training is in physical science. Indeed, many of his publications are in physics journals – which is interesting, but justified because complex systems dynamics cross the boundaries of many subject areas and sciences.
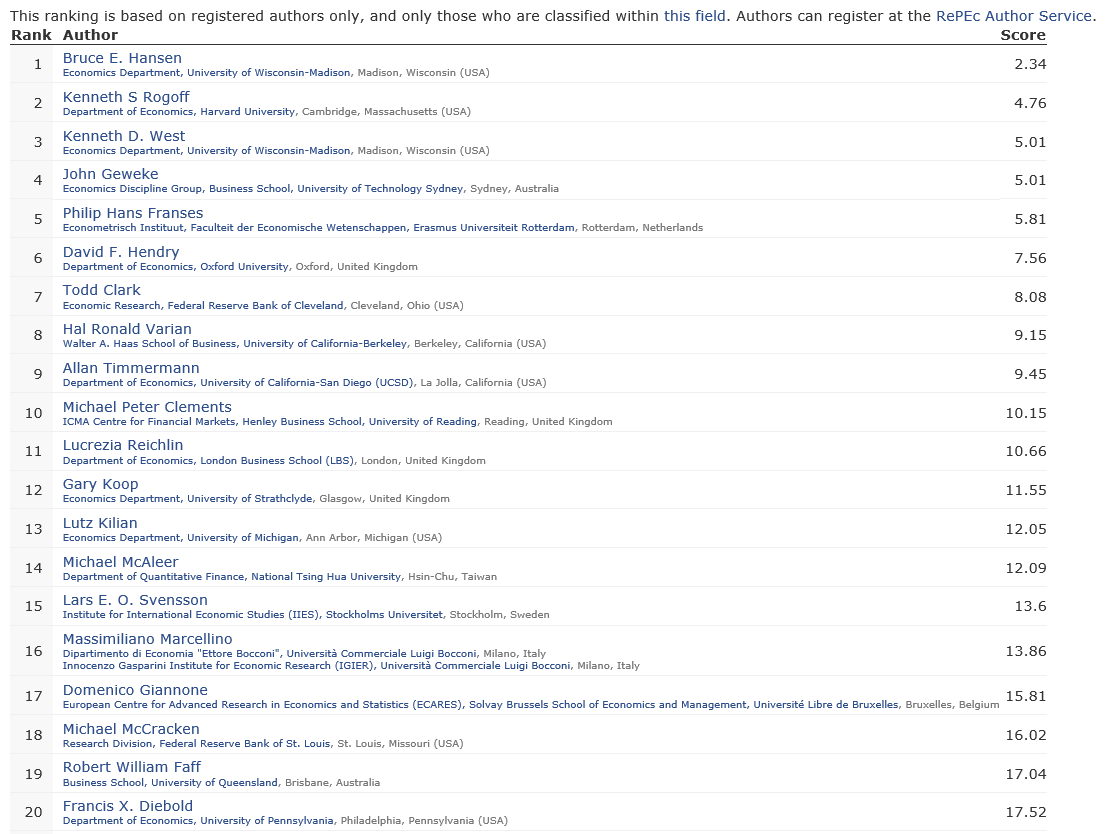
Over the past year or so, I have perused dozens of Sornette papers, many from the extensive list at http://www.er.ethz.ch/publications/finance/bubbles_empirical.
This list is so long and, at times, technical, that videos are welcome.
Along these lines there is Sornette’s Ted talk (see below), and an MP4 file which offers an excellent, high level summary of years of research and findings. This MP4 video was recorded at a talk before the International Center for Mathematical Sciences at the University of Edinburgh.
Intermittent criticality in financial markets: high frequency trading to large-scale bubbles and crashes. You have to download the file to play it.
By way of précis, this presentation offers a high-level summary of the roots of his approach in the economics literature, and highlights the role of a central differential equation for price change in an asset market.
So since I know everyone reading this blog was looking forward to learning about a differential equation, today, let me highlight the importance of the equation,
dp/dt = cpd
This basically says that price change in a market over time depends on the level of prices – a feature of markets where speculative forces begin to hold sway.
This looks to be a fairly simple equation, but the solutions vary, depending on the values of the parameters c and d. For example, when c>0 and the exponent d is greater than one, prices change faster than exponentially and within some finite period, a singularity is indicated by the solution to the equation. Technically, in the language of differential equations this is called a finite time singularity.
Well, the essence of Sornette’s predictive approach is to estimate the parameters of a price equation that derives, ultimately, from this differential equation in order to predict when an asset market will reach its peak price and then collapse rapidly to lower prices.
The many sources of positive feedback in asset pricing markets are the basis for the faster than exponential growth, resulting from d>1. Lots of empirical evidence backs up the plausibility and credibility of herd and imitative behaviors, and models trace out the interaction of prices with traders motivated by market fundamentals and momentum traders or trend followers.
Interesting new research on this topic shows that random trades could moderate the rush towards collapse in asset markets – possibly offering an alternative to standard regulation.
The important thing, in my opinion, is to discard notions of market efficiency which, even today among some researchers, result in scoffing at the concept of asset bubbles and basic sabotage of research that can help understand the associated dynamics.
Here is a TED talk by Sornette from last summer.