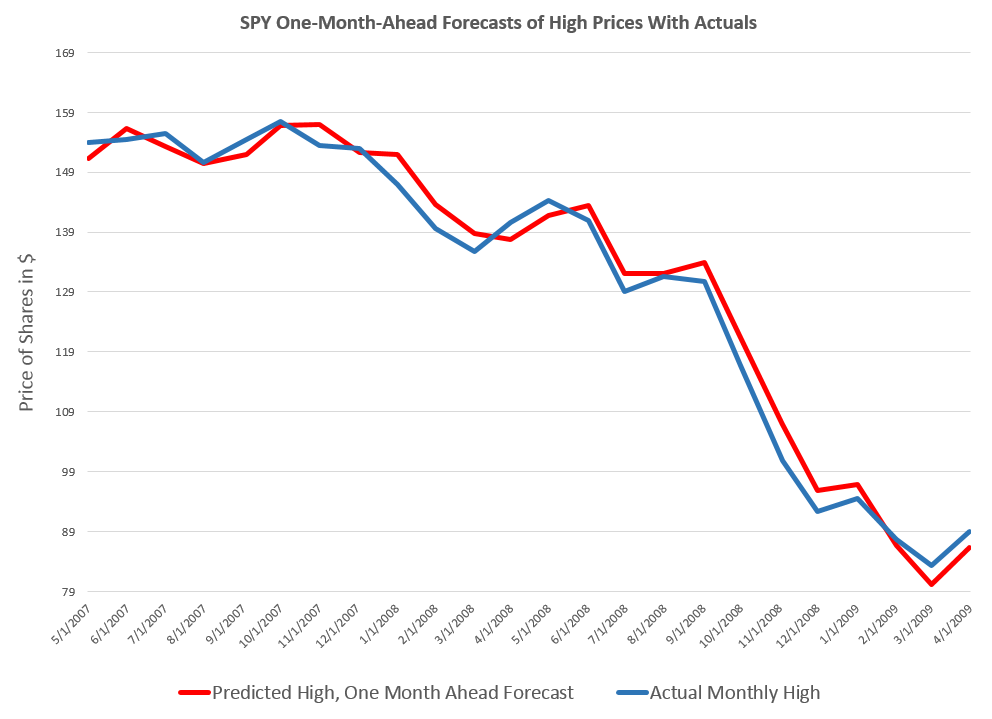
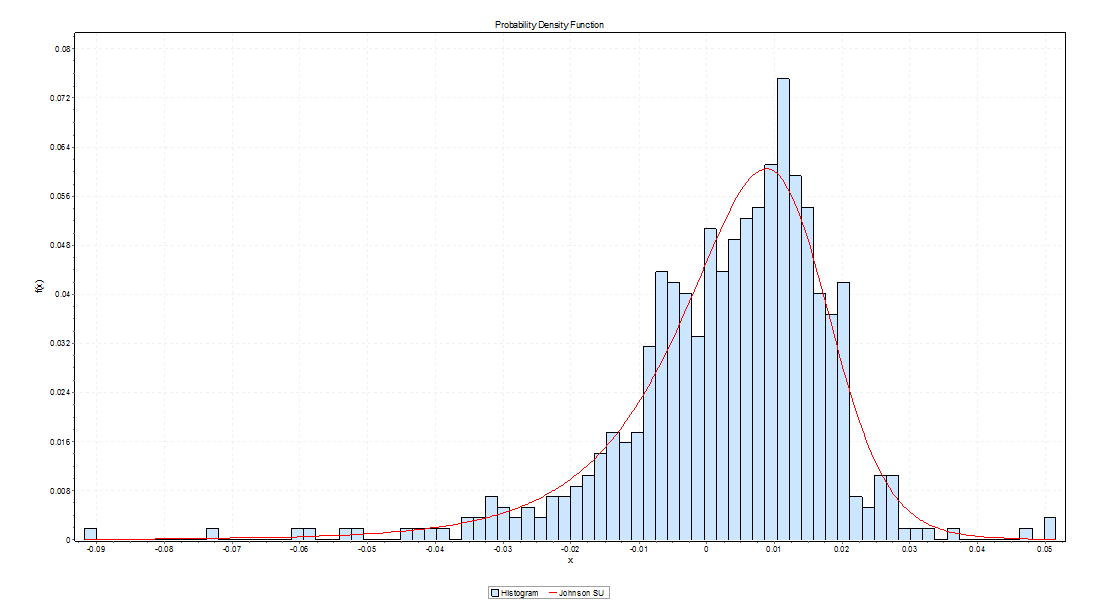
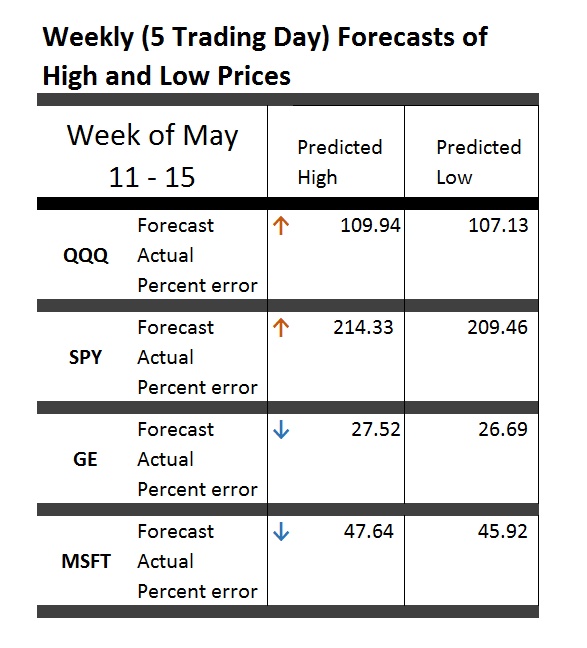
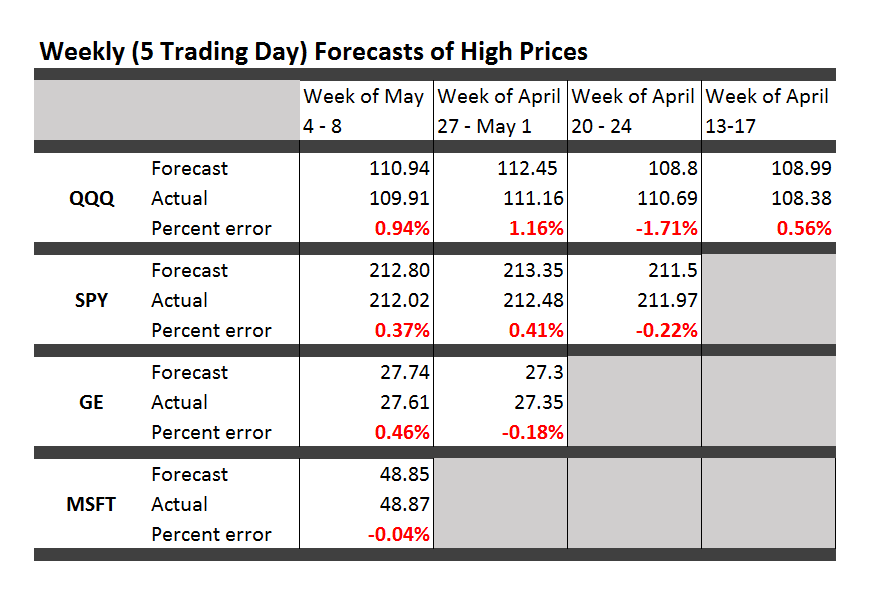
A rational bubble exists when investors are willing to pay more for stocks than is justified by the discounted stream of future dividends. If investors evaluate potential gains from increases in the stock price as justifying movement away from the “fundamental value” of the stock – a self-reinforcing process of price increases can take hold, but be consistent with “rational expectations.”
This concept has been around for a while, and can be traced to eminences such as Oliver Blanchard, now Chief Economist for the International Monetary Fund (IMF), and Mark Watson, Professor of Economics at Princeton University – (See Bubbles, Rational Expectations and Financial Markets).
In terms of formal theory, Diba and Grossman offer a sophisticated analysis in The Theory of Rational Bubbles in Stock Prices. They invoke intriguing language such as “explosive conditional expectations” and the like.
Since these papers from the 1980’s, the relative size of the financial sector has ballooned, and valuation of derivatives now dwarfs totals for annual value of production on the planet (See Bank for International Settlements).
And, in the US, we have witnessed two, dramatic stock market bubbles, here using the phrase in a more popular “plain-as-the-hand-in-front-of-your-face” sense.
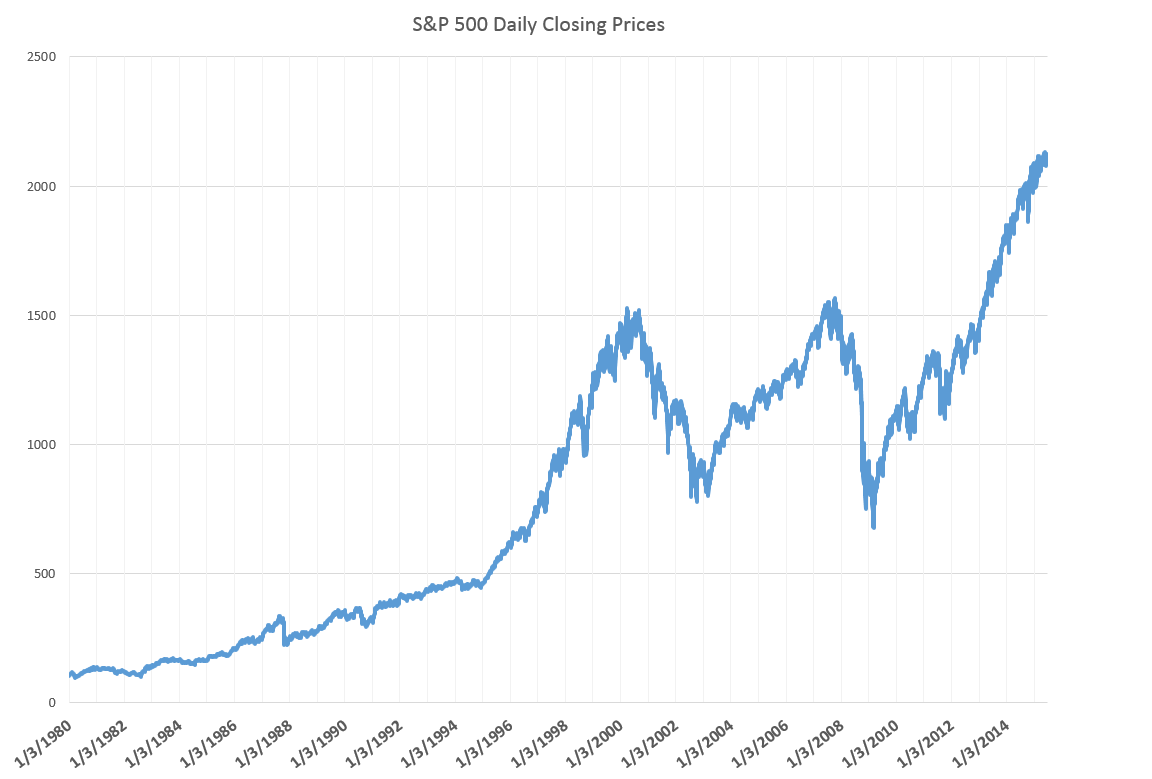
Following through the metaphor, bursting of the bubble leaves financial plans in shambles, and, from the evidence of parts of Europe at least, can cause significant immiseration of large segments of the population.
It would seem reasonable, therefore, to institute some types of controls, as a bubble was emerging. Perhaps an increase in financial transactions taxes, or some other tactic to cause investors to hold stocks for longer periods.
The question, then, is whether it is possible to “test” for a rational bubble pre-emptively or before-the-fact.
So I have been interested recently to come on more recent analysis of so-called rational bubbles, applying advanced statistical techniques.
I offer some notes and links to download the relevant papers.
These include ground-breaking work by Craine in a working paper Rational Bubbles: A Test.
Then, there are two studies focusing on US stock prices (I include extracts below in italics):
Testing for a Rational Bubble Under Long Memory
We analyze the time series properties of the S&P500 dividend-price ratio in the light of long memory, structural breaks and rational bubbles. We find an increase in the long memory parameter in the early 1990s by applying a recently proposed test by Sibbertsen and Kruse (2009). An application of the unit root test against long memory by Demetrescu et al. (2008) suggests that the pre-break data can be characterized by long memory, while the post-break sample contains a unit root. These results reconcile two empirical findings which were seen as contradictory so far: on the one hand they confirm the existence of fractional integration in the S&P500 log dividend-price ratio and on the other hand they are consistent with the existence of a rational bubble. The result of a changing memory parameter in the dividend-price ratio has an important implication for the literature on return predictability: the shift from a stationary dividend-price ratio to a unit root process in 1991 is likely to have caused the well-documented failure of conventional return prediction models since the 1990s.
The bubble component captures the part of the share price that is due to expected future price changes. Thus, the price contains a rational bubble, if investors are ready to pay more for the share, than they know is justified by the discounted stream of future dividends. Since they expect to be able to sell the share even at a higher price, the current price, although exceeding the fundamental value, is an equilibrium price. The model therefore allows the development of a rational bubble, in the sense that a bubble is fully consistent with rational expectations. In the rational bubble model, investors are fully cognizant of the fundamental value, but nevertheless they may be willing to pay more than this amount… This is the case if expectations of future price appreciation are large enough to satisfy the rational investor’s required rate of return. To sustain a rational bubble, the stock price must grow faster than dividends (or cash flows) in perpetuity and therefore a rational bubble implies a lack of cointegration between the stock price and fundamentals, i.e. dividends, see Craine (1993).
Testing for rational bubbles in a co-explosive vector autoregression
We derive the parameter restrictions that a standard equity market model implies for a bivariate vector autoregression for stock prices and dividends, and we show how to test these restrictions using likelihood ratio tests. The restrictions, which imply that stock returns are unpredictable, are derived both for a model without bubbles and for a model with a rational bubble. In both cases we show how the restrictions can be tested through standard chi-squared inference. The analysis for the no-bubble case is done within the traditional Johansen model for I(1) variables, while the bubble model is analysed using a co-explosive framework. The methodology is illustrated using US stock prices and dividends for the period 1872-2000.
The characterizing feature of a rational bubble is that it is explosive, i.e. it generates an explosive root in the autoregressive representation for prices.
This is a very interesting analysis, but involves several stages of statistical testing, all of which is somewhat dependent on assumptions regarding underlying distributions.
Finally, it is interesting to see some of these methodologies for identifying rational bubbles applied to other markets, such as housing, where “fundamental value” has a somewhat different and more tangible meaning.
Explosive bubbles in house prices? Evidence from the OECD countries
We conduct an econometric analysis of bubbles in housing markets in the OECD area, using quarterly OECD data for 18 countries from 1970 to 2013. We pay special attention to the explosive nature of bubbles and use econometric methods that explicitly allow for explosiveness. First, we apply the univariate right-tailed unit root test procedure of Phillips et al. (2012) on the individual countries price-rent ratio. Next, we use Engsted and Nielsen’s (2012) co-explosive VAR framework to test for bubbles. Wefind evidence of explosiveness in many housing markets, thus supporting the bubble hypothesis. However, we also find interesting differences in the conclusions across the two test procedures. We attribute these differences to how the two test procedures control for cointegration between house prices and rent.