
Research by Lin, Wu, and Zhou in Predictability of Corporate Bond Returns: A Comprehensive Study suggests a radical change in perspective, based on new forecasting methods. The research seems to me to of a piece with a lot of developments in Big Data and the data mining movement generally. Gains in predictability are associated with more extensive databases and new techniques.
The abstract to their white paper, presented at various conferences and colloquia, is straight-forward –
Using a comprehensive data set, we find that corporate bond returns not only remain predictable by traditional predictors (dividend yields, default, term spreads and issuer quality) but also strongly predictable by a new predictor formed by an array of 26 macroeconomic, stock and bond predictors. Results strongly suggest that macroeconomic and stock market variables contain important information for expected corporate bond returns. The predictability of returns is of both statistical and economic significance, and is robust to different ratings and maturities.
Now, in a way, the basic message of the predictability of corporate bond returns is not news, since Fama and French made this claim back in 1989 – namely that default and term spreads can predict corporate bond returns both in and out of sample.
What is new is the data employed in the Lin, Wu, and Zhou (LWZ) research. According to the authors, it involves 780,985 monthly observations spanning from January 1973 to June 2012 from combined data sources, including Lehman Brothers Fixed Income (LBFI), Datastream, National Association of Insurance Commissioners (NAIC), Trade Reporting and Compliance Engine (TRACE) and Mergents Fixed Investment Securities Database (FISD).
There also is a new predictor which LWZ characterize as a type of partial least squares (PLS) formulation, but which is none other than the three pass regression filter discussed in a post here in March.
The power of this PLS formulation is evident in a table showing out-of-sample R2 of the various modeling setups. As in the research discussed in a recent post, out-of-sample (OS) R2 is a ratio which measures the improvement in mean square prediction errors (MSPE) for the predictive regression model over the historical average forecast. A negative OS R2 thus means that the MSPE of the benchmark forecast is less than the MSPE of the forecast by the designated predictor formulation.
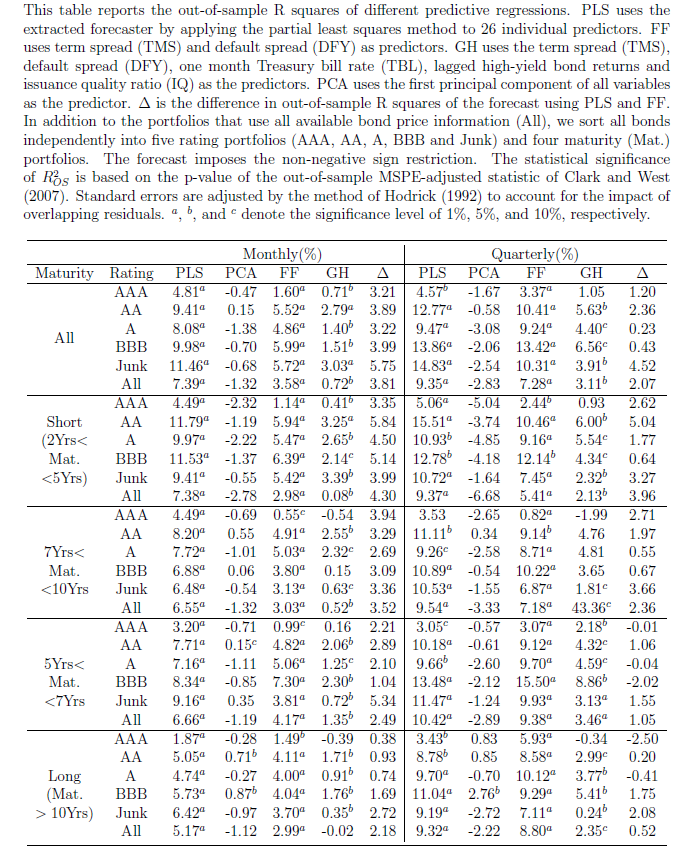
Again, this research finds predictability varies with economic conditions – and is higher during economic downturns.
There are cross-cutting and linked studies here, often with Goyal’s data and fourteen financial/macroeconomic variables figuring within the estimations. There also is significant linkage with researchers at regional Federal Reserve Banks.
My purpose in this and probably the next one or two posts is to just get this information out, so we can see the larger outlines of what is being done and suggested.
My guess is that the sum total of this research is going to essentially re-write financial economics and has huge implications for forecasting operations within large companies and especially financial institutions.