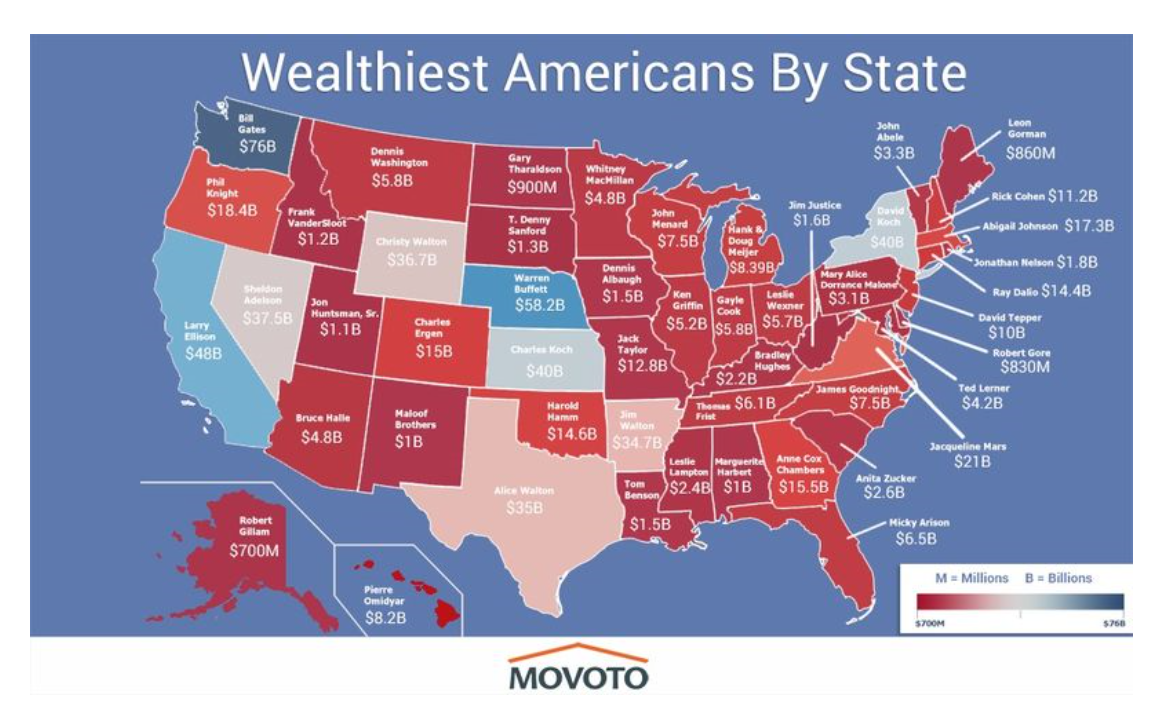
After highlighting billionaires by state, I focus on data analytics and marketing, and then IT in these links. Enjoy!
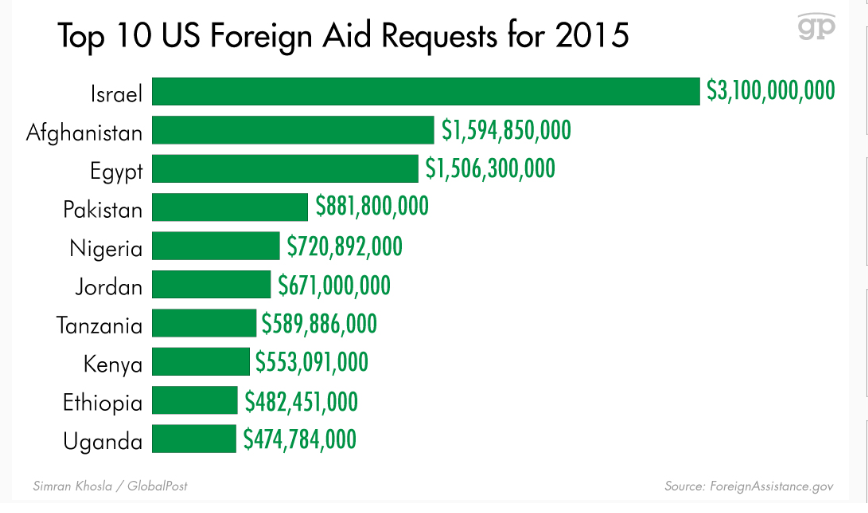
The Wealthiest Individual In Every State [Map]
Data Analytics and Marketing
Has your company, for example, developed a customer lifetime value (CLTV) measure? That’s using predictive analytics to determine how much a customer will buy from the company over time. Do you have a “next best offer” or product recommendation capability? That’s an analytical prediction of the product or service that your customer is most likely to buy next. Have you made a forecast of next quarter’s sales? Used digital marketing models to determine what ad to place on what publisher’s site? All of these are forms of predictive analytics.
Making sense of Google Analytics audience data
Earlier this year, Google added Demographics and Interest reports to the Audience section of Google Analytics (GA). Now not only can you see how many people are visiting your site, but how old they are, whether they’re male or female, what their interests are, and what they’re in the market for.
Data Visualization, Big Data, and the Quest for Better Decisions – a Synopsis
Simon uses Netflix as a prime example of a company that gets data and its use “to promote experimentation, discovery, and data-informed decision-making among its people.”….
They know a lot about their customers.
For example, the company knows how many people binge-watched the entire season four of Breaking Bad the day before season five came out (50,000 people). The company therefore can extrapolate viewing patterns for its original content produced to appeal to Breaking Bad fans. Moreover, Netflix markets the same show differently to different customers based on whether their viewing history suggests they like the director or one of the stars….
The crux of their analytics is the visualization of “what each streaming customer watches, when, and on what devices, but also at what points shows are paused and resumed (or not) and even the color schemes of the marketing graphics to which individuals respond.”
Formulate a hypothesis to be tested. Determine specific objectives for the test. Make a prediction, even if it is just a wild guess, as to what should happen. Then execute in a way that enables you to accurately measure your prediction…Then involve a dispassionate outsider in the process, ideally one who has learned through experience how to handle decisions with imperfect information…..Avoid considering an idea in isolation. In the absence of choice, you will almost always be able to develop a compelling argument about why to proceed with an innovation project. So instead of asking whether you should invest in a specific project, ask if you are more excited about investing in Project X versus other alternatives in your innovation portfolio…And finally, ensure there is some kind of constraint forcing a decision.
Information Technology (IT)
5 Reasons why Wireless Charging Never Caught on
Charger Bundling, Limited handsets, Time, Portability, and Standardisation – interesting case study topic for IT
Why Jimmy the Robot Means New Opportunities for IT
While Jimmy was created initially for kids, the platform is actually already evolving to be a training platform for everyone. There are two versions: one at $1,600, which really is more focused on kids, and one at $16,000, for folks like us who need a more industrial-grade solution. The Apple I wasn’t just for kids and neither is Jimmy. Consider at least monitoring this effort, if not embracing it, so when robots go vertical you have the skills to ride this wave and not be hit by it.

Beyond the Reality Distortion Field: A Sober Look at Apple Pay
.. Apple Pay could potentially kick-start the mobile payment business the way the iPod and iTunes launched mobile music 13 years ago. Once again, Apple is leveraging its powerful brand image to bring disparate companies together all in the name of consumer convenience.
From Dr. 4Ward How To Influence And Persuade (click to enlarge)