Malcolm Gladwell’s 10,000 hour rule (for cognitive mastery) is sort of an inspiration for me. I picked forecasting as my field for “cognitive mastery,” as dubious as that might be. When I am directly engaged in an assignment, at some point or other, I feel the need for immersion in the data and in estimations of all types. This blog, on the other hand, represents an effort to survey and, to some extent, get control of new “tools” – at least in a first pass. Then, when I have problems at hand, I can try some of these new techniques.
Ok, so these remarks preface what you might call the humility of my approach to new methods currently being innovated. I am not putting myself on a level with the innovators, for example. At the same time, it’s important to retain perspective and not drop a critical stance.
The Working Paper and Article in the Journal of Finance
Probably one of the most widely-cited recent working papers is Kelly and Pruitt’s three pass regression filter (3PRF). The authors, shown above, are with the University of Chicago, Booth School of Business and the Federal Reserve Board of Governors, respectively, and judging from the extensive revisions to the 2011 version, they had a bit of trouble getting this one out of the skunk works.
Recently, however, Kelly and Pruit published an important article in the prestigious Journal of Finance called Market Expectations in the Cross-Section of Present Values. This article applies a version of the three pass regression filter to show that returns and cash flow growth for the aggregate U.S. stock market are highly and robustly predictable.
I learned of a published application of the 3PRF from Francis X. Dieblod’s blog, No Hesitations, where Diebold – one of the most published authorities on forecasting – writes
Recent interesting work, moreover, extends PLS in powerful ways, as with the Kelly-Pruitt three-pass regression filter and its amazing apparent success in predicting aggregate equity returns.
What is the 3PRF?
The working paper from the Booth School of Business cited at a couple of points above describes what might be cast as a generalization of partial least squares (PLS). Certainly, the focus in the 3PRF and PLS is on using latent variables to predict some target.
I’m not sure, though, whether 3PRF is, in fact, more of a heuristic, rather than an algorithm.
What I mean is that the three pass regression filter involves a procedure, described below.
(click to enlarge).

Here’s the basic idea –
Suppose you have a large number of potential regressors xi ε X, i=1,..,N. In fact, it may be impossible to calculate an OLS regression, since N > T the number of observations or time periods.
Furthermore, you have proxies zj ε Z, I = 1,..,L – where L is significantly less than the number of observations T. These proxies could be the first several principal components of the data matrix, or underlying drivers which theory proposes for the situation. The authors even suggest an automatic procedure for generating proxies in the paper.
And, finally, there is the target variable yt which is a column vector with T observations.
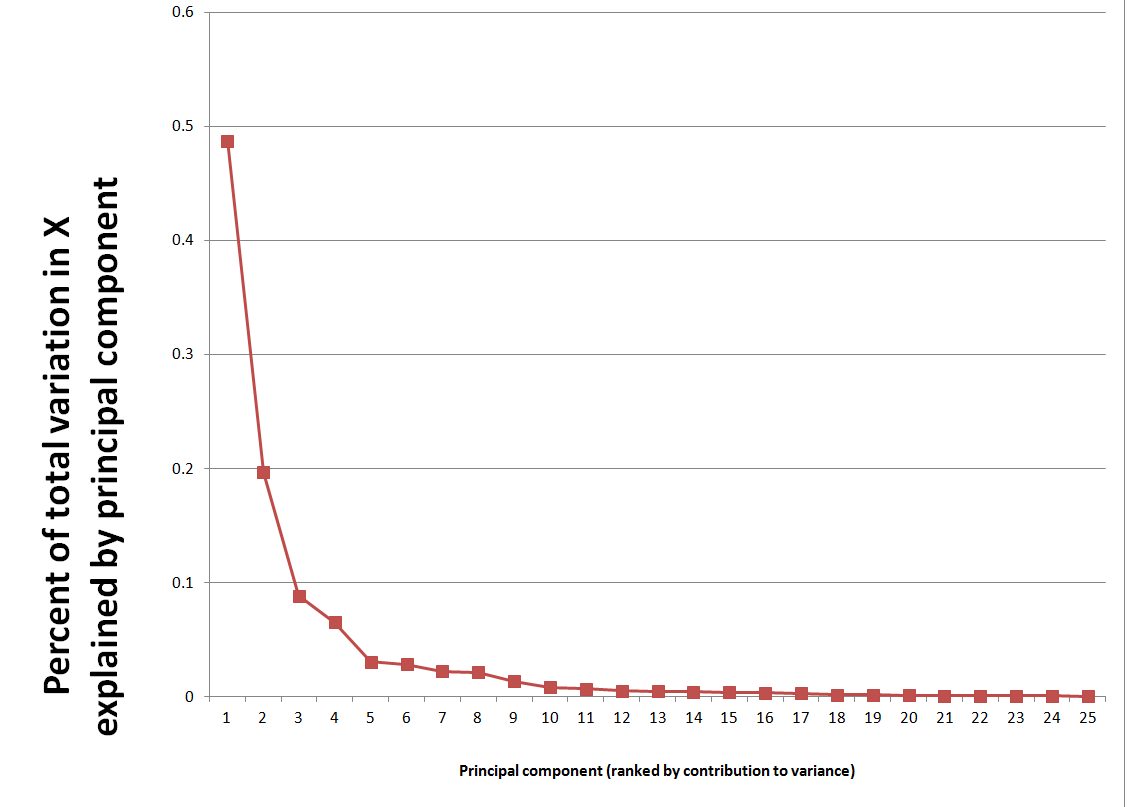
Latent factors in a matrix F drive both the proxies in Z and the predictors in X. Based on macroeconomic research into dynamic factors, there might be only a few of these latent factors – just as typically only a few principal components account for the bulk of variation in a data matrix.
Now here is a key point – as Kelly and Pruitt present the 3PRF, it is a leading indicator approach when applied to forecasting macroeconomic variables such as GDP, inflation, or the like. Thus, the time index for yt ranges from 2,3,…T+1, while the time indices of all X and Z variables and the factors range from 1,2,..T. This means really that all the x and z variables are potentially leading indicators, since they map conditions from an earlier time onto values of a target variable at a subsequent time.
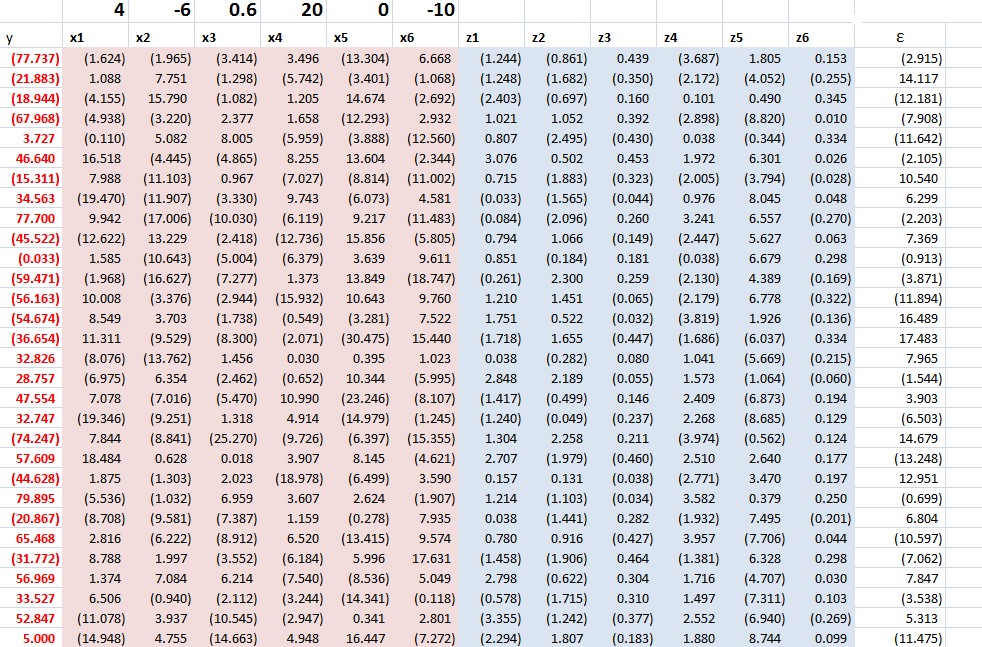
What Table 1 above tells us to do is –
- Run an ordinary least square (OLS) regression of the xi in X onto the zj in X, where T ranges from 1 to T and there are N variables in X and L << T variables in Z. So, in the example discussed below, we concoct a spreadsheet example with 3 variables in Z, or three proxies, and 10 predictor variables xi in X (I could have used 50, but I wanted to see whether the method worked with lower dimensionality). The example assumes 40 periods, so t = 1,…,40. There will be 40 different sets of coefficients of the zj as a result of estimating these regressions with 40 matched constant terms.
- OK, then we take this stack of estimates of coefficients of the zj and their associated constants and map them onto the cross sectional slices of X for t = 1,..,T. This means that, at each period t, the values of the cross-section. xi,t, are taken as the dependent variable, and the independent variables are the 40 sets of coefficients (plus constant) estimated in the previous step for period t become the predictors.
- Finally, we extract the estimate of the factor loadings which results, and use these in a regression with target variable as the dependent variable.
This is tricky, and I have questions about the symbolism in Kelly and Pruitt’s papers, but the procedure they describe does work. There is some Matlab code here alongside the reference to this paper in Professor Kelly’s research.
At the same time, all this can be short-circuited (if you have adequate data without a lot of missing values, apparently) by a single humungous formula –

Here, the source is the 2012 paper.
Spreadsheet Implementation
Spreadsheets help me understand the structure of the underlying data and the order of calculation, even if, for the most part, I work with toy examples.
So recently, I’ve been working through the 3PRF with a small spreadsheet.
Generating the factors:I generated the factors as two columns of random variables (=rand()) in Excel. I gave the factors different magnitudes by multiplying by different constants.
Generating the proxies Z and predictors X. Kelly and Pruitt call for the predictors to be variance standardized, so I generated 40 observations on ten sets of xi by selecting ten different coefficients to multiply into the two factors, and in each case I added a normal error term with mean zero and standard deviation 1. In Excel, this is the formula =norminv(rand(),0,1).
Basically, I did the same drill for the three zj — I created 40 observations for z1, z2, and z3 by multiplying three different sets of coefficients into the two factors and added a normal error term with zero mean and variance equal to 1.
Then, finally, I created yt by multiplying randomly selected coefficients times the factors.
After generating the data, the first pass regression is easy. You just develop a regression with each predictor xi as the dependent variable and the three proxies as the independent variables, case-by-case, across the time series for each. This gives you a bunch of regression coefficients which, in turn, become the explanatory variables in the cross-sectional regressions of the second step.
The regression coefficients I calculated for the three proxies, including a constant term, were as follows – where the 1st row indicates the regression for x1 and so forth.
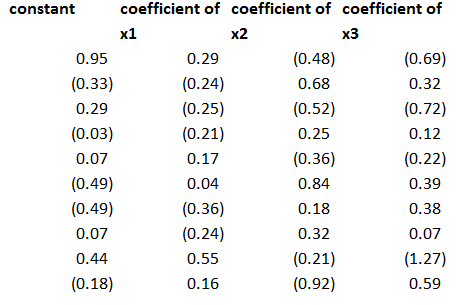
This second step is a little tricky, but you just take all the values of the predictor variables for a particular period and designate these as the dependent variables, with the constant and coefficients estimated in the previous step as the independent variables. Note, the number of predictors pairs up exactly with the number of rows in the above coefficient matrix.
This then gives you the factor loadings for the third step, where you can actually predict yt (really yt+1 in the 3PRF setup). The only wrinkle is you don’t use the constant terms estimated in the second step, on the grounds that these reflect “idiosyncratic” effects, according to the 2011 revision of the paper.
Note the authors describe this as a time series approach, but do not indicate how to get around some of the classic pitfalls of regression in a time series context. Obviously, first differencing might be necessary for nonstationary time series like GDP, and other data massaging might be in order.
Bottom line – this worked well in my first implementation.
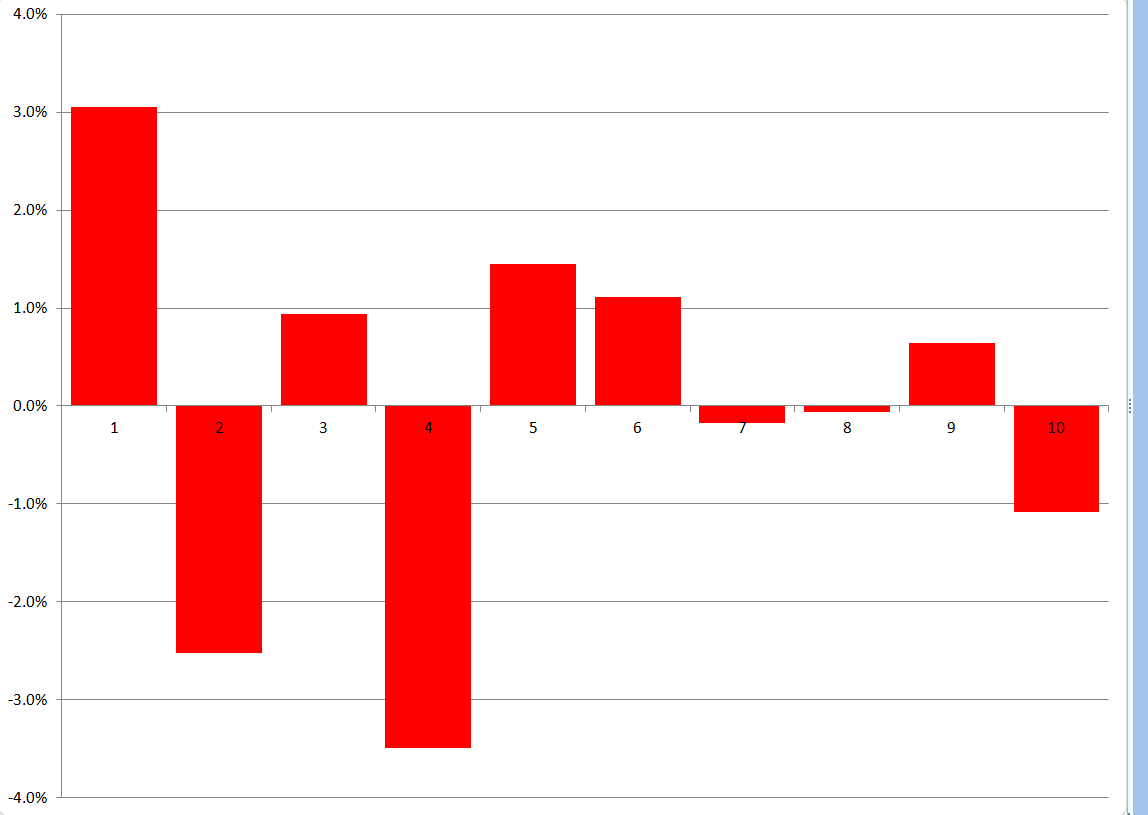
To forecast, I just used the last regression for yt+1 and then added ten more cases, calculating new values for the target variable with the new values of the factors. I used the new values of the predictors to update the second step estimate of factor loadings, and applied the last third pass regression to these values.
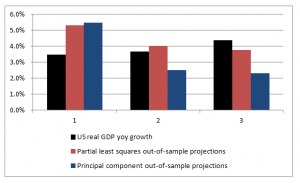
Here are the forecast errors for these ten out-of-sample cases.
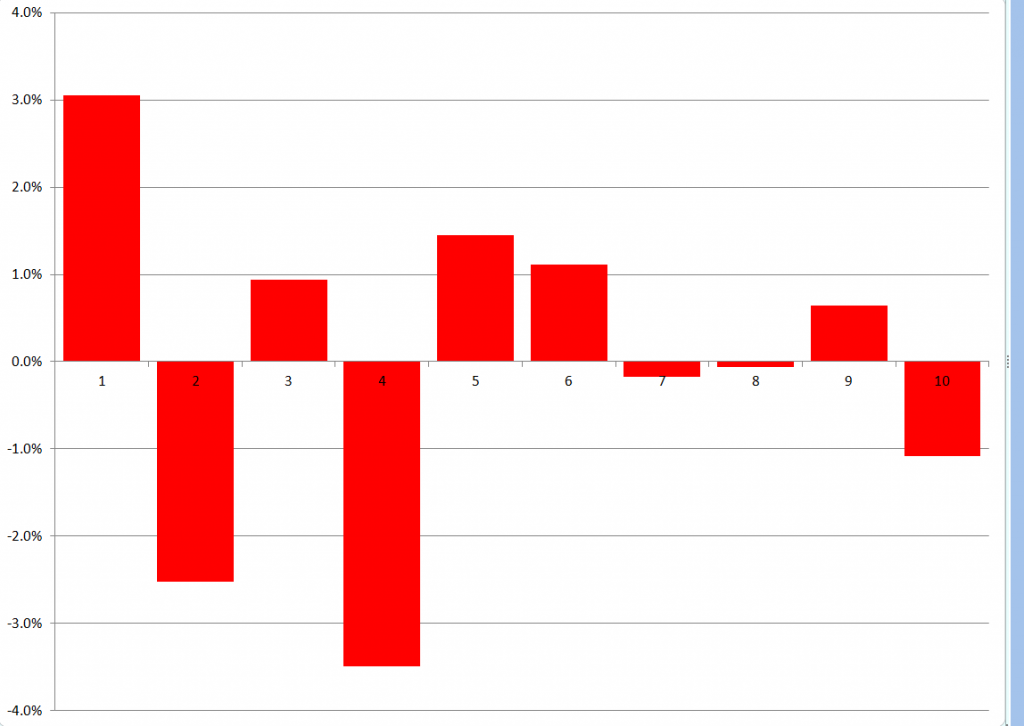
Not bad for a first implementation.
Why Is Three Pass Regression Important?
3PRF is a fairly “clean” solution to an important problem, relating to the issue of “many predictors” in macroeconomics and other business research.
Noting that if the predictors number near or more than the number of observations, the standard ordinary least squares (OLS) forecaster is known to be poorly behaved or nonexistent, the authors write,
How, then, does one effectively use vast predictive information? A solution well known in the economics literature views the data as generated from a model in which latent factors drive the systematic variation of both the forecast target, y, and the matrix of predictors, X. In this setting, the best prediction of y is infeasible since the factors are unobserved. As a result, a factor estimation step is required. The literature’s benchmark method extracts factors that are significant drivers of variation in X and then uses these to forecast y. Our procedure springs from the idea that the factors that are relevant to y may be a strict subset of all the factors driving X. Our method, called the three-pass regression filter (3PRF), selectively identifies only the subset of factors that influence the forecast target while discarding factors that are irrelevant for the target but that may be pervasive among predictors. The 3PRF has the advantage of being expressed in closed form and virtually instantaneous to compute.
So, there are several advantages, such as (1) the solution can be expressed in closed form (in fact as one complicated but easily computable matrix expression), and (2) there is no need to employ maximum likelihood estimation.
Furthermore, 3PRF may outperform other approaches, such as principal components regression or partial least squares.
The paper illustrates the forecasting performance of 3PRF with real-world examples (as well as simulations). The first relates to forecasts of macroeconomic variables using data such as from the Mark Watson database mentioned previously in this blog. The second application relates to predicting asset prices, based on a factor model that ties individual assets’ price-dividend ratios to aggregate stock market fluctuations in order to uncover investors’ discount rates and dividend growth expectations.

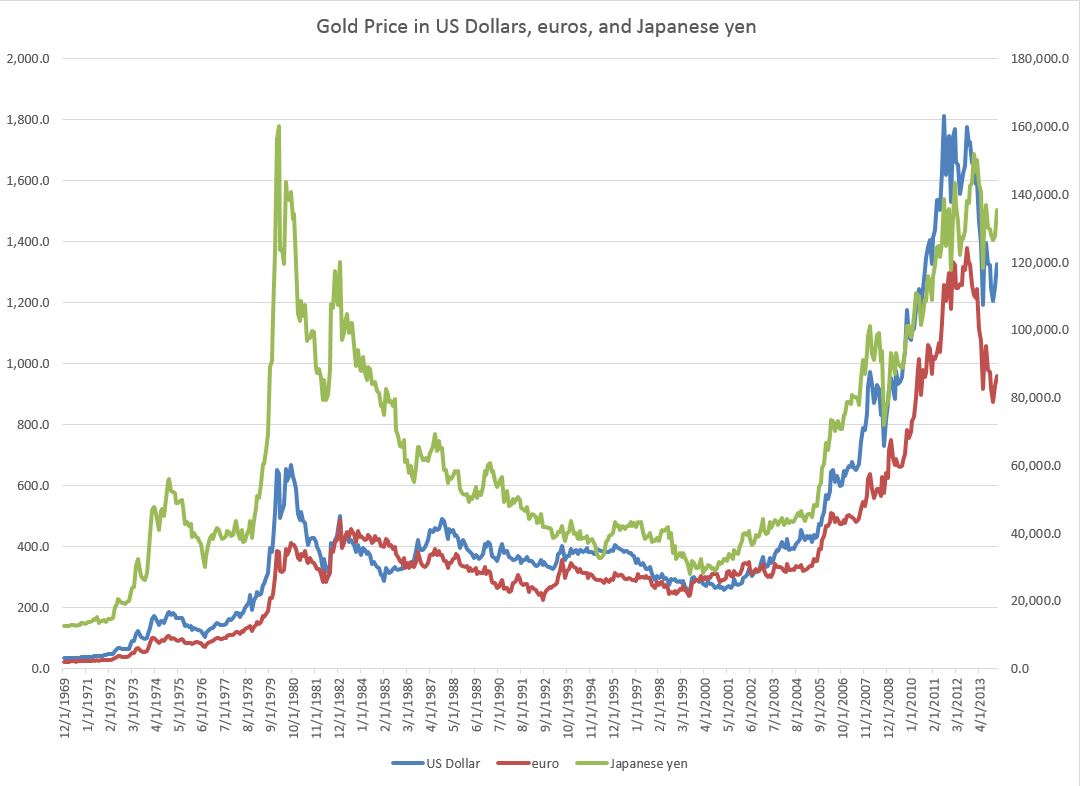
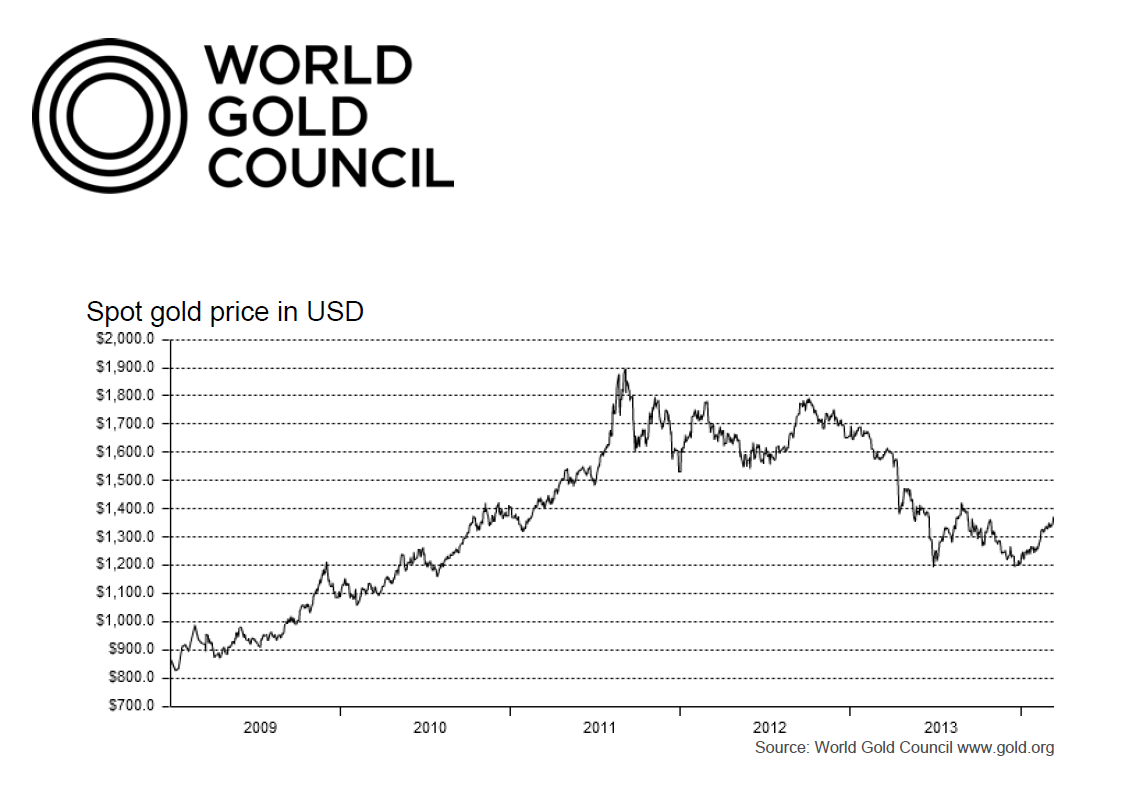
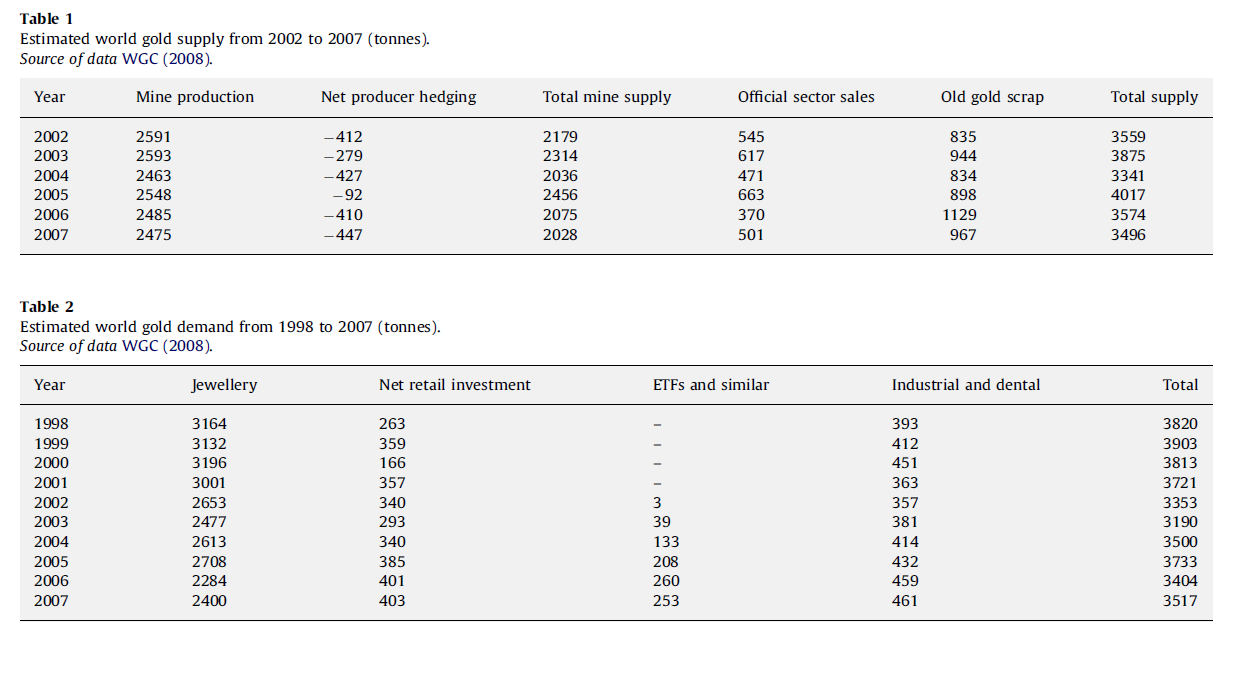 These tables give an idea of the main components of gold supply and demand over a several years recently.
These tables give an idea of the main components of gold supply and demand over a several years recently.