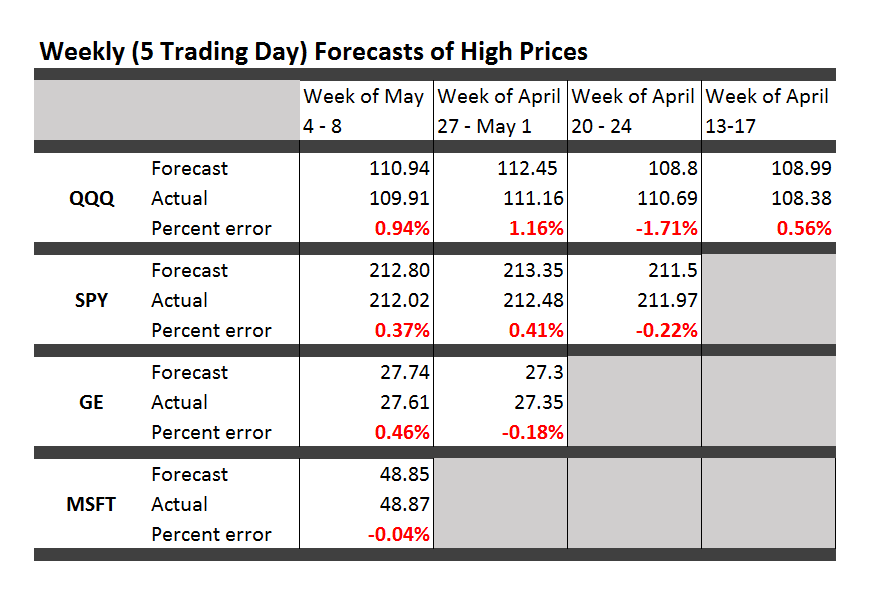
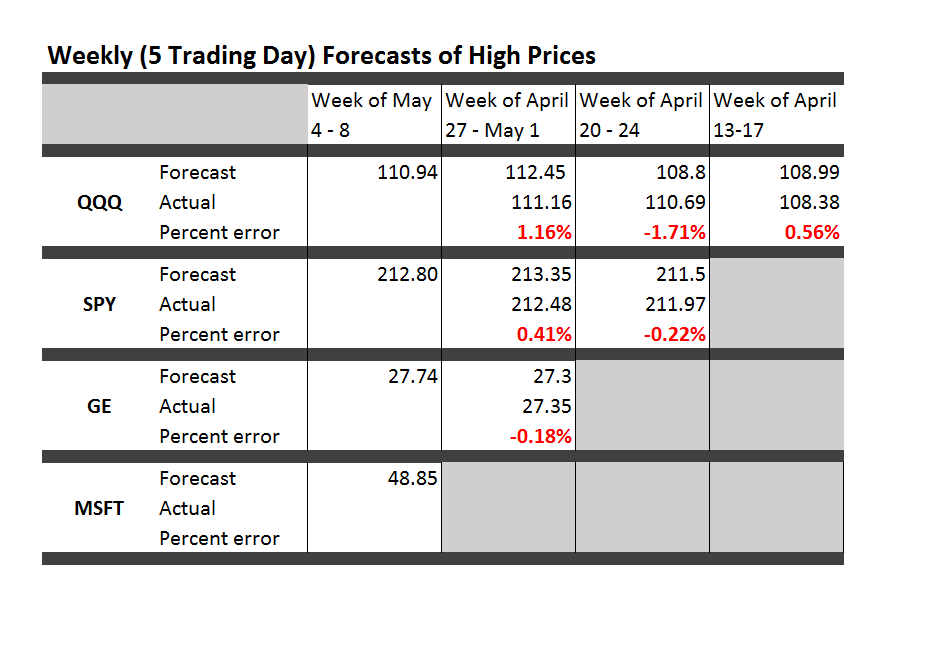
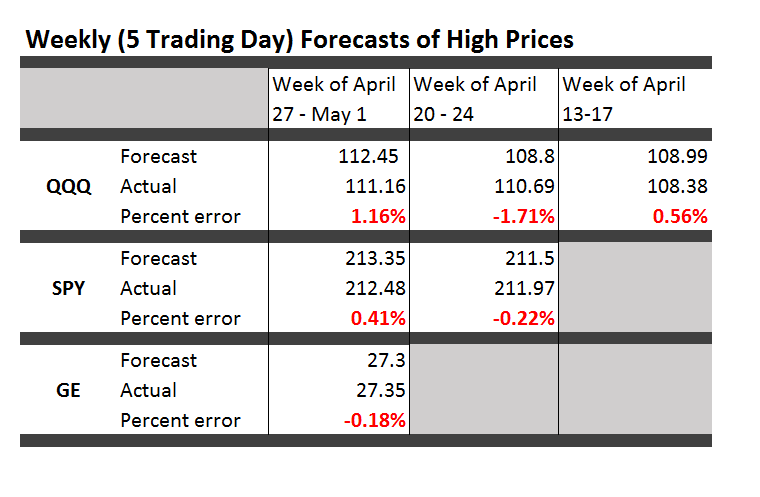
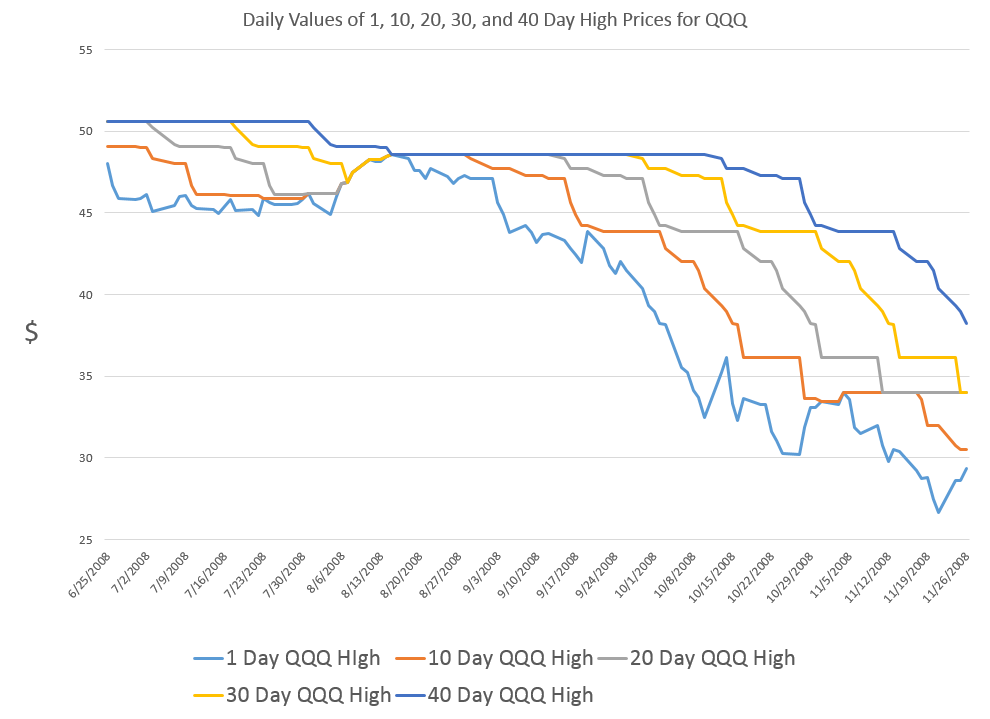
Teaching economics during Vietnam and, later, the onset of Reagan – I developed a sort of sideline patter about current events. Later, I realized this bore resemblance to a kind of global system dynamics.
Then, my consulting made these considerations more relevant – to the point that, in recent years, I make correlations between what you might call a global regional analysis and sales prospects, as well as corporate strategy.
How do you go about developing this perspective? The question is especially relevant for me now, since I am emerging from a deep dive into hands-on statistical modeling.
Well, one way to visualize this is as a series of threads through time. Each of these threads is strung with events that can turn out one way or another. There are main threads as believed to be constituted by “serious people.” The conventional view of things, if you will. There also are many outliers, story lines which incorporate unusual, perhaps foreboding developments. I guess you could think of these threads as scenarios, too. A whole bunch of movie scripts about how the future is going to unfold.
Now before getting into specifics, let me make what might be considered an obscure remark, but one relevant to forecasting. What you want to do is disentangle and identify as many of these threads as you have the energy to consider, and then, watch for convergences. If there are several ways, in other words, for some events to become manifested, these events become more likely.
One of the things this methodology accommodates is a fact that it seems to me that many people overlook or downplay. This is that there can be really fundamental differences between how different groups of people, perhaps with different interests or things to gain or lose out of situations, look at things.
One of the clearest examples, perceptually, is the arrow illusion.

So this is one reason why I try to glean perspectives from all over – including heterodox and contrarian views.
Noone at this point can convince me this is not a good practice, even though it may make those who busy themselves with thought control (“reality construction”) uncomfortable.
For example, many years ago, I was sitting at my father’s breakfast nook glancing at some books he had recently bought, and I found Andrei Amalrik’s Will the Soviet Union Survive Until 1984? What a preposterous idea, it seemed to me. Collapse of the Soviet Union.
It pays to look at heterodox views, even if only a few of these will have any relevance to the future.
Some Specifics
Well, today we have the internet – a font of views of all types.
In thinking about developing this and its successors on the same or similar topics this morning, I first turned to Zero Hedge. From Wikipedia,
Zero Hedge is a financial blog that aggregates news and presents editorial opinions from original and outside sources. It has been described as offering a “deeply conspiratorial, anti-establishment and pessimistic view of the world”… It reports on economics, Wall Street, and the financial sector and is credited with bringing the controversial practice of flash trading to public attention in 2009 via a series of posts alleging that Goldman Sachs’ access to flash order information allowed it to gain unfair profits. The news portion of the site is written by a group of editors who collectively write under the pseudonym “Tyler Durden”, a character from the novel and film Fight Club.
Since I have been out of the loop for a while, the litany of shocking or bad news on this site does not bother me yet.
Some of the headings include:
Iran Forces Seize US Cargo Ship With 34 People On Board, Al Arabiya Reports
West Baltimore In Ashes: A Night Of Violence And Looting In Photos
Stocks Soar On Non-War, Bad-News-Is-Good-News V-Shaped Recovery
Well, I’m not sure what to make of all that. Conflict is increasing. War and riot memes.
Another site I frequently turn to, quite frankly, is Naked Capitalism, and, in particular, Links assembled by “Yves Smith” and others. Today, these range over topics like the Greek-European Union negotiations and the threat of an exit of Greece from the Eurozone, the TPP (trans-Pacific Partnership secret trade bill), Yemen and Syria, and a reference to a new and important report from MIT about the decline in US science spending –The Future Postponed.
I also consult what I would call “libertarian” financial blogs such as Mish Shedlock’s Global Economic Trend Analysis.
Then, I guess, after surveying these “oppositional views,” I turn to official forecasts and publications of US and European banks and financial institutions, as well as central banks.
I’ve given play to JP Morgan forecasters here, as well as Bloomberg’s list of leading macroeconomic forecasters. It is always good to try to keep tabs on the latest sayings of these celebrity forecasters.
The Bank of England Financial Stability Report, most recently issued December 2014, is a relevant publication.
I also tend to look at, but basically discount, sources such as the Survey of Professional Forecasters, assembled by the Philadelphia Federal Reserve Bank. The record of macroeconomic forecasting is truly abysmal. But, apart from turning points, there may be value in tracking the projected movement of indicators and their trends.
The Central Issue
I have not mentioned slowing of the Chinese economy in the above discussion or several other megatrends, but let me move on to a key pivot for the next few years.
Business expansions never last forever. The current expansion, perhaps because it began so slowly, has sustained for a relatively long time already.
Another key point is that many central banks have pushed interest rates to near the zero bound, and they remain historically very low.
Frankly, it challenges my capabilities to imagine a future in which interest rates sort of disappear as key economic factors – although this may be a thread we need to consider. The attack on cash and movement to purely electronic money could be part of this, with negative interest rates entering the picture in a real way.
But assuming that does not happen, central banks will have to encourage higher interest rates, and that will have wide-ranging effects on business, it seems certain. There are many tangible forecasting problems associated with this prospective development.
I have to believe this is the central issue at present. How can the US Federal Reserve, for example, move off the zero bound for the federal funds rate, when the US economic recovery should, according to historical patterns, be moving toward its final months or years?
There are other tough issues – in the Middle East, the Ukraine, climate change, and so forth – but, as an economic or business forecaster, I have to believe this tension between normal banking practice and the business cycle is fundamental.
In any case, I want to return to putting up business forecasts, including longer term scenarios, in addition to carrying forth with my stock market forecasting experiment.