The thing I like about forecasting is that it is operational, rather than merely theoretical. Of course, you are always wrong, but the issue is “how wrong?” How close do the forecasts come to the actuals?
I have been toiling away developing methods to forecast stock market prices. Through an accident of fortune, I have come on an approach which predicts stock prices more accurately than thought possible.
After spending hundreds of hours over several months, I am ready to move beyond “backtesting” to provide forward-looking forecasts of key stocks, stock indexes, and exchange traded funds.
For starters, I’ve been looking at QQQ, the PowerShares QQQ Trust, Series 1.
Invesco describes this exchange traded fund (ETF) as follows:
PowerShares QQQ™, formerly known as “QQQ” or the “NASDAQ- 100 Index Tracking Stock®”, is an exchange-traded fund based on the Nasdaq-100 Index®. The Fund will, under most circumstances, consist of all of stocks in the Index. The Index includes 100 of the largest domestic and international nonfinancial companies listed on the Nasdaq Stock Market based on market capitalization. The Fund and the Index are rebalanced quarterly and reconstituted annually.
This means, of course, that QQQ has been tracking some of the most dynamic elements of the US economy, since its inception in 1999.
In any case, here is my forecast, along with tracking information on the performance of my model since late January of this year.
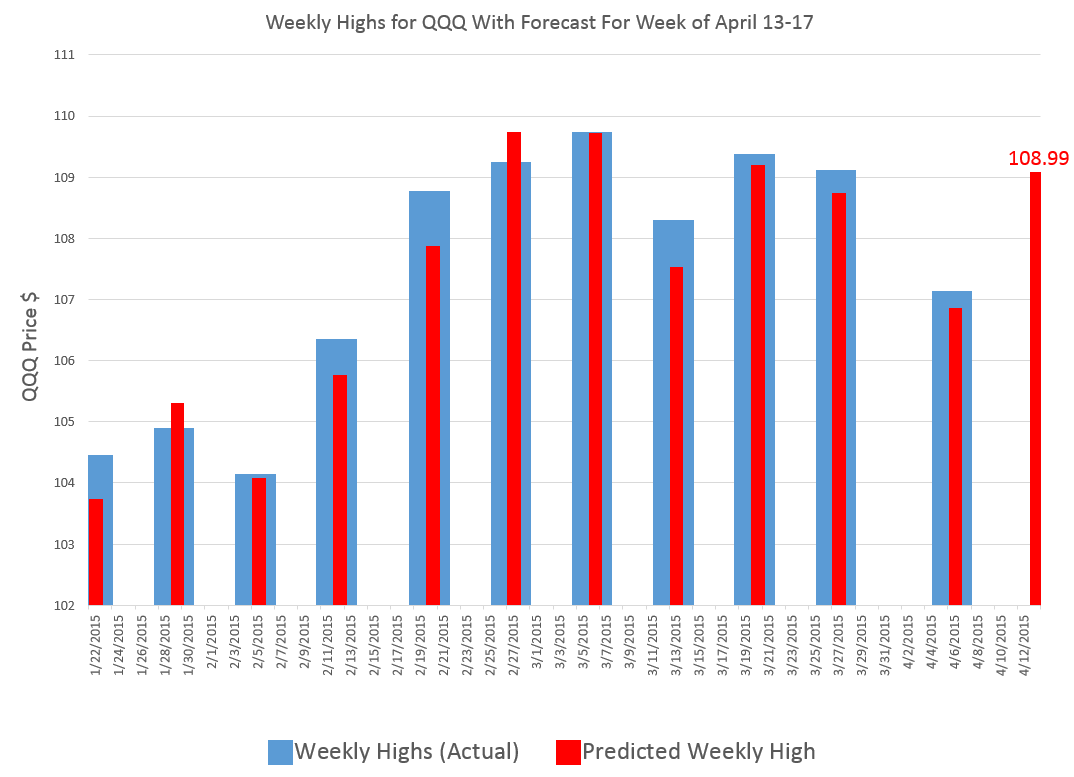
The time of this blog post is the morning of April 13, 2015.
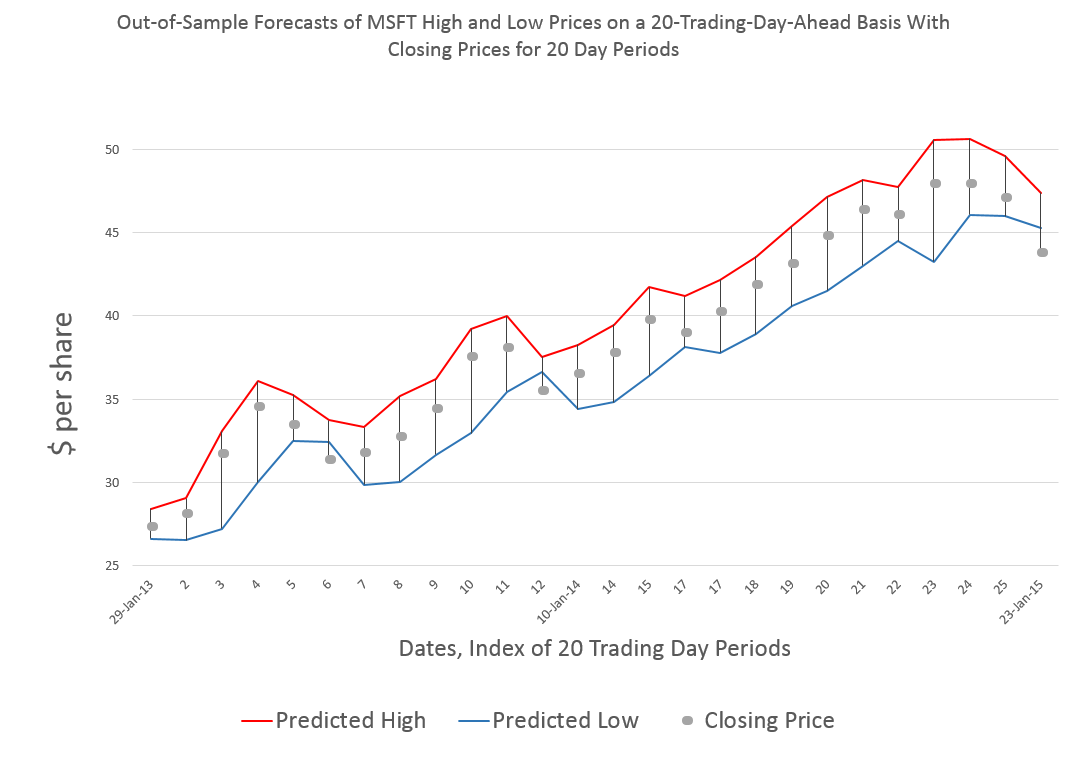
My algorithms indicate that the high for QQQ this week will be around $109 or, more precisely, $108.99.
So this is, in essence, a five day forecast, since this high price can occur in any of the trading days of this week.
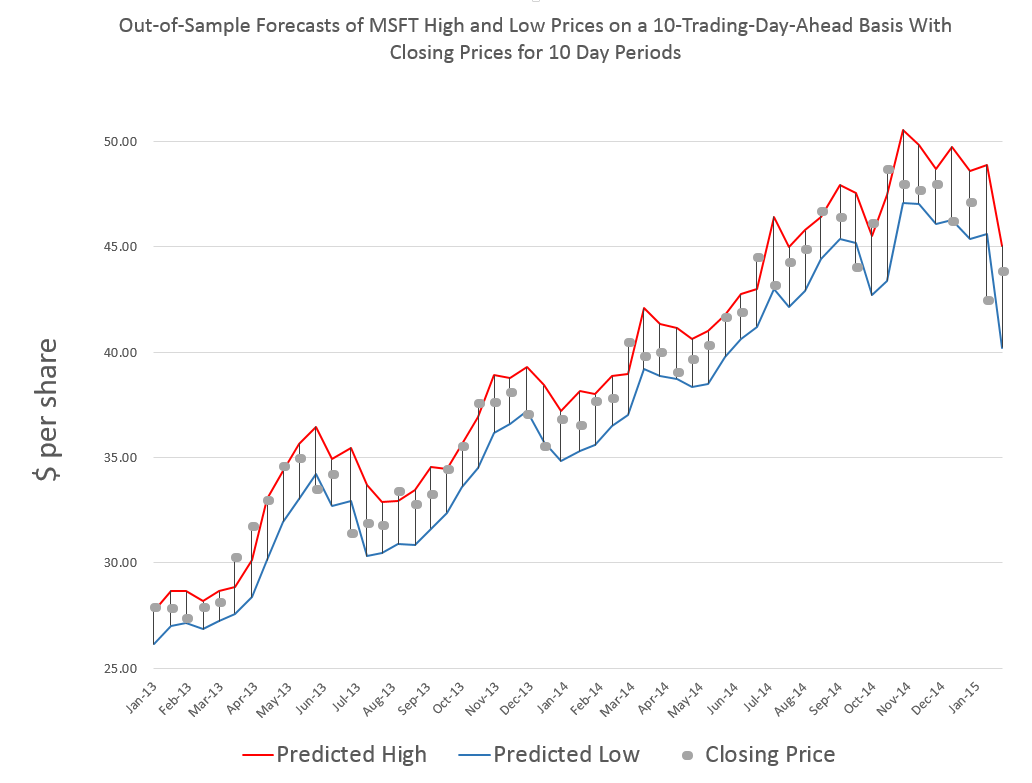
The chart above shows backtests for the algorithm for ten weeks. The forecast errors are all less than 0.65% over this history with a mean absolute percent error (MAPE) of 0.34%.
So that’s what I have today, and count on succeeding installments looking back and forward at the beginning of the next several weeks (Monday), insofar as my travel schedule allows this.
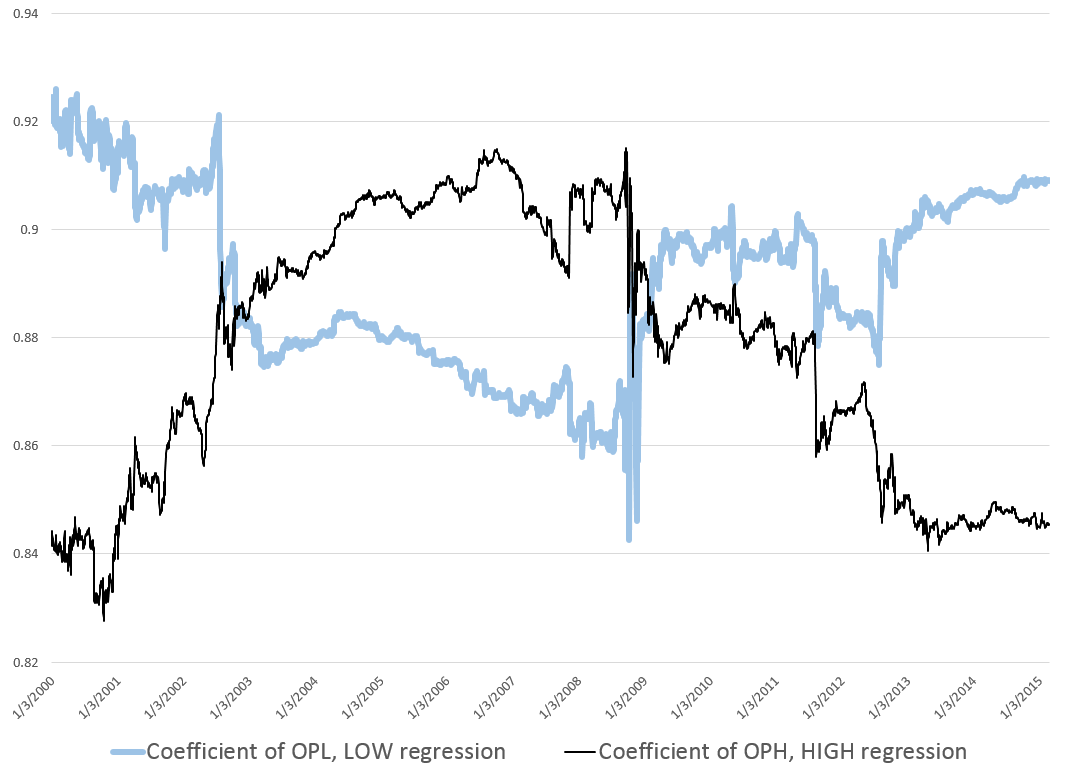
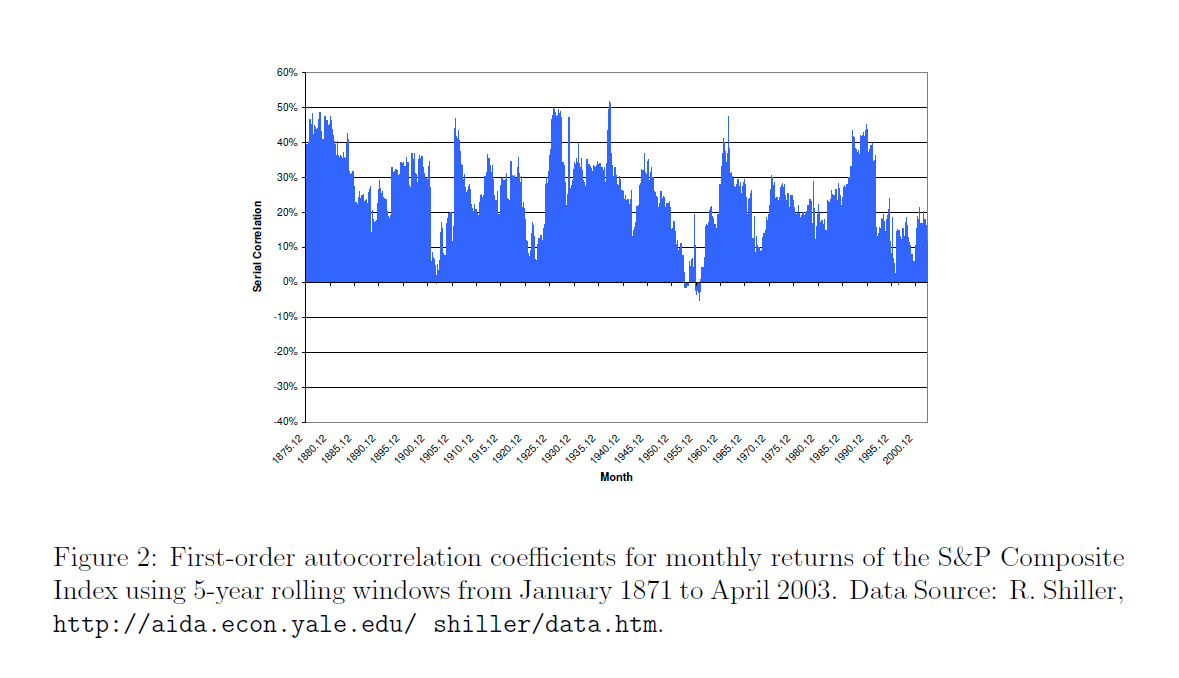
Also, my initial comments on this post appear to offer a dig against theory, but that would be unfair, really, since “theory” – at least the theory of new forecasting techniques and procedures – has been very important in my developing these algorithms. I have looked at residuals more or less as a gold miner examines the chat in his pan. I have considered issues related to the underlying distribution of stock prices and stock returns – NOTE TO THE UNINITIATED – STOCK PRICES ARE NOT NORMALLY DISTRIBUTED. There is indeed almost nothing about stocks or stock returns which is related to the normal probability distribution, and I think this has been a huge failing of conventional finance, the Black Scholes Theorem, and the like.
So theory is important. But you can’t stop there.
This should be interesting. Stay tuned. I will add other securities in coming weeks, and provide updates of QQQ forecasts.
Readers interested in the underlying methods can track back on previous blog posts (for example, Pvar Models for Forecasting Stock Prices or Time-Varying Coefficients and the Risk Environment for Investing).