I have discovered a fundamental feature of stock market prices, relating to prediction of the highs and lows in daily, weekly, monthly, and to other more arbitrary groupings of trading days in consecutive blocks.
What I have found is a degree of predictability previously unimagined with respect to forecasts of the high and low for a range of trading periods, extending from daily to 60 days so far.
Currently, I am writing up this research for journal submission, but I am documenting essential features of my findings on this blog.
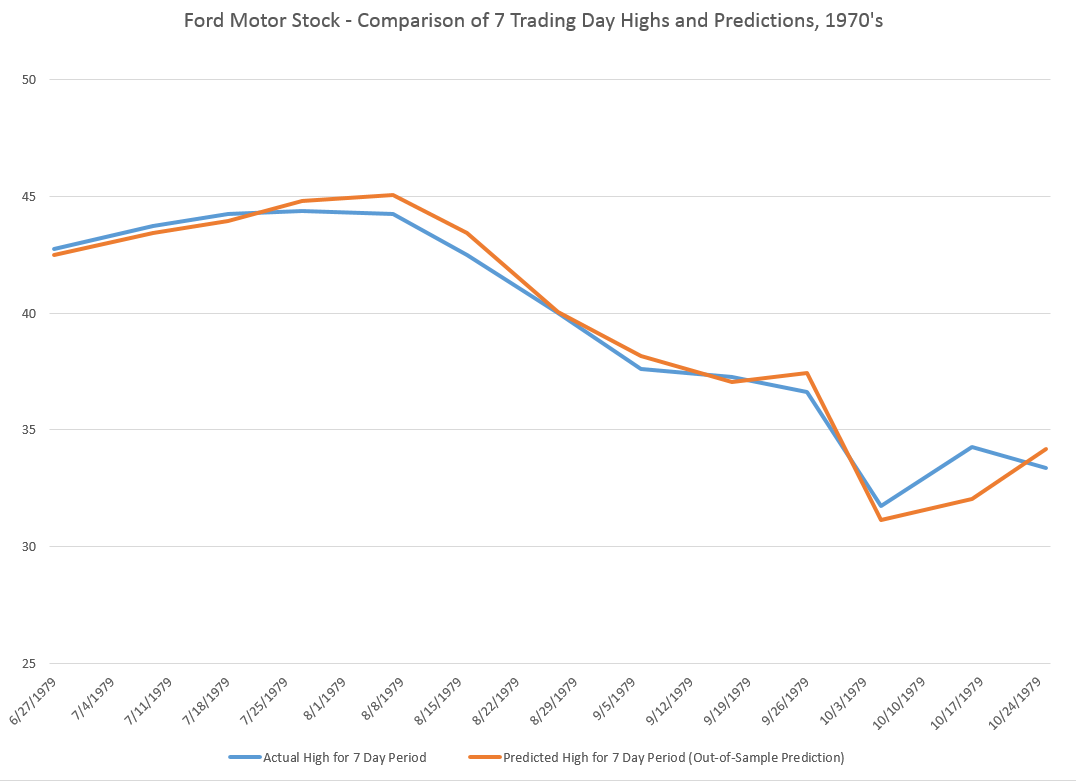
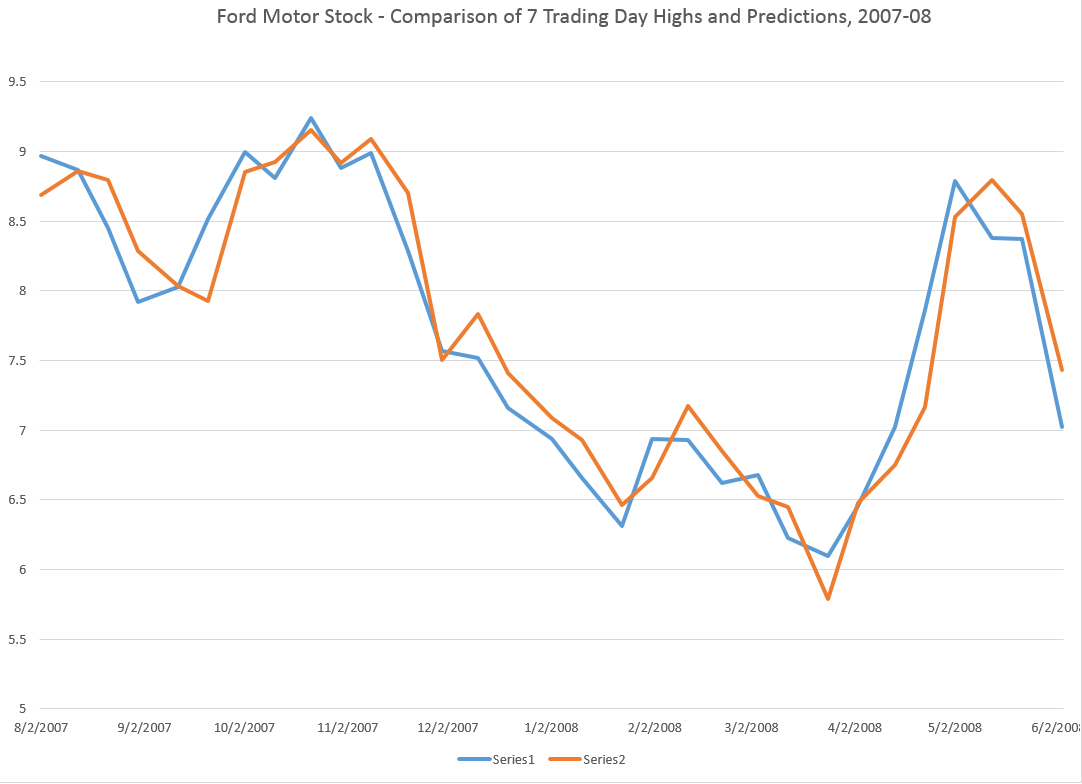
A few days ago, I posted about the predictability of daily highs and lows for the SPY exchange traded fund. Subsequent posts highlight the generality of the result for the SPY, and more recently, for stocks such as common stock of the Ford Motor Company.
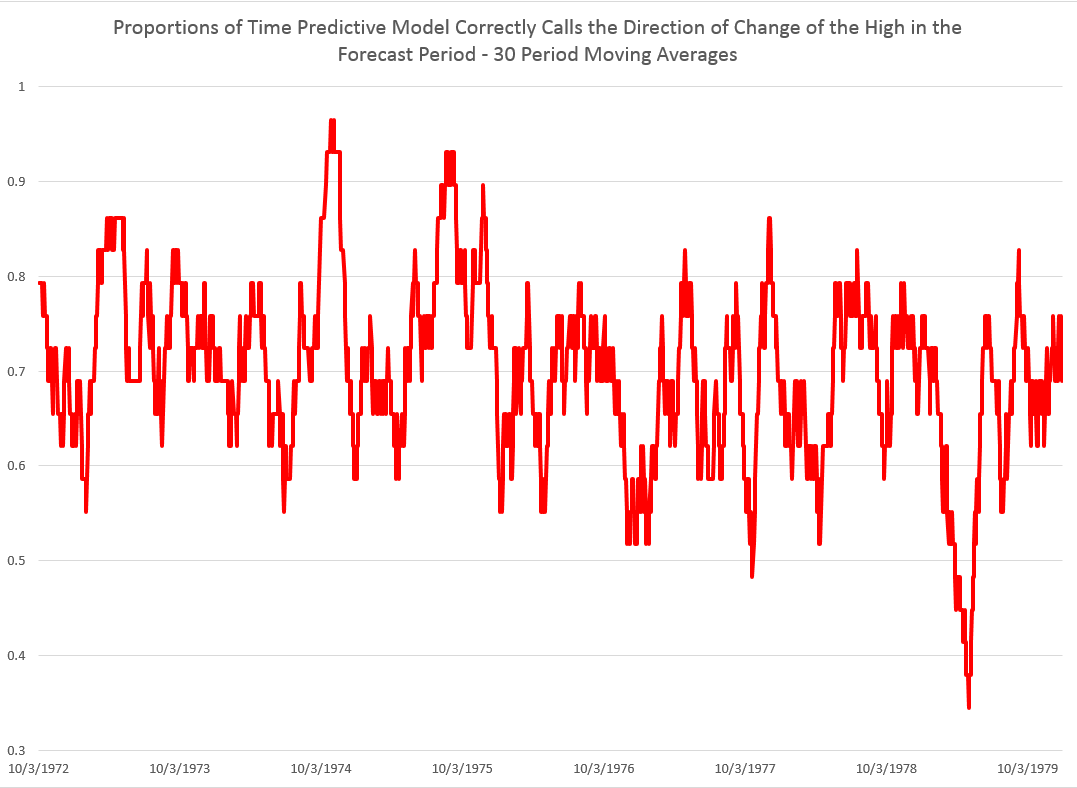
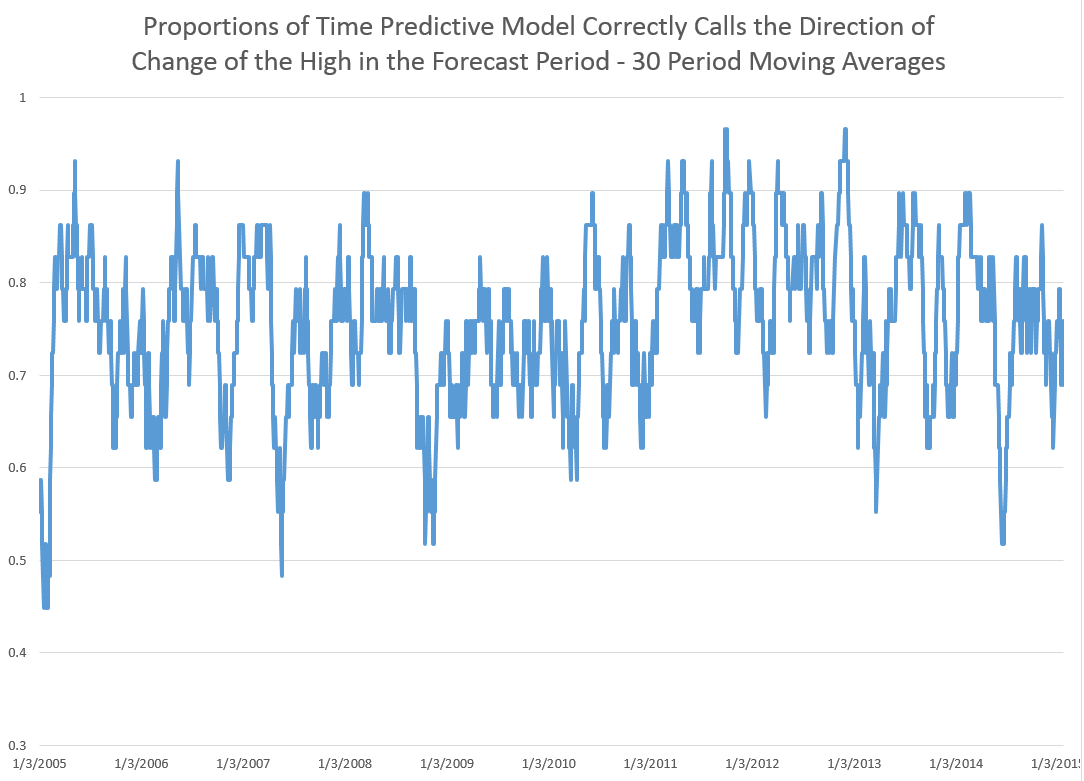
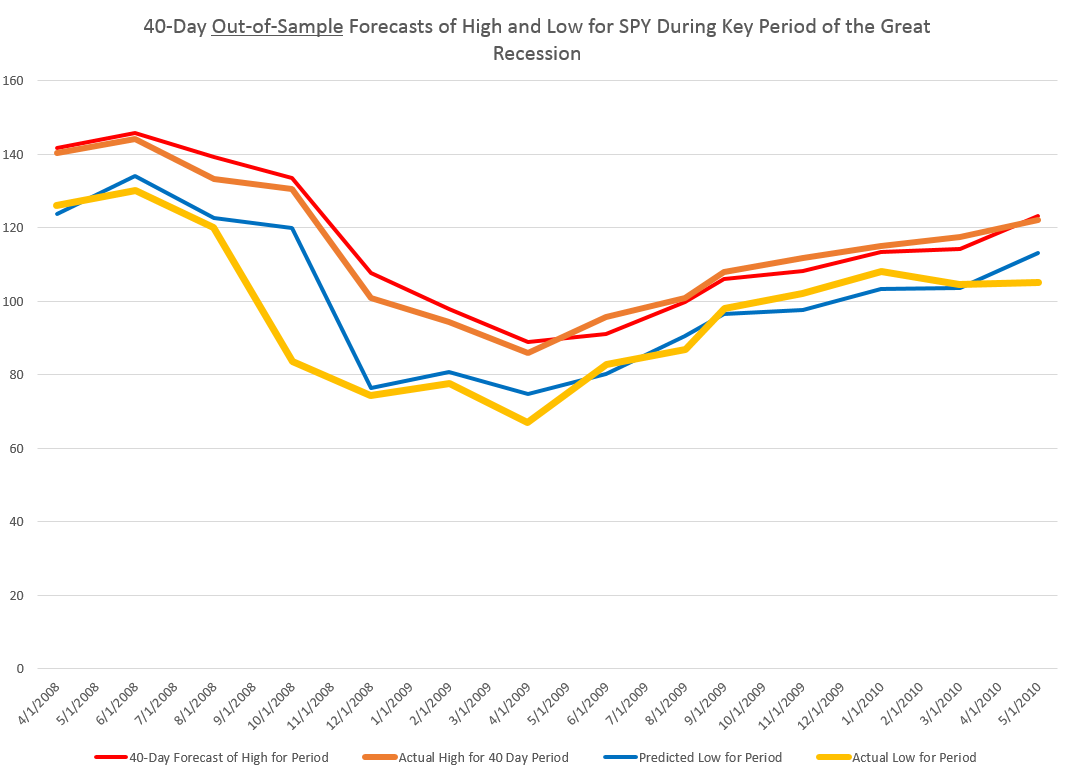
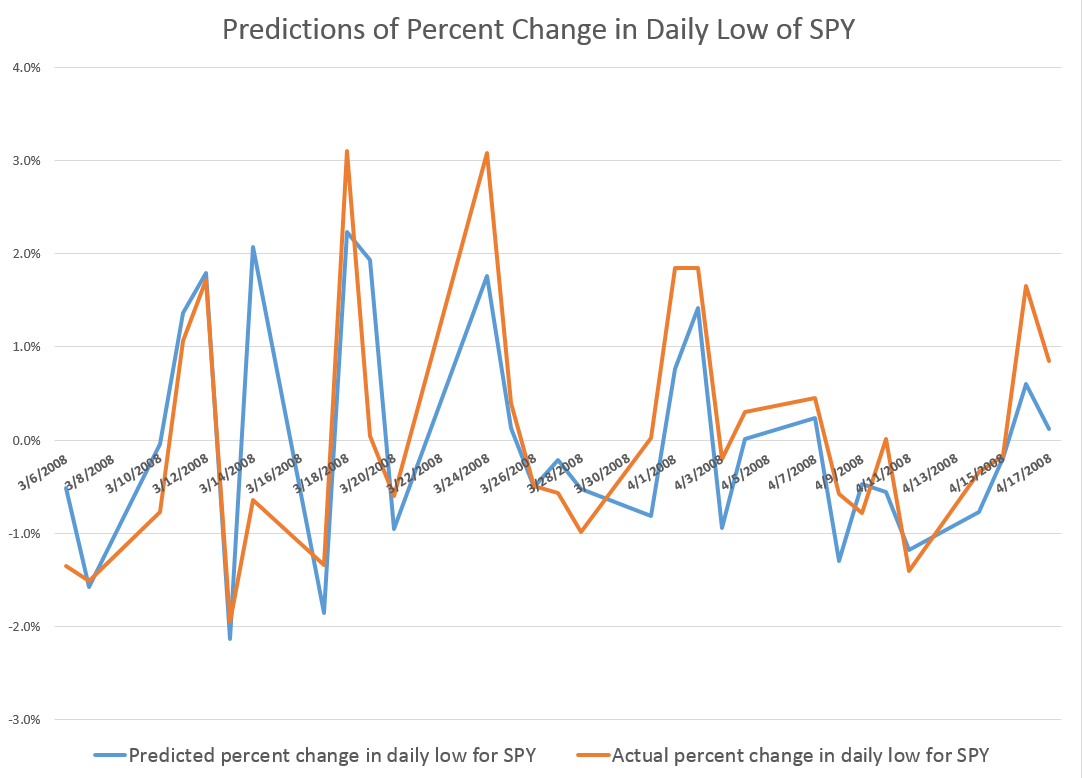
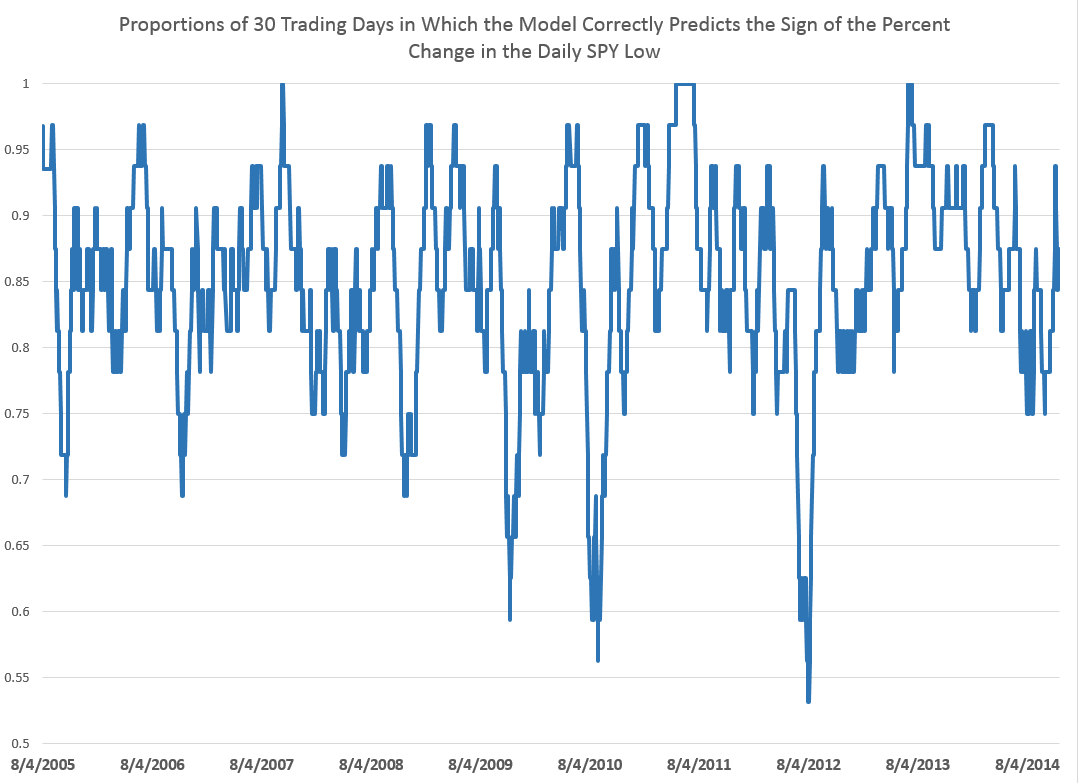
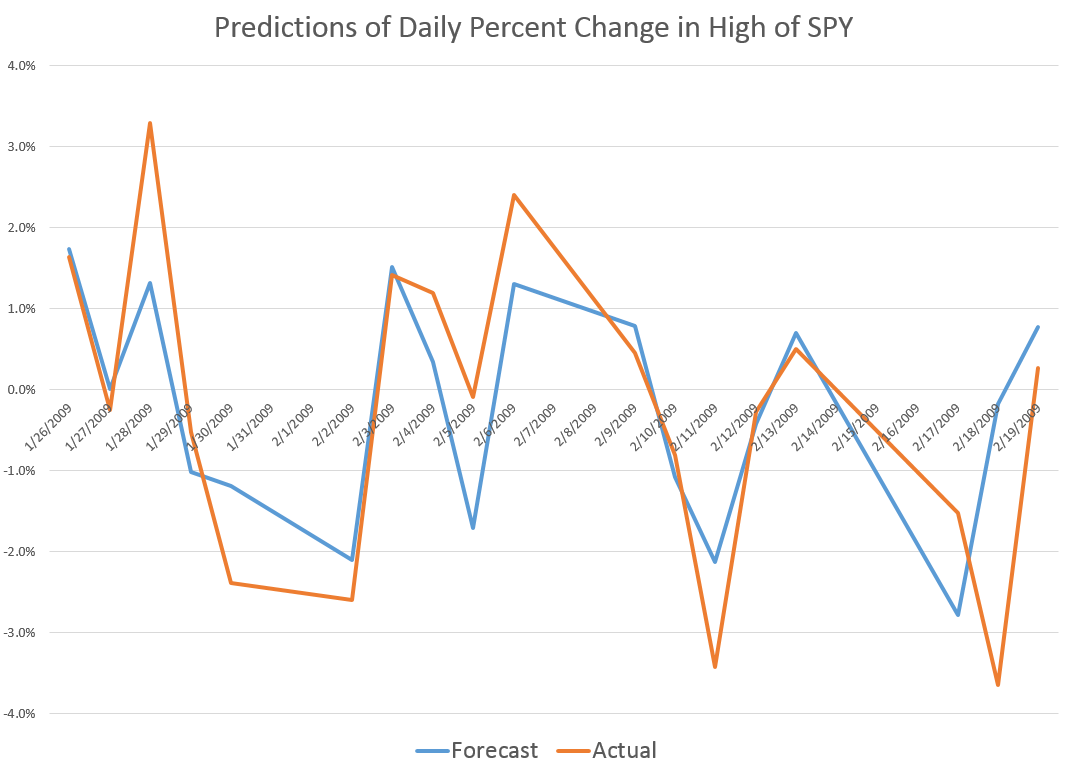
These posts present various graphs illustrating how well the prediction models for the high and low in periods capture the direction of change of the actual highs and lows. Generally, the models are right about 70 to 80 percent of the time, which is incredible.
Furthermore, since one of my long concerns has been to get better forward perspective on turning points – I am particularly interested in the evidence that these models also do fairly well as predicting turning points.
Finally, it is easy to show that these predictive models for the highs and lows of stocks and stock indices over various periods, furthermore, are not simply creations of modern program trading. The same regularities can be identified in earlier periods before easy access to computational power, in the 1980’s and early 1990’s, for example.
Hong Kong’s Hang Seng Index
Today, I want to reach out and look at international data and present findings for Hong Kong’s Hang Seng Index. I suspect Chinese investors will be interested in these results. Perhaps, releasing this information to such an active community of traders will test my hypothesis that these are self-fulfilling predictions, to a degree, and knowledge of their existence intensifies their predictive power.
A few facts about the Hang Seng Index – The Hang Seng Index (HSI) is a free-float adjusted, capitalization-weighted index of approximately 40 of the larger companies on the Hong Kong exchange. First published in 1969, the HSI, according to Investopedia, covers approximately 65% of the total market capitalization of the Hong Kong Stock Exchange. It is currently maintained by HSI Services Limited, a wholly owned subsidiary of Hang Seng Bank – the largest bank registered and listed in Hong Kong in terms of market capitalization.
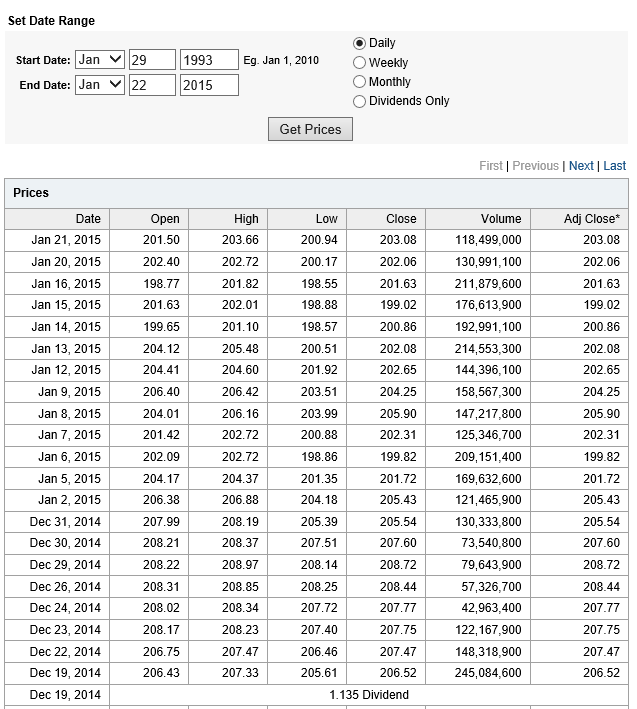
For data, I download daily open, high, low, close and other metrics from Yahoo Finance. This data begins with the last day in 1986, continuing to the present.
The Hang Seng is a volatile index, as the following chart illustrates.
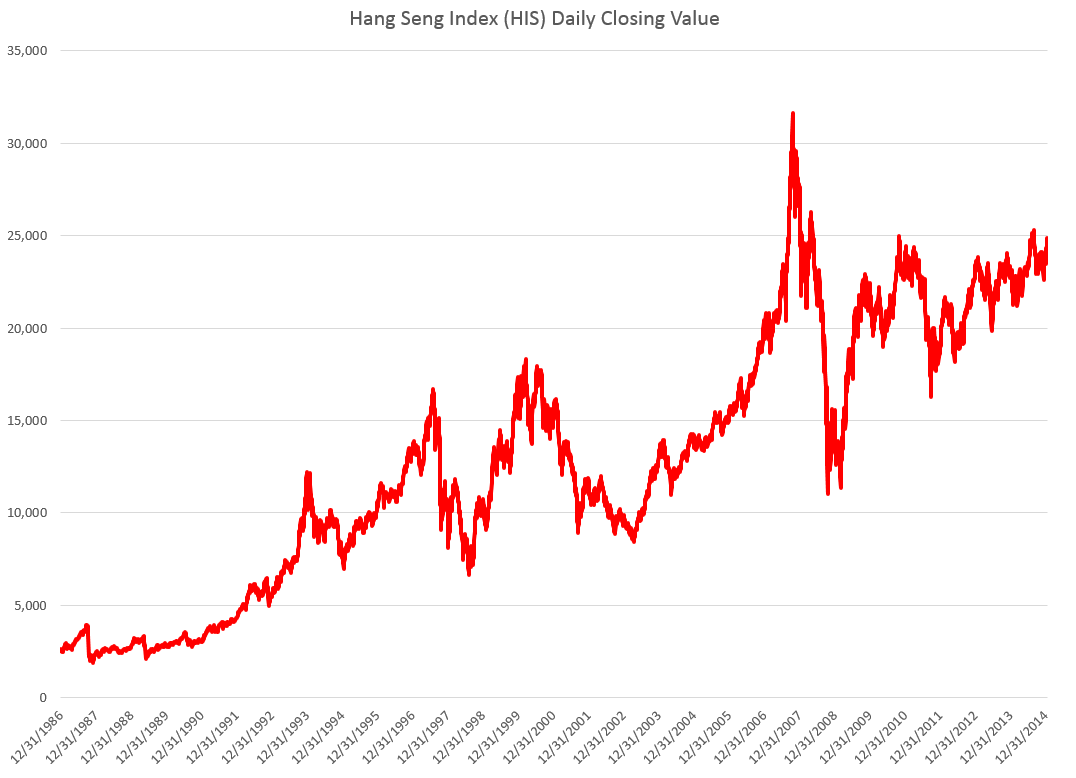
Now there are peculiarities about the data on HSI from Yahoo. Trading volumes are zero until 2001, for example, after which time large positive values are to be found in the volume column. Initially, I assume HSI was a pure index and later came to be actually traded in some fashion.
Nevertheless, the same type of predictive models can be developed for the Hang Seng Index, as can be estimated for the SPY and the US stocks.
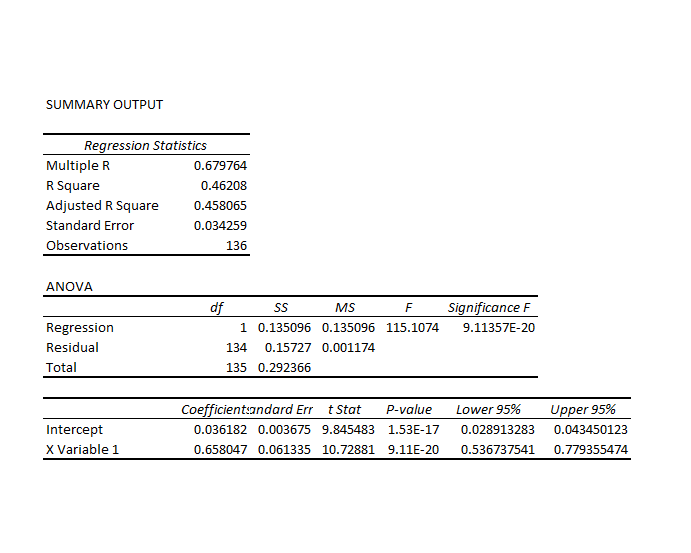
Again, the key variables in these predictive relationships are the proximity of the period opening price to the previous period high and the previous period low. I estimate regressions with variables constructed from these explanatory variables, mapping them onto growth in period-by-period highs with ordinary least squares (OLS). I find the similar relationships for the Hang Seng in, say, a 30 day periodization as I estimate for the SPY ETF. At the same time there are differences, one of the most notable being the significantly less first order autocorrelation in the Hang Seng regression.
Essentially, higher growth rates for the period-over-previous-period high are predicted whenever the opening price of the current period is greater than the high of the previous period. There are other cases, however, and ultimately the rule is quantitative, taking into account the size of the growth rates for the high as well as these inequality relationships.
Findings
Here is another one of those charts showing the “hit-rate” for predictions of the direction of change of the sign of period-by-period growth rates for the high. In this case, the chart refers to daily trading data. The chart graphs 30 day moving averages of the proportions of time in which the predictive model forecasts the correct sign of the change or growth in the target or independent variable – the growth rate of daily highs (for consecutive trading days). Note that for recent years, the “hit rate” of the predictive model approaches 90 percent of the time, and all these are all out-of-sample predictions.
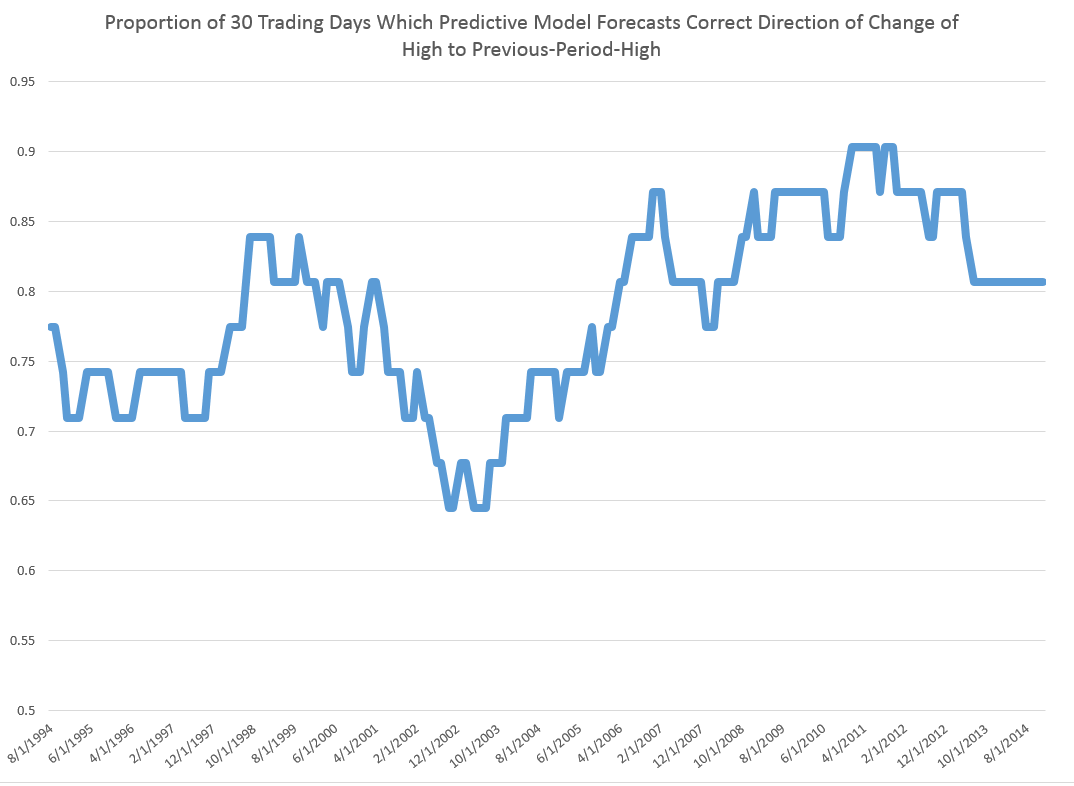
The relationship for the Hang Seng Index, thus, is powerful. Similarly impressive relationships can be derived to predict the daily lows and their direction of change.
But the result I really like with this data is developed with grouping the daily trading data by 30 day intervals.
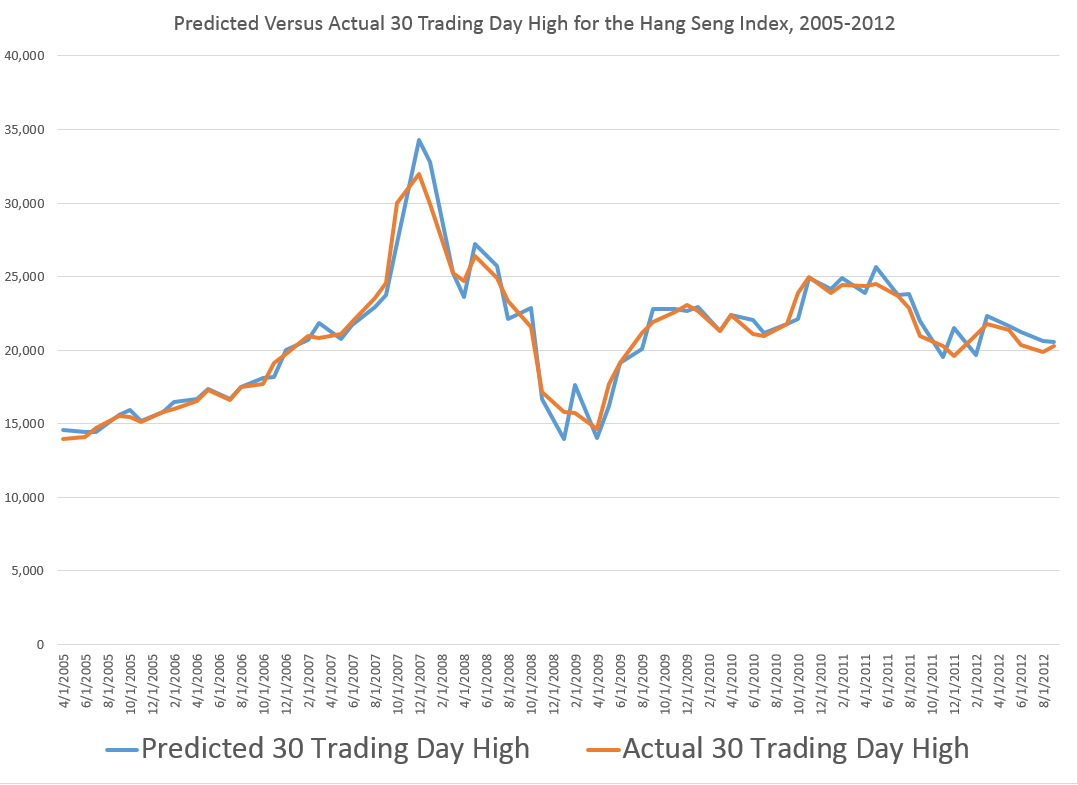
If you do this, you develop a tool which apparently is quite capable of predicting turning points in the Hang Seng.
Thus, between April 2005 and August 2012, a 30-day predictive model captures many of the key features of inflection and turning in the Hang Seng High for comparable periods.
Note that the predictive model makes these forecasts of the high for a period out-of-sample. All the relationships are estimated over historical data which do not include the high (or low) being predicted for the coming 30 day period. Only the opening price for the Hang Seng for that period is necessary.
Concluding Thoughts
I do not present the regression results here, but am pleased to share further information for readers responding to the Comments section to this blog (title ” Request for High/Low Model Information”) or who send requests to the following mail address: Clive Jones, PO Box 1009, Boulder, CO 80306 USA.
Top image from Ancient Chinese Fashion