Considering that social and systems analysis originated largely in Europe (Machiavelli, Vico, Max Weber, Emile Durkheim, Walras, Adam Smith and the English school of political economics, and so forth), it’s not surprising that any deep analysis of the current European situation is almost alarmingly complex, reticulate, and full of nuance.
However, numbers speak for themselves, to an extent, and I want to start with some basic facts about geography, institutions, and economy.
Then, I’d like to precis the current problem from an economic perspective, leaving the Ukraine conflict and its potential for destabilizing things for a later post.
Some Basic Facts About Europe and Its Institutions
But some basic facts, for orientation. The 2013 population of Europe, shown in the following map, is estimated at just above 740 million persons. This makes Europe a little over 10 percent of total global population.
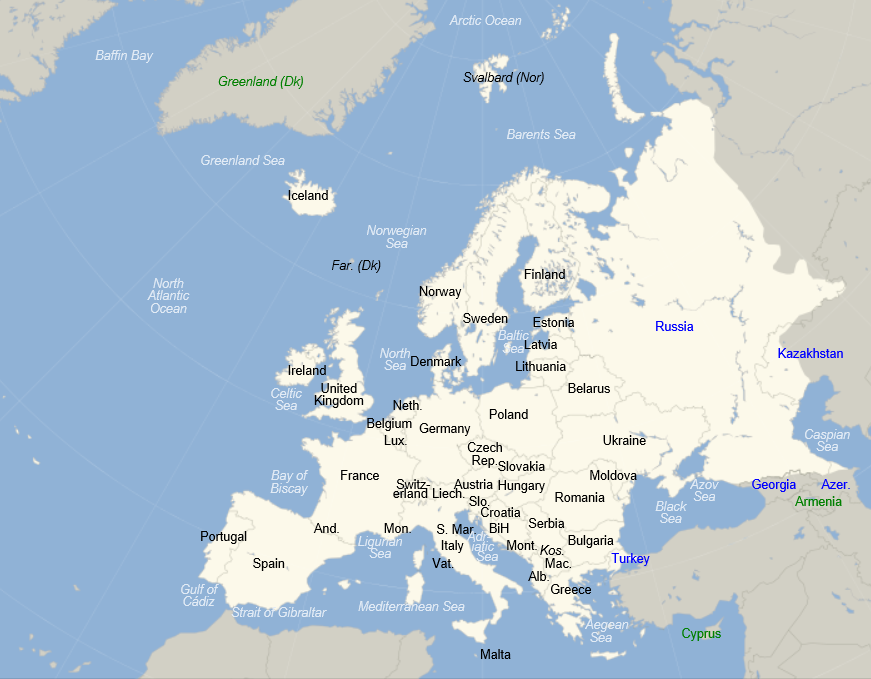
The European Union (EU) includes 28 countries, as follows with their date of entry in parenthesis:
Austria (1995), Belgium (1952), Bulgaria (2007), Croatia (2013), Cyprus (2004), Czech Republic (2004), Denmark (1973), Estonia (2004), Finland (1995), France (1952), Germany (1952), Greece (1981), Hungary (2004), Ireland (1973), Italy (1952), Latvia (2004), Lithuania (2004), Luxembourg (1952), Malta (2004), Netherlands (1952), Poland (2004), Portugal (1986), Romania (2007), Slovakia (2004), Slovenia (2004), Spain (1986), Sweden (1995), United Kingdom (1973).
The EU site states that –
The single or ‘internal’ market is the EU’s main economic engine, enabling most goods, services, money and people to move freely. Another key objective is to develop this huge resource to ensure that Europeans can draw the maximum benefit from it.
There also are governing bodies which are headquartered for the most part in Brussels and administrative structures.
The Eurozone consists of 18 European Union countries which have adopted the euro as their common currency. These countries includes Belgium, Germany, Estonia, Ireland, Greece, Spain, France, Italy, Cyprus, Latvia, Luxembourg, Malta, the Netherlands, Austria, Portugal, Slovenia, Slovakia and Finland.
The European Central Bank (ECB) is located in Frankfurt, Germany and performs a number of central bank functions, but does not clearly state its mandate on its website, so far as I can discover. The ECB has a governing council comprised of representatives from Eurozone banking and finance circles.
Economic Significance of Europe
Something like 160 out of the Global 500 Corporations identified by Fortune magazine are headquartered in Europe – and, of course, tax slides are moving more and more US companies to nominally move their operations to Europe.
According to the International Monetary Fund World Economic Outlook (July 14, 2013 update), the Eurozone accounts for an estimated 17 percent of global output, while the European Union countries comprise an estimated 24 percent of global output. By comparison the US accounts for 23 percent of global output, where all these percents are measured in terms of output in current US dollar equivalents.
What is the Problem?
I began engaging with Europe and its economic setup professionally, some years ago. The European market is important to information technology (IT) companies. Europe was a focus for me in 2008 and through the so-called Great Recession, when sharp drops in output occurred on both sides of the Atlantic. Then, after 2009 for several years, the impact of the global downturn continued to be felt in Europe, especially in the Eurozone, where there was alarm about the possible breakup of the Eurozone, defaults on sovereign debt, and massive banking failure.
I have written dozens of pages on European economic issues for circulation in business contexts. It’s hard to distill all this into a more current perspective, but I think the Greek economist Yanis Varoufakis does a fairly good job.
Let me cite two posts – WHY IS EUROPE NOT ‘COMING TOGETHER’ IN RESPONSE TO THE EURO CRISIS? and MODEST PROPOSAL.
The first quote highlights the problems (and lure) of a common currency to a weaker economy, such as Greece.
Right from the beginning, the original signatories of the Treaty of Rome, the founding members of the European Economic Community, constituted an asymmetrical free trade zone….
To see the significance of this asymmetry, take as an example two countries, Germany and Greece today (or Italy back in the 1950s). Germany, features large oligopolistic manufacturing sectors that produce high-end consumption as well as capital goods, with significant economies of scale and large excess capacity which makes it hard for foreign competitors to enter its markets. The other, Greece for instance, produces next to no capital goods, is populated by a myriad tiny firms with low price-cost margins, and its industry has no capacity to deter competitors from entering.
By definition, a country like Germany can simply not generate enough domestic demand to absorb the products its capital intensive industry can produce and must, thus, export them to the country with the lower capital intensity that cannot produce these goods competitively. This causes a chronic trade surplus in Germany and a chronic trade deficit in Greece.
If the exchange rate is flexible, it will inevitably adjust, constantly devaluing the currency of the country with the lower price-cost margins and revaluing that of the more capital-intensive economy. But this is a problem for the elites of both nations. Germany’s industry is hampered by uncertainty regarding how many DMs it will receive for a BMW produced today and destined to be sold in Greece in, say, ten months. Similarly, the Greek elites are worried by the devaluation of the drachma because, every time the drachma devalues, their lovely homes in the Northern Suburbs of Athens, or indeed their yachts and other assets, lose value relative to similar assets in London and Paris (which is where they like to spend their excess cash). Additionally, Greek workers despise devaluation because it eats into every small pay rise they manage to extract from their employers. This explains the great lure of a common currency to Greeks and to Germans, to capitalists and labourers alike. It is why, despite the obvious pitfalls of the euro, whole nations are drawn to it like moths to the flame.
So there is a problem within the Eurozone of “recycling trade surpluses” basically from Germany and the stronger members to peripheral countries such as Greece, Portugal, Ireland, and even Spain – where Italy is almost a special, but very concerning case.
The next quote is from a section in MODEST PROPOSAL called “The Nature of the Eurozone Crisis.” It is is about as succinct an overview of the problem as I know of – without being excessively ideological.
The Eurozone crisis is unfolding on four interrelated domains.
Banking crisis: There is a common global banking crisis, which was sparked off mainly by the catastrophe in American finance. But the Eurozone has proved uniquely unable to cope with the disaster, and this is a problem of structure and governance. The Eurozone features a central bank with no government, and national governments with no supportive central bank, arrayed against a global network of mega-banks they cannot possibly supervise. Europe’s response has been to propose a full Banking Union – a bold measure in principle but one that threatens both delay and diversion from actions that are needed immediately.
Debt crisis: The credit crunch of 2008 revealed the Eurozone’s principle of perfectly separable public debts to be unworkable. Forced to create a bailout fund that did not violate the no-bailout clauses of the ECB charter and Lisbon Treaty, Europe created the temporary European Financial Stability Facility (EFSF) and then the permanent European Stability Mechanism (ESM). The creation of these new institutions met the immediate funding needs of several member-states, but retained the flawed principle of separable public debts and so could not contain the crisis. One sovereign state, Cyprus, has now de facto gone bankrupt, imposing capital controls even while remaining inside the euro.
During the summer of 2012, the ECB came up with another approach: the Outright Monetary Transactions’ Programme (OMT). OMT succeeded in calming the bond markets for a while. But it too fails as a solution to the crisis, because it is based on a threat against bond markets that cannot remain credible over time.
And while it puts the public debt crisis on hold, it fails to reverse it; ECB bond purchases cannot restore the lending power of failed markets or the borrowing power of failing governments.
Investment crisis: Lack of investment in Europe threatens its living standards and its international competitiveness. As Germany alone ran large surpluses after 2000, the resulting trade imbalances ensured that when crisis hit in 2008, the deficit zones would collapse. And the burden of adjustment fell exactly on the deficit zones, which could not bear it. Nor could it be offset by devaluation or new public spending, so the scene was set for disinvestment in the regions that needed investment the most.
Thus, Europe ended up with both low total investment and an even more uneven distribution of that investment between its surplus and deficit regions.
Social crisis: Three years of harsh austerity have taken their toll on Europe’s peoples. From Athens to Dublin and from Lisbon to Eastern Germany, millions of Europeans have lost access to basic goods and dignity. Unemployment is rampant. Homelessness and hunger are rising. Pensions have been cut; taxes on necessities meanwhile continue to rise. For the first time in two generations, Europeans are questioning the European project, while nationalism, and even Nazi parties, are gaining strength.
This is from a white paper jointly authored by Yanis Varoufakis, Stuart Holland and James K. Galbraith which offers a rationale and proposal for a European “New Deal.” In other words, take advantage of the record low global interest rates and build infrastructure.
The passage covers quite a bit of ground without appearing to be comprehensive. However, it will be be a good guide to check, I think, if a significant downturn unfolds in the next few quarters. Some of the nuances will come to life, as flaws in original band-aid solutions get painfully uncovered.
Now there is no avoiding some type of ideological or political stance in commenting on these issues, but the future is the real question. What will happen if a recession takes hold in the next few quarters?
More on European Banks
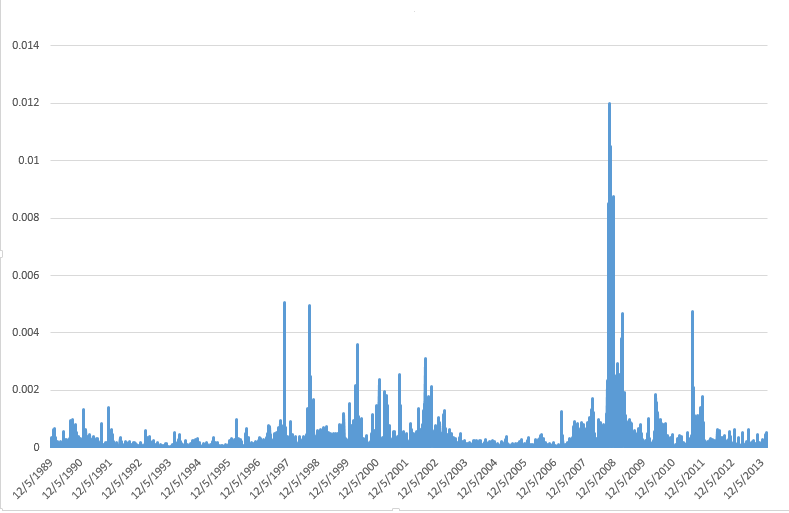
European banks have been significantly under-capitalized, as the following graphic from before the Great Recession highlights.
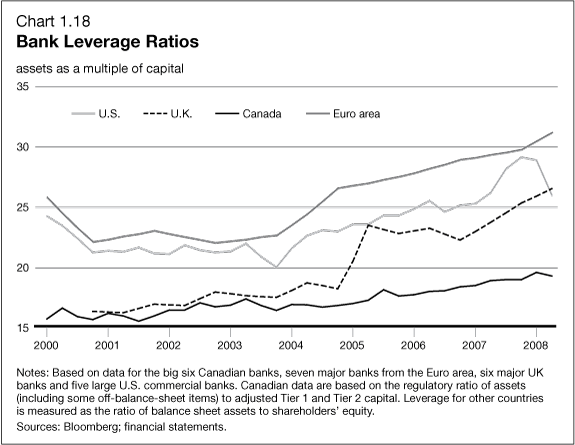
Another round of stress tests are underway by the ECB, and, according to the Wall Street Journal, will be shared with banks in coming weeks. Significant recapitalization of European banks, often through stock issues, has taken place. Things have moved forward from the point at which, last year, the US Federal Deposit Insurance Corporation (FDIC) Vice Chairman called Deutsche Banks capitalization ratios “horrible,” “horribly undercapitalized” and with “no margin of error.”
Bottom LIne
If a recession unfolds in the next few quarters, it is likely to significantly impact the European economy, opening up old wounds, so to speak, wounds covered with band-aid solutions. I know I have not proven this assertion in this post, but it is a message I want to convey.
The banking sector is probably where the problems will first flare up, since banks have significant holdings of sovereign debt from EU states that already are on the ropes – like Greece, Spain, Portugal, and Italy. There also appears to be some evidence of froth in some housing markets, with record low interest rates and the special conditions in the UK.
Hopefully, the global economy can side-step this current wobble from the first quarter 2014 and maybe even further in some quarters, and somehow sustain positive or at least zero growth for a few years.
Otherwise, this looks like a house of cards.