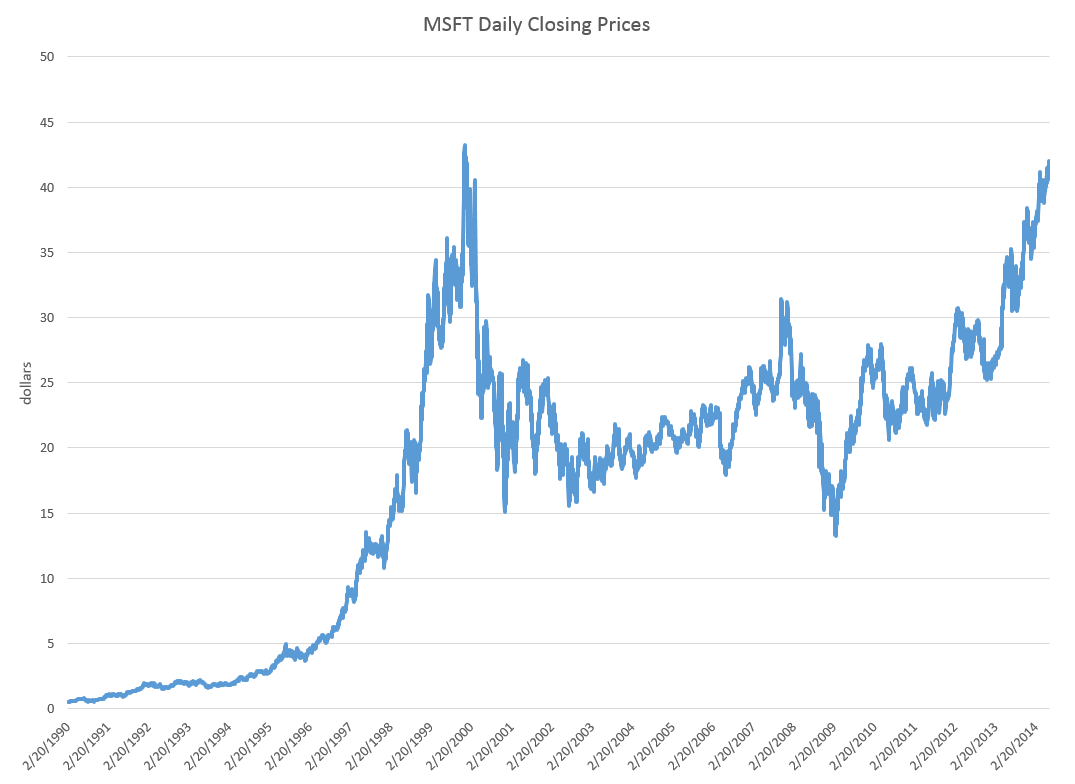
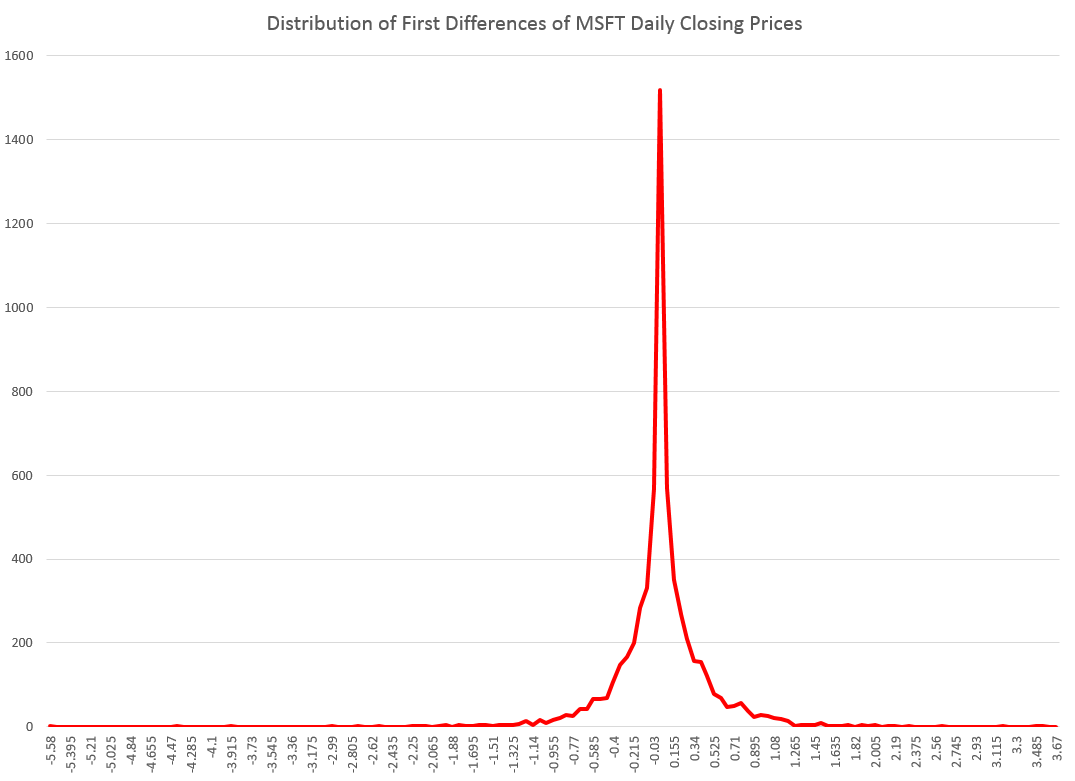
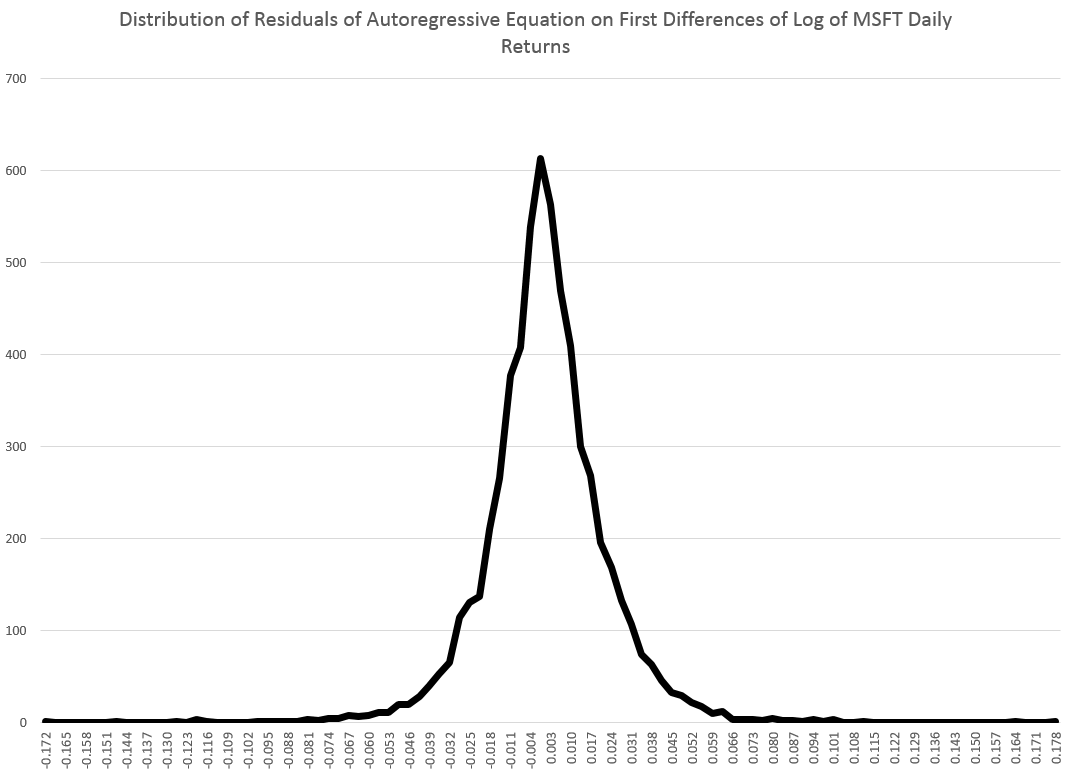
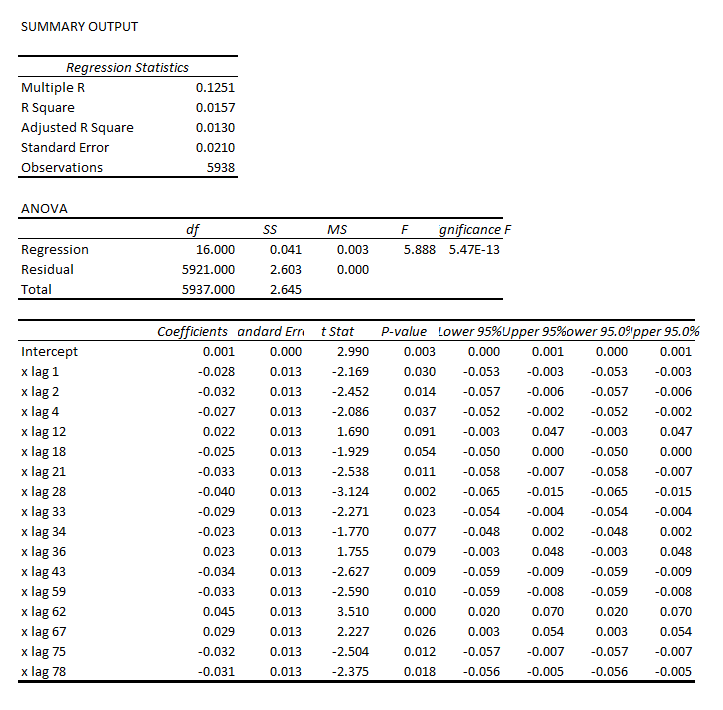
Well, it’s the first day of the 3rd quarter 2014, and time to make an assessment of what happened in Q2 and also what is likely to transpire the rest of the year.
The Big Write-Down
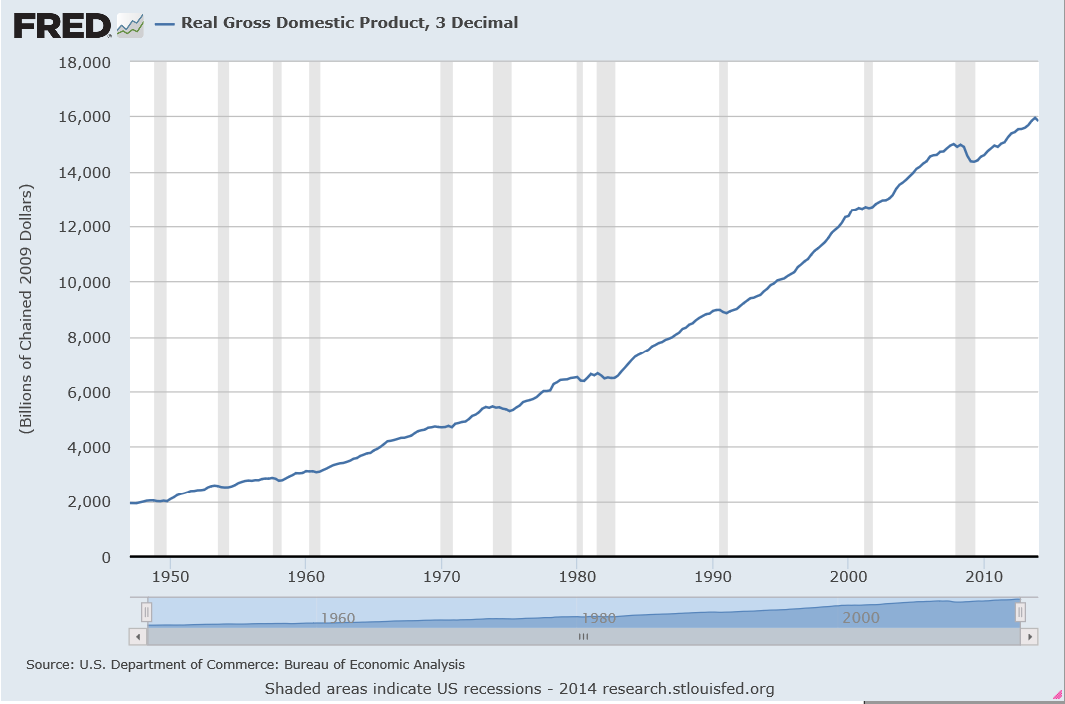
Of course, the 1st quarter 2014 numbers were surprisingly negative – and almost no one saw that coming. Last Wednesday (June 25) the Bureau of Economic Analysis (BEA) revised last estimates of 1st quarter real GDP down a -2.9 percent decrease on a quarter-by-quarter basis.
The Accelerating Growth Meme
Somehow media pundits and the usual ranks of celebrity forecasters seem heavily invested in the “accelerating growth” meme in 2014.
Thus, in mid-June Mark Zandi of Moody’s tries to back up Moody’s Analytics U.S. Macro Forecast calling for accelerating growth the rest of the year, writing,
The economy’s strength is increasingly evident in the job market. Payroll employment rose to a new high in May as the U.S. finally replaced all of the 8.7 million jobs lost during the recession, and job growth has accelerated above 200,000 per month since the start of the year. The pace of job creation is almost double that needed to reduce unemployment, even with typical labor force gains. More of the new positions are also better paying than was the case earlier in the recovery.
After the BEA released its write-down numbers June 25, the Canadian Globe and Mail put a happy face on everything, writing that The US Economy is Back on Track since,
Hiring, retail sales, new-home construction and consumer confidence all rebounded smartly this spring. A separate government report Wednesday showed inventories for non-defense durable goods jumped 1 per cent in May after a 0.4-per-cent increase the previous month.
Forecasts for the Year Being Cut-Back
On the other hand, the International Monetary Fund (IMF) cut its forecast for US growth,
In its annual review of the U.S. economy, the IMF cut its forecast for U.S. economic growth this year by 0.8 percentage point to 2%, citing a harsh winter, a struggling housing market and weak international demand for the country’s products.
Some Specifics
The first thing to understand in this context is that employment is usually a lagging indicator of the business cycle. Ahead of the Curve makes this point dramatically with the following chart.
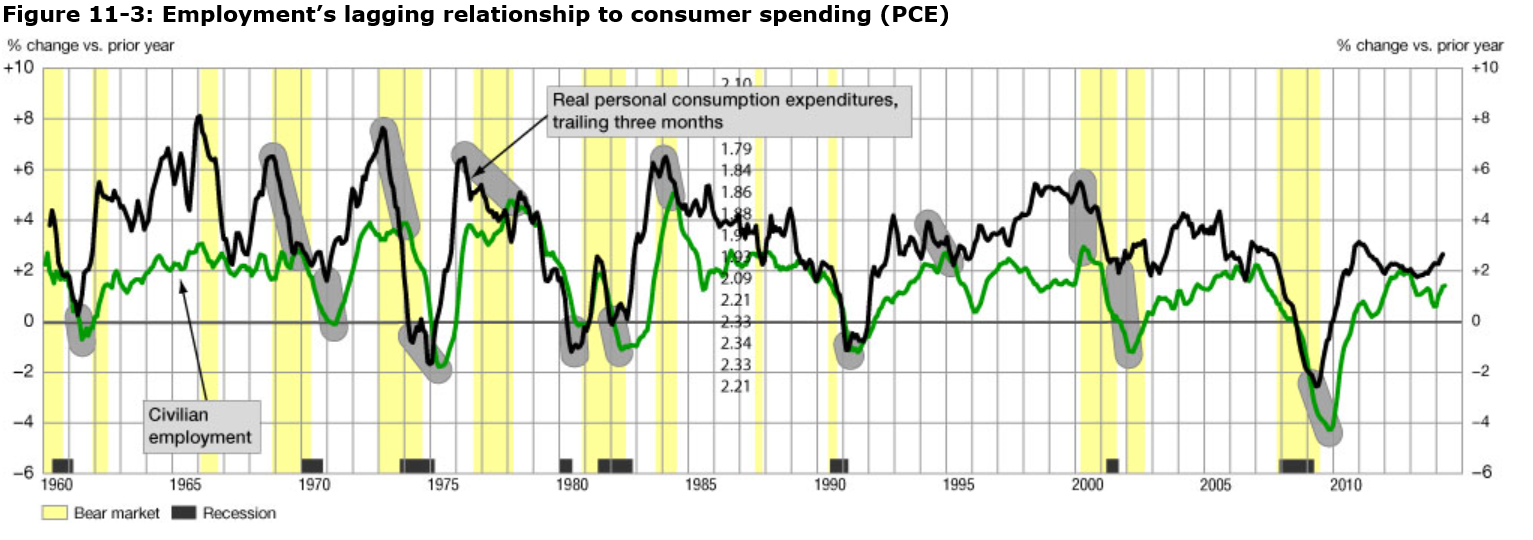
The chart shows employment change and growth lag changes in the business cycle. Thus, note that the green line peaks after growth in personal consumption expenditures in almost every case, where these growth rates are calculated on a year-over-year basis.
So Zandi’s defense of the Moody’s Analytics accelerating growth forecast for the rest of 2014 has to be taken with a grain of salt.
It really depends on other things – whether for example, retail sales are moving forward, what’s happening in the housing market (to new-home construction and other variables), also to inventories and durable goods spending. Also have exports rebounded, and imports (a subtraction from GDP) been reined in?
Retail Sales
If there is going to be accelerating economic growth, consumer demand, which certainly includes retail sales, has to improve dramatically.
However, the picture is mixed with significant rebound in sales in April, but lower-than-expected retail sales growth in May.
Bloomberg’s June take on this is in an article Cooling Sales Curb Optimism on U.S. Growth Rebound: Economy.
The US Census report estimates U.S. retail and food services sales for May, adjusted for seasonal variation and holiday and trading-day differences, but not for price changes, were $437.6 billion, an increase of 0.3 percent (±0.5)* from the previous month.
Durable Goods Spending
In the Advance Report on Durable Goods Manufacturers’ Shipments, Inventories and Orders May 2014 we learn that,
New orders for manufactured durable goods in May decreased $2.4 billion or 1.0 percent to $238.0 billion, the U.S. Census Bureau announced today.
On the other hand,
Shipments of manufactured durable goods in May, up four consecutive months, increased $0.6 billion or 0.3 percent to $238.6 billion
Of course, shipments are a lagging indicator of the business cycle.
Finally, inventories are surging –
Inventories of manufactured durable goods in May, up thirteen of the last fourteen months, increased $3.8 billion or 1.0 percent to $397.8 billion. This was at the highest level since the series was first published on a NAICS basis and followed a 0.3 percent April increase.
Inventory accumulation is a coincident indicator (in a negative sense) of the business cycle, according to NBER documents.
New Home Construction
From the Joint Release U.S. Department of Housing and Urban Development,
Privately-owned housing units authorized by building permits in May were at a seasonally adjusted annual rate of 991,000. This is 6.4 percent (±0.8%) below the revised April rate of 1,059,000 and is 1.9 percent (±1.4%) below the May 2013 estimate of 1,010,000…
Privately-owned housing starts in May were at a seasonally adjusted annual rate of 1,001,000. This is 6.5 percent (±10.2%)* below the
revised April estimate of 1,071,000, but is 9.4 percent (±11.0%)* above the May 2013 rate of 915,000.
Single-family housing starts in May were at a rate of 625,000; this is 5.9 percent (±12.7%)* below the revised April figure of 664,000.
No sign of a rebound in new home construction in these numbers.
Exports and Imports
The latest BEA report estimates,
April exports were $0.3 billion less than March exports of $193.7 billion. April imports were $2.7 billion more than March imports of $237.8 billion…
Here is a several month perspective.
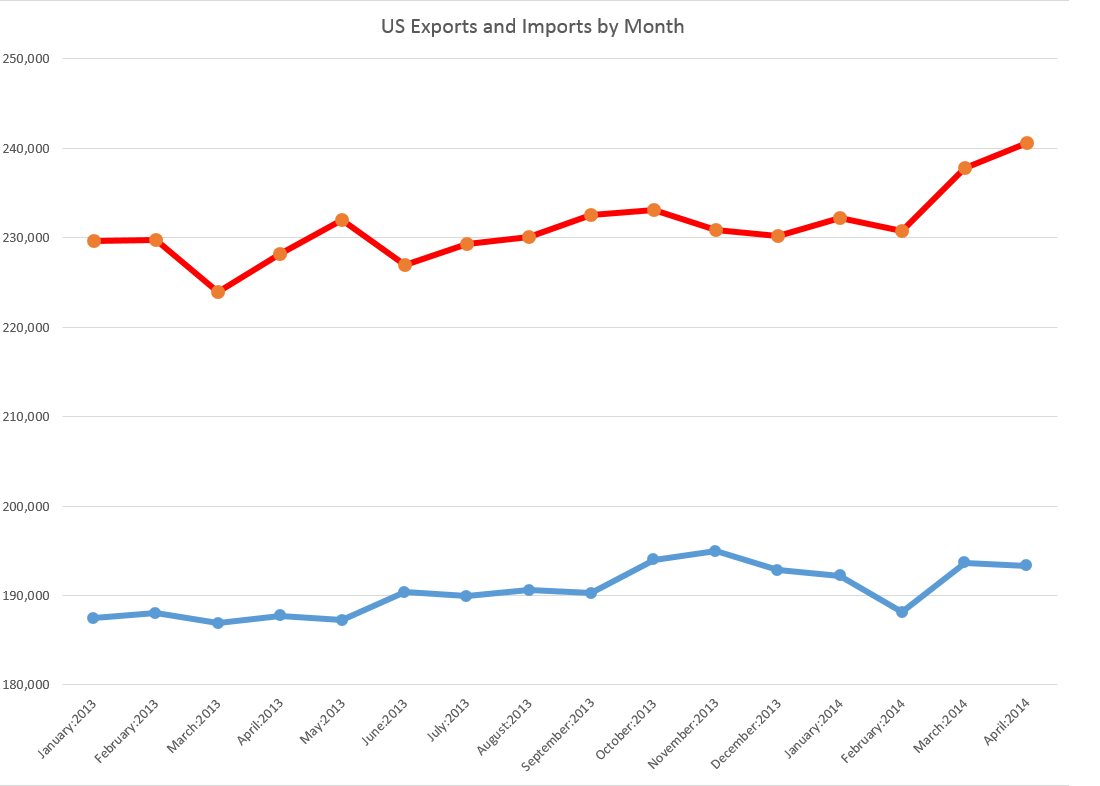
Essentially, the BEA trade numbers suggest the trade balance deteriorated March to April with a sharp uptick in imports and a slight drop in exports.
Summary
Well, it’s not a clear picture. The economy is teetering on the edge of a downturn, which it may still escape.
Clearly, real growth in Q2 has to be at least 2.9 percent in order to counterbalance the drop in Q1, or else the first half of 2014 will show a net decrease.
CNN offers this with an accompanying video –
Goldman Sachs economists trimmed second quarter tracking GDP to 3.5 percent from 4.1 percent, and Barclays economists said tracking GDP for the second quarter fell to 2.9 percent from 4 percent. At a pace below 3 percent, the economy could show contraction for the first half due to the steep first quarter decline of 2.9 percent.
top picture http://www.bbc.com/news/magazine-24045598