After review, I have come to the conclusion that from a predictive and operational standpoint, causal explanations translate to directed graphs, such as the following:
And I think it is interesting the machine learning community focuses on causal explanations for “manipulation” to guide reactive and interactive machines, and that directed graphs (or perhaps a Bayesian networks) are a paramount concept.
Keep that thought, and consider “Granger causality.”
This time series concept is well explicated in C.W.J. Grangers’ 2003 Nobel Prize lecture – which motivates its discovery and links with cointegration.
An earlier concept that I was concerned with was that of causality. As a postdoctoral student in Princeton in 1959–1960, working with Professors John Tukey and Oskar Morgenstern, I was involved with studying something called the “cross-spectrum,” which I will not attempt to explain. Essentially one has a pair of inter-related time series and one would like to know if there are a pair of simple relations, first from the variable X explaining Y and then from the variable Y explaining X. I was having difficulty seeing how to approach this question when I met Dennis Gabor who later won the Nobel Prize in Physics in 1971. He told me to read a paper by the eminent mathematician Norbert Wiener which contained a definition that I might want to consider. It was essentially this definition, somewhat refined and rounded out, that I discussed, together with proposed tests in the mid 1960’s.
The statement about causality has just two components: 1. The cause occurs before the effect; and 2. The cause contains information about the effect that that is unique, and is in no other variable.
A consequence of these statements is that the causal variable can help forecast the effect variable after other data has first been used. Unfortunately, many users concentrated on this forecasting implication rather than on the original definition. At that time, I had little idea that so many people had very fixed ideas about causation, but they did agree that my definition was not “true causation” in their eyes, it was only “Granger causation.” I would ask for a definition of true causation, but no one would reply. However, my definition was pragmatic and any applied researcher with two or more time series could apply it, so I got plenty of citations. Of course, many ridiculous papers appeared.
When the idea of cointegration was developed, over a decade later, it became clear immediately that if a pair of series was cointegrated then at least one of them must cause the other. There seems to be no special reason why there two quite different concepts should be related; it is just the way that the mathematics turned out
In the two-variable case, suppose we have time series Y={y1,y2,…,yt} and X = {x1,..,xt}. Then, there are, at the outset, two cases, depending on whether Y and X are stationary or nonstationary. The classic case is where we have an autoregressive relationship for yt,
yt = a0+a1yt-1+..+akyt-k
and this relationship can be shown to be a weaker predictor than
yt = a0+a1yt-1+..+akyt-k + b0+b1xt-1+..+bmxt-m
In this case, we say that X exhibits Granger causality with respect to Y.
Of course, if Y and X are nonstationary time series, autoregressive predictive equations make no sense, and instead we have the case of cointegration of time series, where in the two-variable case,
yt=φxt-1+ut
and the series of residuals ut are reduced to a white noise process.
So these cases follow what good old Wikipedia says,
A time series X is said to Granger-cause Y if it can be shown, usually through a series of t-tests and F-tests on lagged values of X (and with lagged values of Y also included), that those X values provide statistically significant information about future values of Y.
There are a number of really interesting extensions of this linear case, discussed in a recent survey paper.
Stern points out that the main enemies or barriers to establishing causal relations are endogeneity and omitted variables.
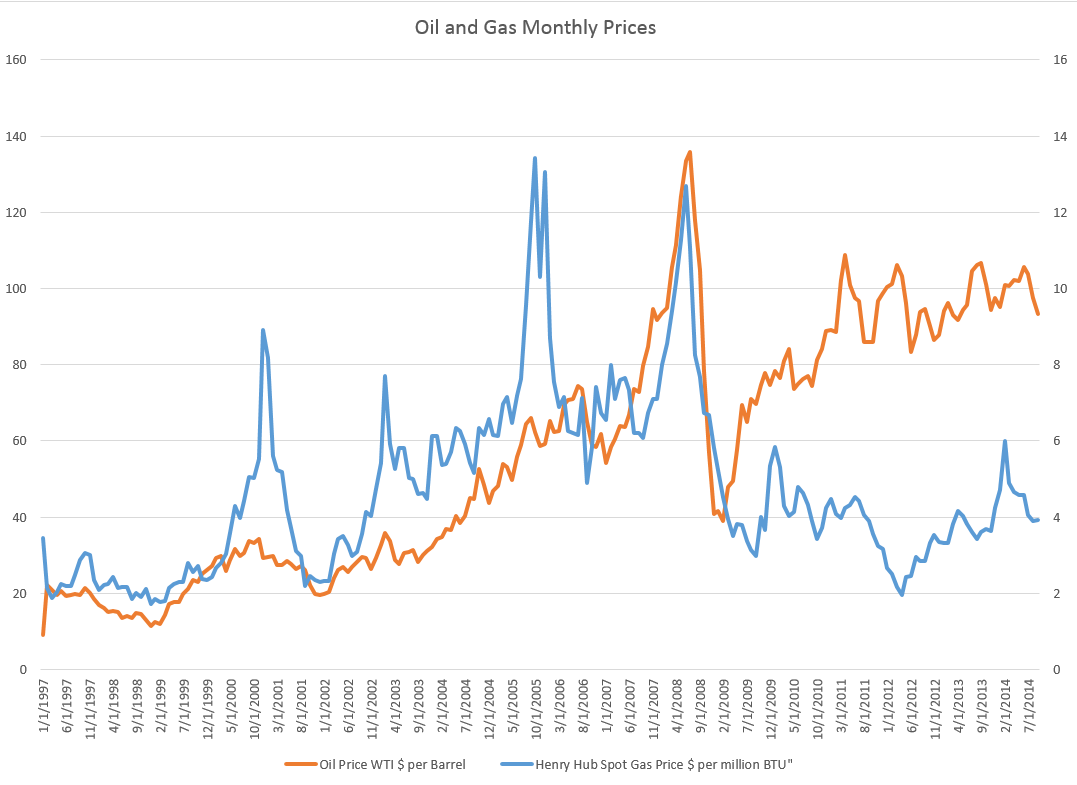
So I find that margin loans and the level of the S&P 500 appear to be mutually interrelated. Thus, it is forecasts of the S&P 500 can be improved with lagged values of margin loans, and you can improve forecasts of the monthly total of margin loans with lagged values of the S&P 500 – at least over broad ranges of time and in the period since 2008. The predictions of the S&P 500 with lagged values of margin loans, however, are marginally more powerful or accurate predictions.
Stern gives a colorful example where an explanatory variable is clearly exogenous and appears to have a significant effect on the dependent variable and yet theory suggests that the relationship is spurious and due to omitted variables that happen to be correlated with the explanatory variable in question.
Westling (2011) regresses national economic growth rates on average reported penis lengths and other variables and finds that there is an inverted U shape relationship between economic growth and penis length from 1960 to 1985. The growth maximizing length was 13.5cm, whereas the global average was 14.5cm. Penis length would seem to be exogenous but the nature of this relationship would have changed over time as the fastest growing region has changed from Europe and its Western Offshoots to Asia. So, it seems that the result is likely due to omitted variables bias.
Here Stern notes that Westling’s data indicates penis length is lowest in Asia and greatest in Africa with Europe and its Western Offshoots having intermediate lengths.
There’s a paper which shows stock prices exhibit Granger causality with respect to economic growth in the US, but vice versa does not obtain. This is a good illustration of the careful ste-by-step in conducting this type of analysis, and how it is in fact fraught with issues of getting the number of lags exactly right and avoiding big specification problems.
Just at the moment when it looks as if the applications of Granger causality are petering out in economics, neuroscience rides to the rescue. I offer you a recent article from a journal in computation biology in this regard – Measuring Granger Causality between Cortical Regions from Voxelwise fMRI BOLD Signals with LASSO.
Here’s the Abstract:
Functional brain network studies using the Blood Oxygen-Level Dependent (BOLD) signal from functional Magnetic Resonance Imaging (fMRI) are becoming increasingly prevalent in research on the neural basis of human cognition. An important problem in functional brain network analysis is to understand directed functional interactions between brain regions during cognitive performance. This problem has important implications for understanding top-down influences from frontal and parietal control regions to visual occipital cortex in visuospatial attention, the goal motivating the present study. A common approach to measuring directed functional interactions between two brain regions is to first create nodal signals by averaging the BOLD signals of all the voxels in each region, and to then measure directed functional interactions between the nodal signals. Another approach, that avoids averaging, is to measure directed functional interactions between all pairwise combinations of voxels in the two regions. Here we employ an alternative approach that avoids the drawbacks of both averaging and pairwise voxel measures. In this approach, we first use the Least Absolute Shrinkage Selection Operator (LASSO) to pre-select voxels for analysis, then compute a Multivariate Vector AutoRegressive (MVAR) model from the time series of the selected voxels, and finally compute summary Granger Causality (GC) statistics from the model to represent directed interregional interactions. We demonstrate the effectiveness of this approach on both simulated and empirical fMRI data. We also show that averaging regional BOLD activity to create a nodal signal may lead to biased GC estimation of directed interregional interactions. The approach presented here makes it feasible to compute GC between brain regions without the need for averaging. Our results suggest that in the analysis of functional brain networks, careful consideration must be given to the way that network nodes and edges are defined because those definitions may have important implications for the validity of the analysis.
So Granger causality is still a vital concept, despite its probably diminishing use in econometrics per se.
Let me close with this thought and promise a future post on the Kaggle and machine learning competitions on identifying the direction of causality in pairs of variables without context.
Correlation does not imply causality—you’ve heard it a thousand times. But causality does imply correlation.