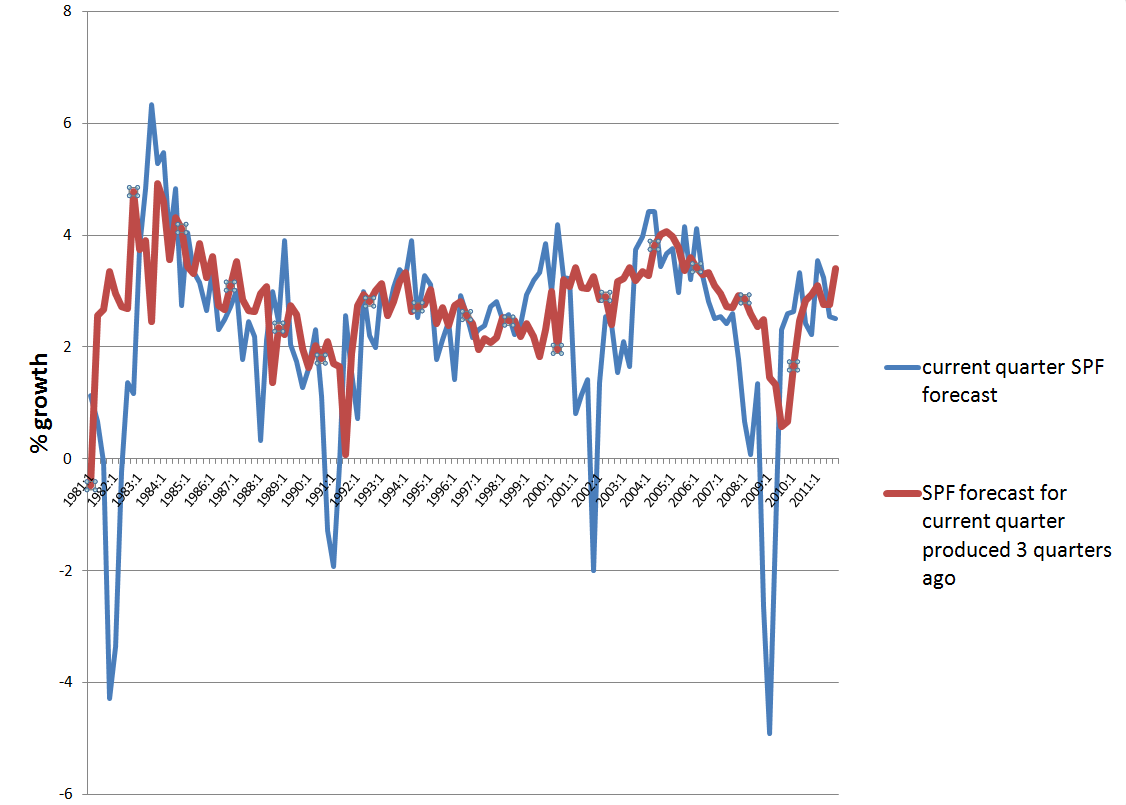
US and Global Economy
Bernanke sees headwinds fading as US poised for growth – happy talk about how good things are going to be as quantitative easing is “tapered.”
Slow Growth and Short Tails But Dr. Doom (Nouriel Roubini) is guardedly optimistic about 2014
The good news is that economic performance will pick up modestly in both advanced economies and emerging markets. The advanced economies, benefiting from a half-decade of painful private-sector deleveraging (households, banks, and non-financial firms), a smaller fiscal drag (with the exception of Japan), and maintenance of accommodative monetary policies, will grow at an annual pace closer to 1.9%. Moreover, so-called tail risks (low-probability, high-impact shocks) will be less salient in 2014. The threat, for example, of a eurozone implosion, another government shutdown or debt-ceiling fight in the United States, a hard landing in China, or a war between Israel and Iran over nuclear proliferation, will be far more subdued.
GOLDMAN: Here’s What Will Happen With GDP, Housing, The Fed, And Unemployment Next year Goldman Sachs chief economist Jan Hatzius writes: 10 Questions for 2014 – Jan Hatzius is very bullish on 2014!
Three big macro questions for 2014 Gavyn Davies – tapering QE, China, and the euro. Requires free registration to read.
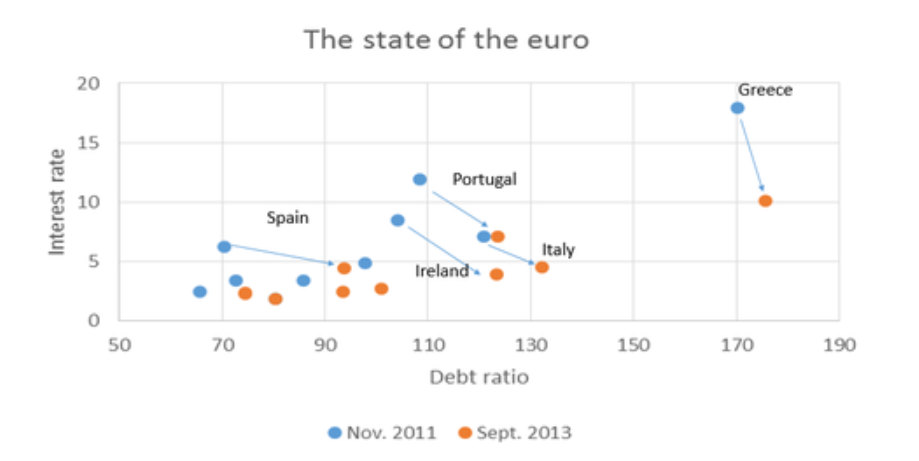
The State of the Euro, In One Graph From Paul Krugman, the point being that the EU’s austerity policies have significantly worsened the debt ratios of Spain, Portugal, Ireland, Greece, and Italy, despite lower interest rates. (Click to enlarge)
Technology
JCal’s 2014 predictions: Intense competition for YouTube and a shake up in online video economics
Rumblings in the YouTube community in the midst of tremendous growth in video productions – interesting.
Do disruptive technologies really overturn market leadership?
Discusses tests of the idea that ..such technologies have the characteristic that they perform worse on an important metric (or metrics) than current market leading technologies. Of course, if that were it, then the technologies could hardly be called disruptive and would be confined, at best, to niche uses.
The second critical property of such technologies is that while they start behind on key metrics, they improve relatively rapidly and eventually come to outperform existing technologies on many metrics. It is there that disruptive technologies have their bite. Initially, they are poor performers and established firms would not want to integrate them into their products as they would disappoint their customers who happen to be most of the current market. However, when performance improves, the current technologies are displaced and established firms want to get in on the game. The problem is that they may be too late. In other words, Christensen’s prediction was that established firms would have legitimate “blind spots” with regard to disruptive technologies leaving room open for new entrants to come in, adopt those technologies and, ultimately, displace the established firms as market leaders.
Big Data – A Big Opportunity for Telecom Players
Today with sharp increase in online and mobile shopping with use of Apps, telecom companies have access to consumer buying behaviours and preference which are actually being used with real time geo-location and social network analysis to target consumers. Hmmm.
5 Reasons Why Big Data Will Crush Big Research
Traditional marketing research or “big research” focuses disproportionately on data collection. This mentality is a hold-over from the industry’s early post-WWII boom –when data was legitimately scarce. But times have changed dramatically since Sputnik went into orbit and the Ford Fairlane was the No. 1-selling car in America.
Here is why big data is going to win.
Reason 1: Big research is just too small…Reason 2 : Big research lacks relevance… Reason 3: Big research doesn’t handle complexity well… Reason 4: Big research’s skill sets are outdated… Reason 5: Big research lacks the will to change…
I know “market researchers” who fit the profile in this Forbes article, and who are more or less lost in the face of the new extent of data and techniques for its analysis. On the other hand, I hear from the grapevine that many executives and managers can’t really see what the Big Data guys in their company are doing. There are success stories on the Internet (see the previous post here, for example), but this may be best case. Worst case is a company splurges on the hardware to implement Big Data analytics, and the team just comes up with gibberish – very hard to understand relationships with no apparent business value.
Some 2013 Recaps
Top Scientific Discoveries of 2013
Humankind goes interstellar ..Genome editing ..Billions and billions of Earths

Global warming: a cause for the pause ..See-through brains ..Intergalactic Neutrinos ..A new meat-eating mammal

Pesticide controversy grows ..Making organs from stem cells ..Implantable electronics ..Dark matter shows up — or doesn’t ..Fears of the fathers
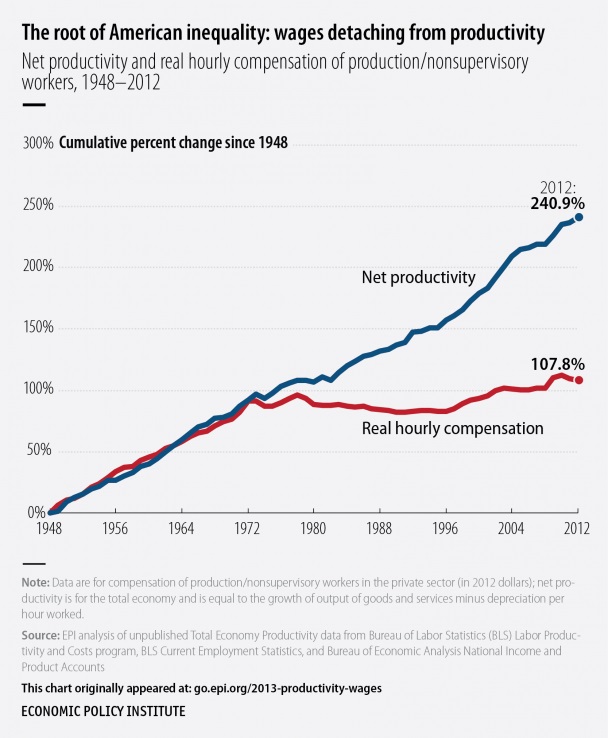
The 13 Most Important Charts of 2013
And finally, a miscellaneous item. Hedge funds apparently do beat the market, or at least companies operating in the tail of the performance distribution show distinctive characteristics.
How do Hedge Fund “Stars” Create Value? Evidence from Their Daily Trades
I estimate hedge fund performance by computing calendar-time transaction portfolios (see, e.g., Seasholes and Zhu, 2010) with holding periods ranging from 21 to 252 days. Across all holding periods, I find no evidence that the average or median hedge fund outperforms, after accounting for trading commissions. However, I find significant evidence of outperformance in the right-tail of the distribution. Specifically, bootstrap simulations indicate that the annual performance of the top 10-30% of hedge funds cannot be explained by luck. Similarly, I find that superior performance persists. The top 30% of hedge funds outperform by a statistically significant 0.25% per month over the subsequent year. In sharp contrast to my hedge fund findings, both bootstrap simulations and performance persistence tests fail to reveal any outperformance among non-hedge fund institutional investors….
My remaining tests investigate how outperforming hedge funds (i.e., “star” hedge funds) create value. My main findings can be summarized as follows. First, star hedge funds’ profits are concentrated over relatively short holding periods. Specifically, more than 25% (50%) of star hedge funds’ annual outperformance occurs within the first month (quarter) after a trade. Second, star hedge funds tend to be short-term contrarians with small price impacts. Third, the profits of star hedge funds are concentrated in their contrarian trades. Finally, the performance persistence of star hedge funds is substantially stronger among funds that follow contrarian strategies (or funds with small price impacts) and is not at all present for funds that follow momentum strategies (or funds with large price impacts).