
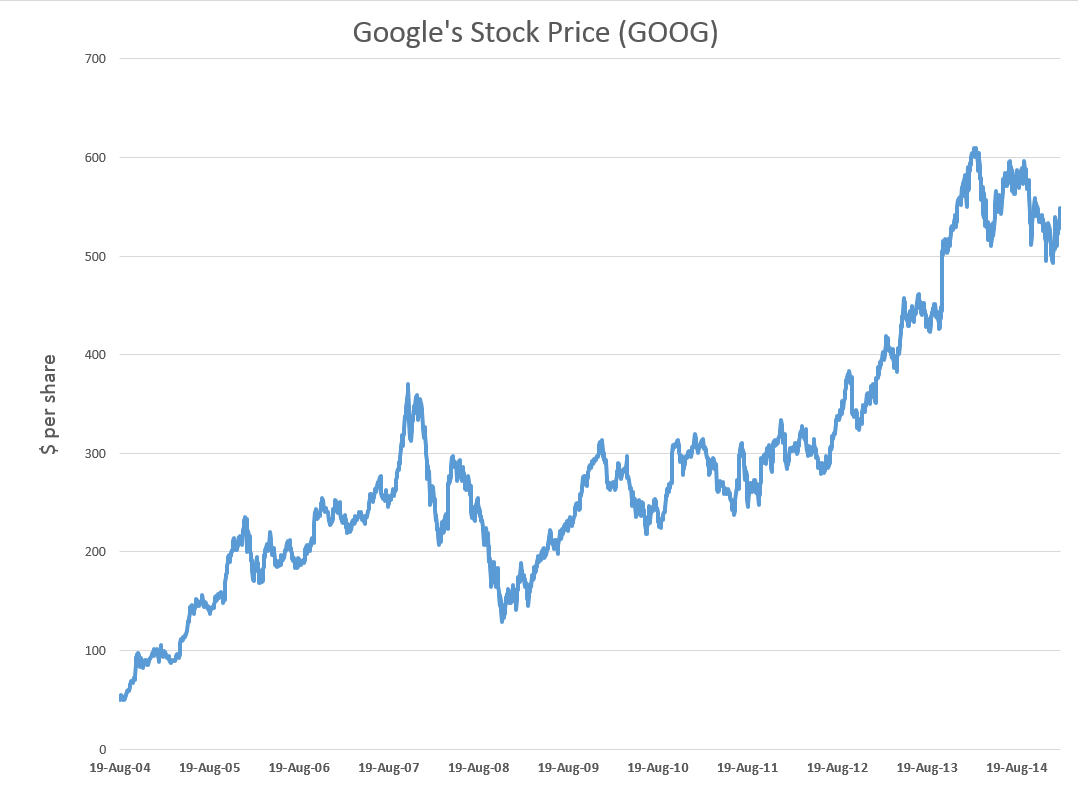
Google’s stock price (GOOG) is relatively volatile, as the following chart shows.
So it’s interesting that a stock market forecasting algorithm can produce the following 20 Trading-Day-Ahead forecasts for GOOG, for the recent period.
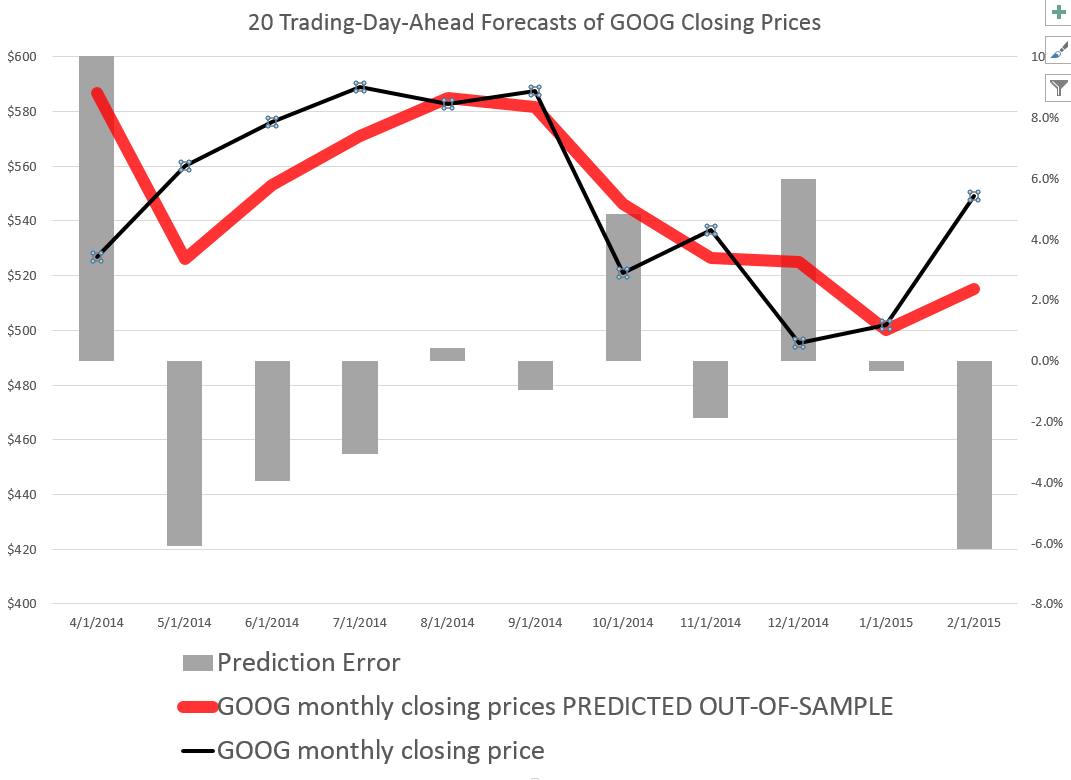
The forecasts in the above chart, as are those mentioned subsequently, are out-of-sample predictions. That is, the parameters of the forecast model – which I call the PVar model – are estimated over one set of historic prices. Then, the forecasts from PVar are generated with values for the explanatory variables that are “outside” or not the same as this historic data.
How good are these forecasts and how are they developed?
Well, generally forecasting algorithms are compared with benchmarks, such as an autoregressive model or a “no-change” forecast.
So I constructed an autoregressive (AR) model for the Google closing prices, sampled at 20 day frequencies. This model has ten lagged versions of the closing price series, so I do not just rely here on first order autocorrelations.
Here is a comparison of the 20 trading-day-ahead predictions of this AR model, the above “proximity variable” (PVar) model which I take credit for, and the actual closing prices.
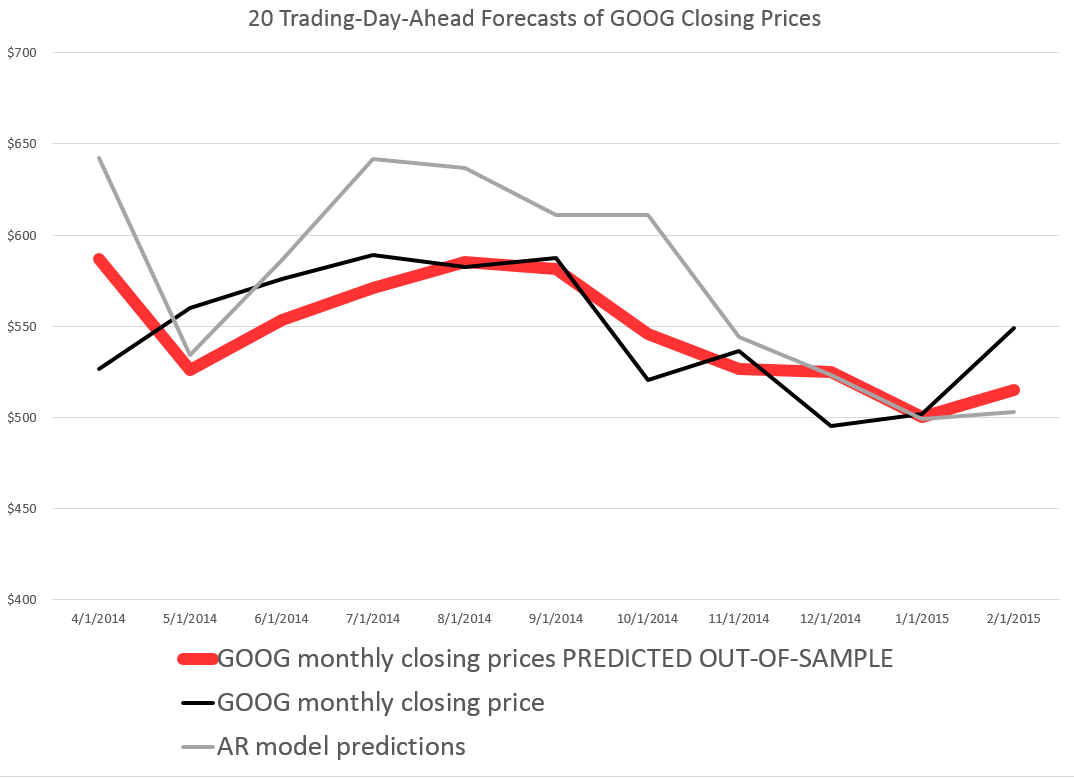
As you can see, the AR model is worse in comparison to the PVar model, although they share some values at the end of the forecast series.
The mean absolute percent errors (MAPE) of the AR model for a period more extended than shown in the graph is 7.0, compared with 5.1 for PVar. This comparison is calculated over data from 4/20/2011.
So how do I do it?
Well, since these models show so much promise, it makes sense to keep working on them, making improvements. However, previous posts here give broad hints, indeed pretty well laying out the framework, at least on an introductory basis.
Essentially, I move from predicting highs and lows to predicting closing prices.
To predict highs and lows, my post “further research” states
Now, the predictive models for the daily high and low stock price are formulated, as before, keying off the opening price in each trading day. One of the key relationships is the proximity of the daily opening price to the previous period high. The other key relationship is the proximity of the daily opening price to the previous period low. Ordinary least squares (OLS) regression models can be developed which do a good job of predicting the direction of change of the daily high and low, based on knowledge of the opening price for the day.
Other posts present actual regression models, although these are definitely prototypes, based on what I know now.
Why Does This Work?
I’ll bet this works because investors often follow simple rules such as “buy when the opening price is sufficiently greater than the previous period high” or “sell, if the opening price is sufficiently lower than the previous period low.”
I have assembled evidence, based on time variation in the predictive coefficients of the PVar variables, which I probably will put out here sometime.
But the point is that momentum trading is a major part of stock market activity, not only in the United States, but globally. There’s even research claiming to show that momentum traders do better than others, although that’s controversial.
This means that the daily price record for a stock, the opening, high, low, and closing prices, encode information that investors are likely to draw upon over different investing horizons.
I’m pleased these insights open up many researchable questions. I predict all this will lead to wholly new generations of models in stock market analysis. And my guess, and so far it is largely just that, is that these models may prove more durable than many insights into patterns of stock market prices – due to a sort of self-confirming aspect.