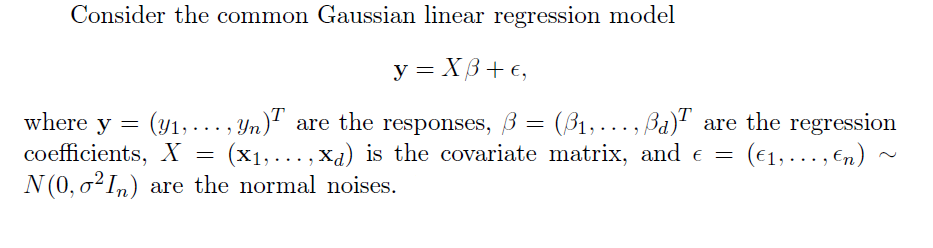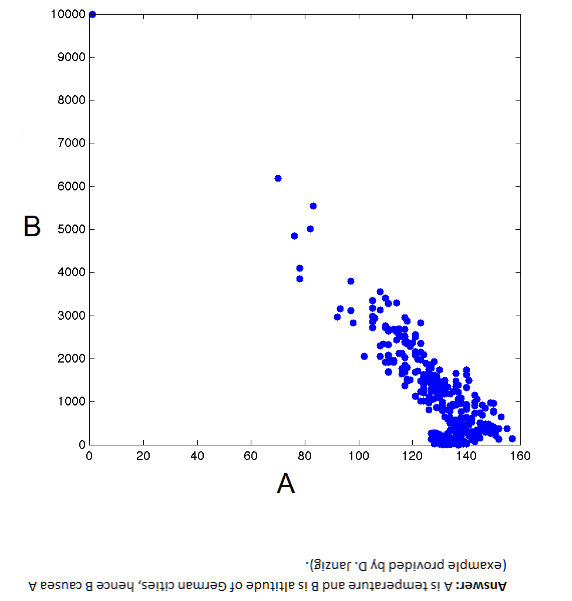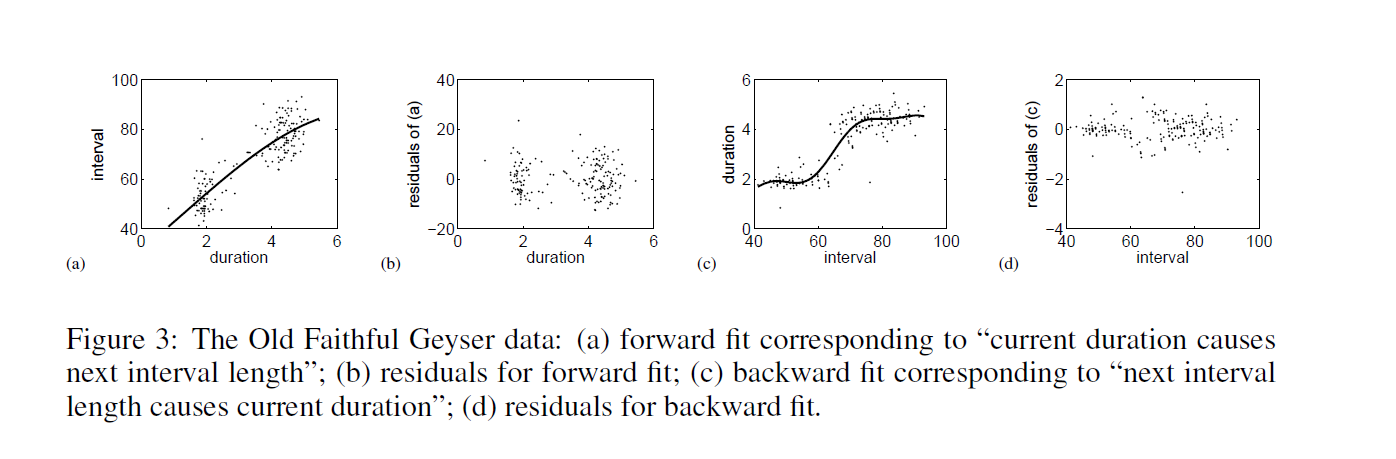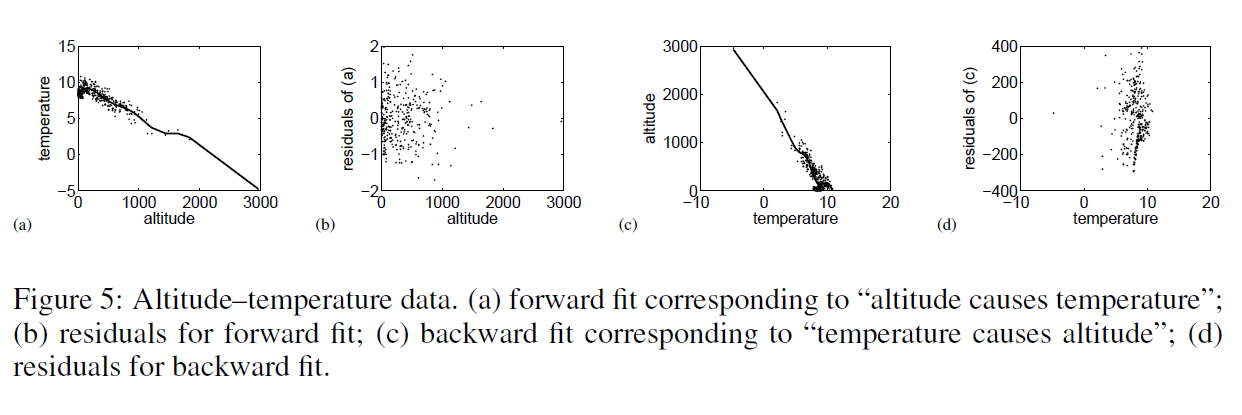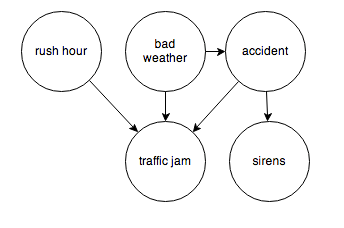
I’ve run across outstanding summaries of “partial least squares” (PLS) research recently – for example Rosipal and Kramer’s Overview and Recent Advances in Partial Least Squares and the 2010 Handbook of Partial Least Squares.
Partial least squares (PLS) evolved somewhat independently from related statistical techniques, owing to what you might call family connections. The technique was first developed by Swedish statistician Herman Wold and his son, Svante Wold, who applied the method in particular to chemometrics. Rosipal and Kramer suggest that the success of PLS in chemometrics resulted in a lot of applications in other scientific areas including bioinformatics, food research, medicine, [and] pharmacology..
Someday, I want to look into “path modeling” with PLS, but for now, let’s focus on the comparison between PLS regression and principal component (PC) regression. This post develops a comparison with Matlab code and macroeconomics data from Mark Watson’s website at Princeton.
The Basic Idea Behind PC and PLS Regression
Principal component and partial least squares regression share a couple of features.
Both, for example, offer an approach or solution to the problem of “many predictors” and multicollinearity. Also, with both methods, computation is not transparent, in contrast to ordinary least squares (OLS). Both PC and PLS regression are based on iterative or looping algorithms to extract either the principal components or underlying PLS factors and factor loadings.
PC Regression
The first step in PC regression is to calculate the principal components of the data matrix X. This is a set of orthogonal (which is to say completely uncorrelated) vectors which are weighted sums of the predictor variables in X.
This is an iterative process involving transformation of the variance-covariance or correlation matrix to extract the eigenvalues and eigenvectors.
Then, the data matrix X is multiplied by the eigenvectors to obtain the new basis for the data – an orthogonal basis. Typically, the first few (the largest) eigenvalues – which explain the largest proportion of variance in X – and their associated eigenvectors are used to produce one or more principal components which are regressed onto Y. This involves a dimensionality reduction, as well as elimination of potential problems of multicollinearity.
PLS Regression
The basic idea behind PLS regression, on the other hand, is to identify latent factors which explain the variation in both Y and X, then use these factors, which typically are substantially fewer in number than k, to predict Y values.
Clearly, just as in PC regression, the acid test of the model is how it performs on out-of-sample data.
The reason why PLS regression often outperforms PC regression, thus, is that factors which explain the most variation in the data matrix may not, at the same time, explain the most variation in Y. It’s as simple as that.
Matlab example
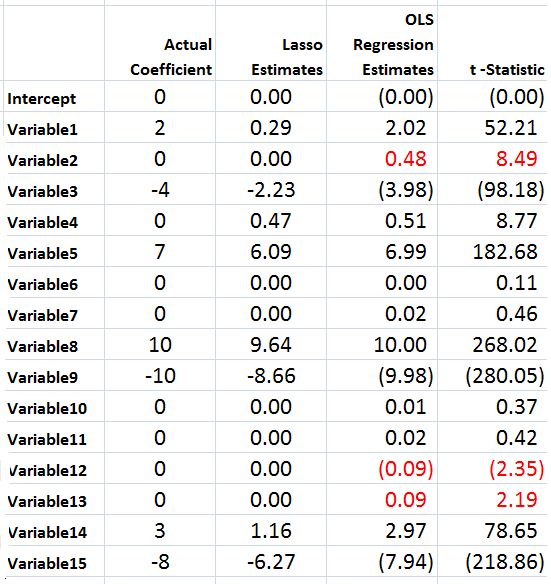
I grabbed some data from Mark Watson’s website at Princeton — from the links to a recent paper called Generalized Shrinkage Methods for Forecasting Using Many Predictors (with James H. Stock), Journal of Business and Economic Statistics, 30:4 (2012), 481-493.Download Paper (.pdf). Download Supplement (.pdf), Download Data and Replication Files (.zip). The data include the following variables, all expressed as year-over-year (yoy) growth rates: The first variable – real GDP – is taken as the forecasting target. The time periods of all other variables are lagged one period (1 quarter) behind the quarterly values of this target variable.

Matlab makes calculation of both principal component and partial least squares regressions easy.
The command to extract principal components is
[coeff, score, latent]=princomp(X)
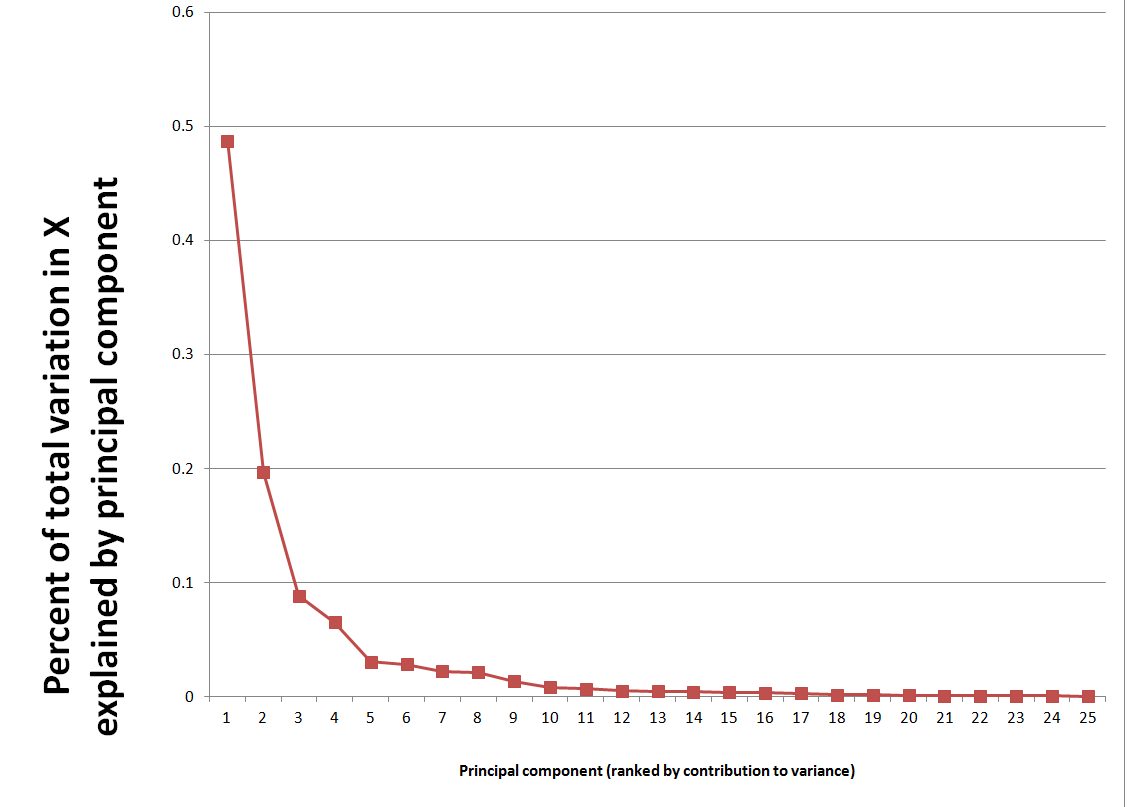
Here X the data matrix, and the entities in the square brackets are vectors or matrices produced by the algorithm. It’s possible to compute a principal components regression with the contents of the matrix score. Generally, the first several principal components are selected for the regression, based on the importance of a component or its associated eigenvalue in latent. The following scree chart illustrates the contribution of the first few principal components to explaining the variance in X.
The relevant command for regression in Matlab is
b=regress(Y,score(:,1:6))
where b is the column vector of estimated coefficients and the first six principal components are used in place of the X predictor variables.
The Matlab command for a partial least square regresssion is
[XL,YL,XS,YS,beta] = plsregress(X,Y,ncomp)
where ncomp is the number of latent variables of components to be utilized in the regression. There are issues of interpreting the matrices and vectors in the square brackets, but I used this code –
data=xlsread(‘stock.xls’); X=data(1:47,2:79); y = data(2:48,1);
[XL,yl,XS,YS,beta] = plsregress(X,y,10); yfit = [ones(size(X,1),1) X]*beta;
lookPLS=[y yfit]; ZZ=data(48:50,2:79);newy=data(49:51,1);
new=[ones(3,1) ZZ]*beta; out=[newy new];
The bottom line is to test the estimates of the response coefficients on out-of-sample data.
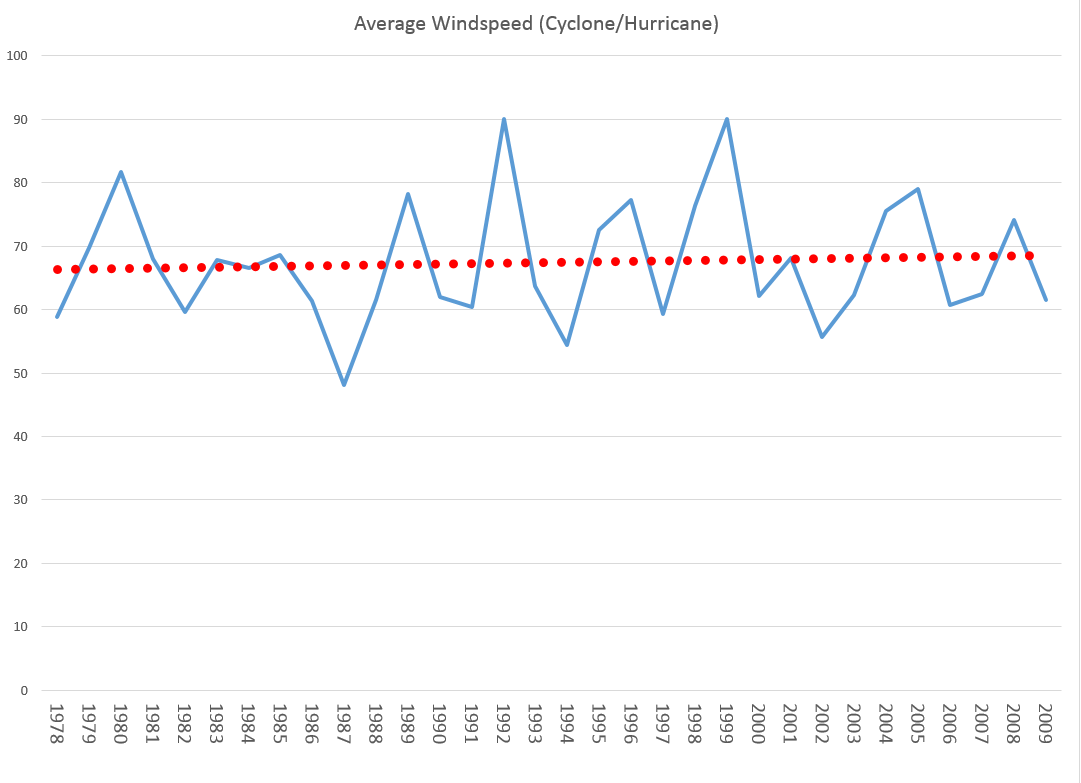
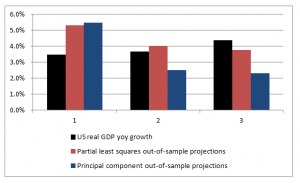
The following chart shows that PLS outperforms PC, although the predictions of both are not spectacularly accurate.
Commentary
There are nuances to what I have done which help explain the dominance of PLS in this situation, as well as the weakly predictive capabilities of both approaches.
First, the target variable is quarterly year-over-year growth of real US GDP. The predictor set X contains 78 other macroeconomic variables, all expressed in terms of yoy (year-over-year) percent changes.
Again, note that the time period of all the variables or observations in X are lagged one quarter from the values in Y, or the values or yoy quarterly percent growth of real US GDP.
This means that we are looking for a real, live leading indicator. Furthermore, there are plausibly common factors in the Y series shared with at least some of the X variables. For example, the percent changes of a block of variables contained in real GDP are included in X, and by inspection move very similarly with the target variable.
Other Example Applications
There are at least a couple of interesting applied papers in the Handbook of Partial Least Squares – a downloadable book in the Springer Handbooks of Computational Statistics. See –
Chapter 20 A PLS Model to Study Brand Preference: An Application to the Mobile Phone Market
Chapter 22 Modeling the Impact of Corporate Reputation on Customer Satisfaction and Loyalty Using Partial Least Squares
Another macroeconomics application from the New York Fed –
“Revisiting Useful Approaches to Data-Rich Macroeconomic Forecasting”
http://www.newyorkfed.org/research/staff_reports/sr327.pdf
Finally, the software company XLStat has a nice, short video on partial least squares regression applied to a marketing example.