
By some lights, predicting the stock market is the ultimate challenge. Tremendous resources are dedicated to it – pundits on TV, specialized trading programs, PhD’s doing high-end quantitative analysis in hedge funds. And then, of course, theories of “rational expectations” and “efficient markets” deny the possibility of any consistent success at stock market prediction, on grounds that stock prices are basically random walks.
I personally have not dabbled much in forecasting the market, until about two months ago, when I grabbed a bunch of data on the S&P 500 and tried some regressions with lags on S&P 500 daily returns and daily returns from the VIX volatility index.
What I discovered is completely replicable, and also, so far as I can see, is not widely known.
An autoregressive time series model of S&P 500 or SPY daily returns, built with data from 1993 to early 2008, can outperform a Buy & Hold strategy initiated with out-of-sample data beginning January 2008 and carrying through to recent days.
Here is a comparison of cumulative gains from a Buy & Hold strategy initiated January 23, 2008 with a Trading Strategy informed by my autoregressive (AR) model.
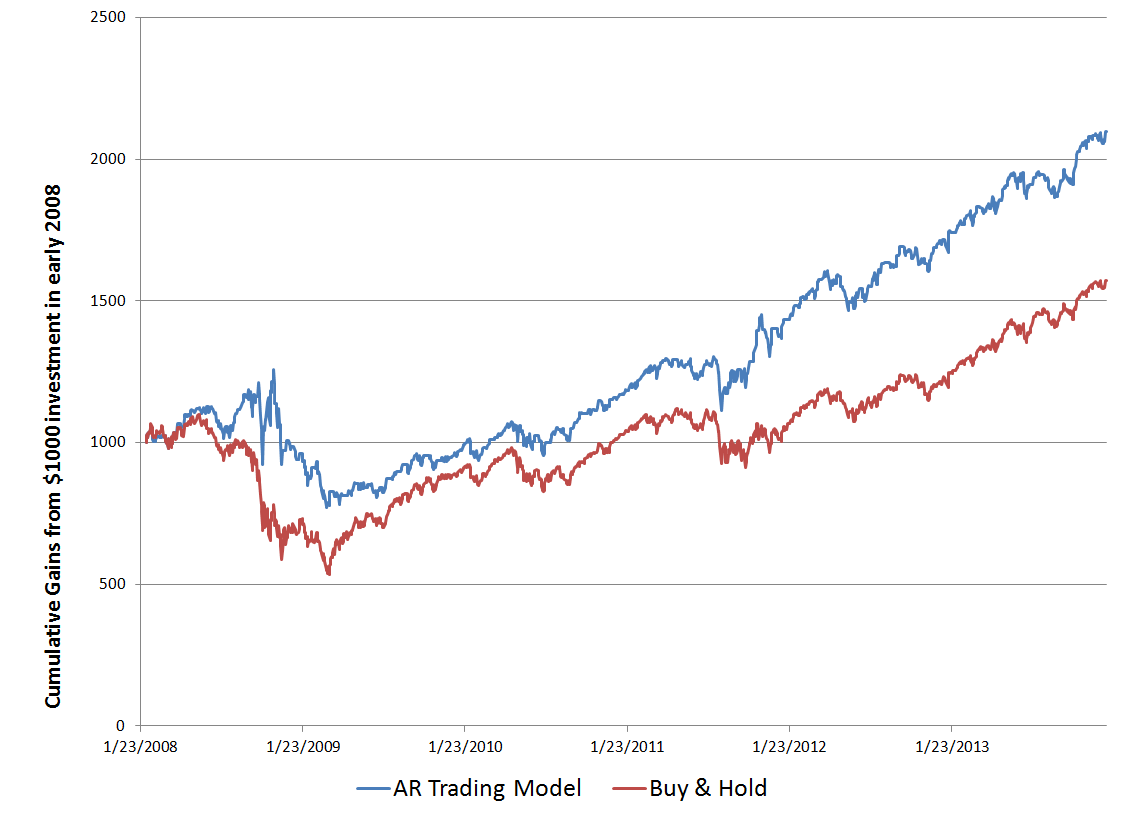
So, reading this chart, investing $1000 January 23, 2008 and not touching this investment leads to cumulative returns of $1586.84 – that’s the Buy & Hold strategy.
The AR trading model, however, generates cumulative returns over this period of $2097.
The trading program based on the autoregressive model I am presenting here works like this. The AR model predicts the next day return for the SPY, based on the model coefficients (which I detail below) and the daily returns through the current day. So, if there is an element of unrealism, it is because the model is based on the daily returns computed on closing values day-by-day. But, obviously, you have to trade before the closing bell (in standard trading), so you need to use a estimate of the current day’s closing value obtained very close to the bell, before deciding whether to invest, sell, or buy SPY for the next day’s action.
But basically, assuming we can do this, perhaps seconds before the bell, and come close to an estimate of the current day closing price – the AR trading program is to buy SPY if the next day’s return is predicted to be positive – or if you currently hold SPY, to continue holding it. If the next day’s return is predicted to be negative, you sell your holdings.
It’s as simple as that.
So the AR model predicts daily returns on a one-day-ahead basis, using information on daily returns through the current trading day, plus the model coefficients.
Speaking of which, here are the coefficients from the Matlab “printout.”
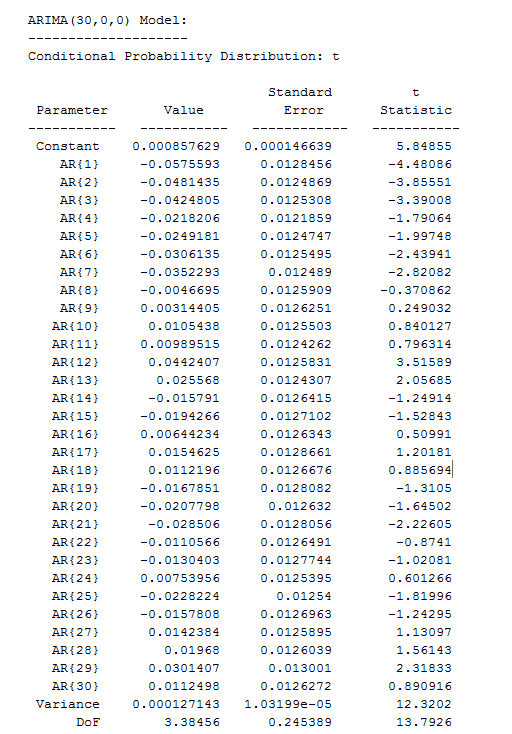
There are a couple of nuances here. First, these parameter values do not derive from an ordinary least squares (OLS) regression. Instead, they are produced by maximum likelihood estimation, assuming the underlying distribution is a t-distribution (not a Gaussian distribution).
The use of a t-distribution, the idea of which I got to some extent from Nassim Taleb’s new text-in-progress mentioned two posts ago, is motivated by the unusual distribution of residuals of an OLS regression of lagged daily returns.
The proof is in the pudding here, too, since the above coefficients work better than ones developed on the (manifestly incorrect) assumption that the underlying error distribution is Gaussian.
Here is a graph of the 30-day moving averages of the proportion of signs of daily returns correctly predicted by this model.
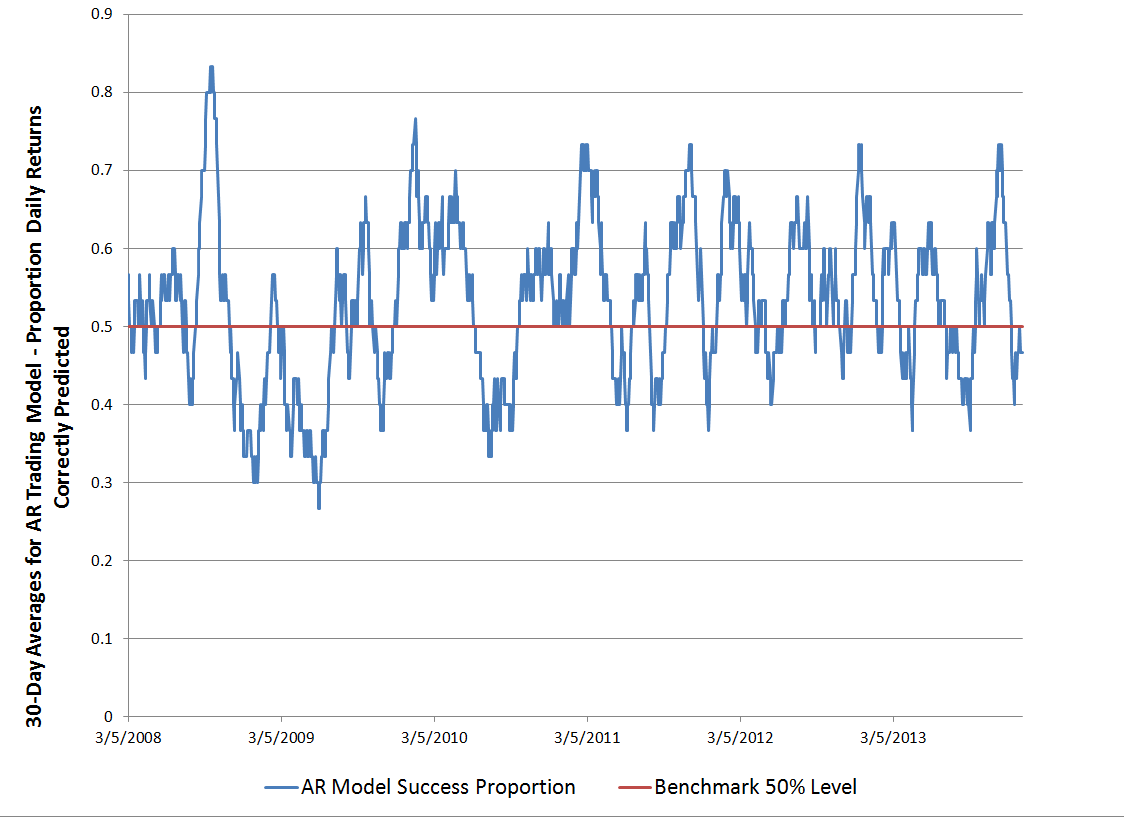
Overall, about 53 percent of the signs of the daily returns in this out-of-sample period are predicted correctly.
If you look at this graph, too, it’s clear there are some differences in performance over this period. Thus, the accuracy of the model took a dive in 2009, in the depths of the Great Recession. And, model performance achieved significantly higher success proportions in 2012 and early 2013, perhaps related to markets getting used to money being poured in by the Fed’s policies of quantitative easing.
Why This AR Model is Such a Big Deal
I find it surprising that a set of fixed coefficients applied to the past 30 values of the SPY daily returns continue to predict effectively, months and years after the end of the in-sample values.
And, I might add, it’s not clear that updating the AR model always improves the outcomes, although I can do more work on this and also on the optimal sample period generally.
Can this be a matter of pure chance? This has to be considered, but I don’t think so. Monte Carlo simulations of randomized trading indicate that there is a 95 percent chance or better than returns of $2097 in this period are not due to chance. In other words, if I decide to trade on a day based on a flip of a fair coin, heads I buy, tails I sell at the end of the day, it’s highly unlikely I will generate cumulative returns of $2097, given the SPY returns over this period.
The performance of this trading model holds up fairly well through December of last year, but degrades some in the first days of 2014.
I think this is a feather in the cap of forecasting, so to speak. Also, it seems to me that economists promoting ideas of market efficiency and rational expectations need to take these findings into account. Everything is extant. I have provided the coefficients. You can get the SPY daily return values from Yahoo Finance. You can calculate everything yourself to check. I’ve done this several times, slightly differently each time. This time I used Matlab, and its arima estimation procedures work well.
I’m not quite sure what to make of all this, but I think it’s important. Naturally, I am extending these results in my personal model-building, and I can report that extensions are possible. At the same time, no extension of this model I have seen achieves more than nearly 60 percent accuracy in predicting the direction of change or sign of the daily returns, so you are going to lose money sometimes applying these models. Day-trading is a risky business.
Interesting but you seem to forget transaction costs.
Also, you could add a model on the residual volatility (garch or egarch) since the volatility of the market is not constant
Hey thanks for the comment. Actually, I deduct $5 a trade in the revised model, so transaction costs are included, although I don’t make that clear in the post.