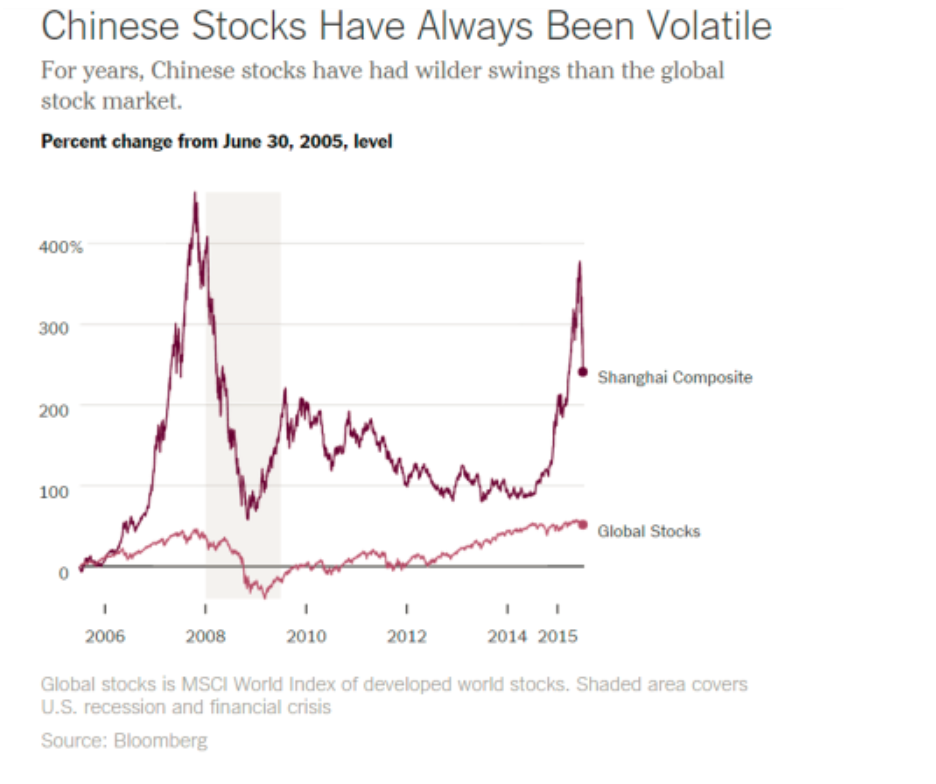
The resounding “No” vote today (Sunday, July 5) by Greeks vis a vis new austerity proposals of the European Commission and European Central Bank (ECB) is pivotal. The immediate task at hand this week is how to avoid or manage financial contagion and whether and how to prop up the Greek banking system to avoid complete collapse of the Greek economy.

Thousands celebrate Greece’s ‘No’ vote despite uncertainty ahead
Greece or, more formally, the Hellenic Republic, is a nation of about 11 million – maybe 2 percent of the population of the European Union (about 500 million). The country has a significance out of proportion to its size as an icon of many of the ideas of western civilization – such as “democracy” and “philosophy.”
But, if we can abstract momentarily from the human suffering involved, Greek developments have everything to do with practical and technical issues in forecasting and economic policy. Indeed, with real failures of applied macroeconomic forecasting since 2010.
Fiscal Multipliers
What is the percent reduction in GDP growth that is likely to be associated with reductions in government spending? This type of question is handled in the macroeconomic forecasting workshops – at the International Monetary Fund (IMF), the ECB, German, French, Italian, and US government agencies, and so forth – through basically simple operations with fiscal multipliers.
The Greek government had been spending beyond its means for years, both before joining the EU in 2001 and after systematically masking these facts with misleading and, in some cases, patently false accounting.
Then, to quote the New York Times,
Greece became the epicenter of Europe’s debt crisis after Wall Street imploded in 2008. With global financial markets still reeling, Greece announced in October 2009 that it had been understating its deficit figures for years, raising alarms about the soundness of Greek finances. Suddenly, Greece was shut out from borrowing in the financial markets. By the spring of 2010, it was veering toward bankruptcy, which threatened to set off a new financial crisis. To avert calamity, the so-called troika — the International Monetary Fund, the European Central Bank and the European Commission — issued the first of two international bailouts for Greece, which would eventually total more than 240 billion euros, or about $264 billion at today’s exchange rates. The bailouts came with conditions. Lenders imposed harsh austerity terms, requiring deep budget cuts and steep tax increases. They also required Greece to overhaul its economy by streamlining the government, ending tax evasion and making Greece an easier place to do business.…
The money was supposed to buy Greece time to stabilize its finances and quell market fears that the euro union itself could break up. While it has helped, Greece’s economic problems haven’t gone away. The economy has shrunk by a quarter in five years, and unemployment is above 25 percent.
In short, the austerity policies imposed by the “Troika” – the ECB, the European Commission, and the IMF – proved counter-productive. Designed to release funds to repay creditors by reducing government deficits, insistence on sharp reductions in Greek spending while the nation was still reeling from the global financial crisis led to even sharper reductions in Greek production and output – and thus tax revenues declined faster than spending.
Or, to put this in more technical language, policy analysts made assumptions about fiscal multipliers which simply were not borne out by actual developments. They assumed fiscal multipliers on the order of 0.5, when, in fact, recent meta-studies suggest they can be significantly greater than 1 in magnitude and that multipliers for direct transfer payments under strapped economic conditions grow by multiples of their value under normal circumstances.
Problems with fiscal multipliers used in estimating policy impacts were recognized some time ago – see for example Growth Forecast Errors and Fiscal Multipliers the IMF Working Paper authored by Oliver Blanchard in 2013.
Also, Simon Wren-Lewis, from Oxford University, highlights the IMF recognition that they “got the multipliers wrong” in his post How a Greek drama became a global tragedy from mid-2013.
However, at the negotiating table with the Greeks, and especially with their new, Left-wing government, the niceties of amending assumptions about fiscal multipliers were lost on the hard bargaining that has taken place.
Again, Wren-Lewis is interesting in his Greece and the political capture of the IMF. The creditors were allowed to demand more and sterner austerity measures, as well as fulfillment of past demands which now seem institutionally impossible – prior to any debt restructuring.
IMF Calls for 50 Billion in New Loans and Debt Restructuring for Greece
Just before to the Greek vote, on July 2, the IMF released a “Preliminary Draft Debt Sustainability Analysis.”
This clearly states Greek debt is not sustainable, given the institutional realities in Greece and deterioration of Greek economic and financial indicators, and calls for immediate debt restructuring, as well as additional funds ($50 billion) to shore up the Greek banks and economy.
There is a report that Europeans tried to block IMF debt report on Greece, viewing it as too supportive of the Greek government position and a “NO” vote on today’s referendum.
The IMF document considers that,
If grace periods and maturities on existing European loans are doubled and if new financing is provided for the next few years on similar concessional terms, debt can be deemed to be sustainable with high probability. Underpinning this assessment is the following: (i) more plausible assumptions—given persistent underperformance—than in the past reviews for the primary surplus targets, growth rates, privatization proceeds, and interest rates, all of which reduce the downside risk embedded in previous analyses. This still leads to gross financing needs under the baseline not only below 15 percent of GDP but at the same levels as at the last review; and (ii) delivery of debt relief that to date have been promises but are assumed to materialize in this analysis.
Some may view this analysis from a presumed moral high ground – fixating on the fact that Greeks proved tricky about garnering debt and profligate in spending in the previous decade.
But, unless decision-makers are intent upon simply punishing Greece, at risk of triggering financial crisis, it seems in the best interests of everyone to consider how best to proceed from this point forward.
And the idea of cutting spending and increasing taxes during an economic downturn and its continuing aftermath should be put to rest as another crackpot idea whose time has passed.