Over the Holidays – while frustrated in posting by a software glitch – I looked at the whole “shallow data issue” in light of a new technique I’ve learned called bagging.
Bottom line, using spreadsheet simulations, I can show bagging radically reduces out-of-sample forecast error, in a situation typical for a lot business forecasting – where there are just a few workable observations, quite a few candidate drivers or explanatory variables, and a lot of noise in the data.
Here is a comparison of the performance of OLS regression and bagging with out-of-sample data generated with the same rules which create the “sample data” in the example spreadsheet shown below.
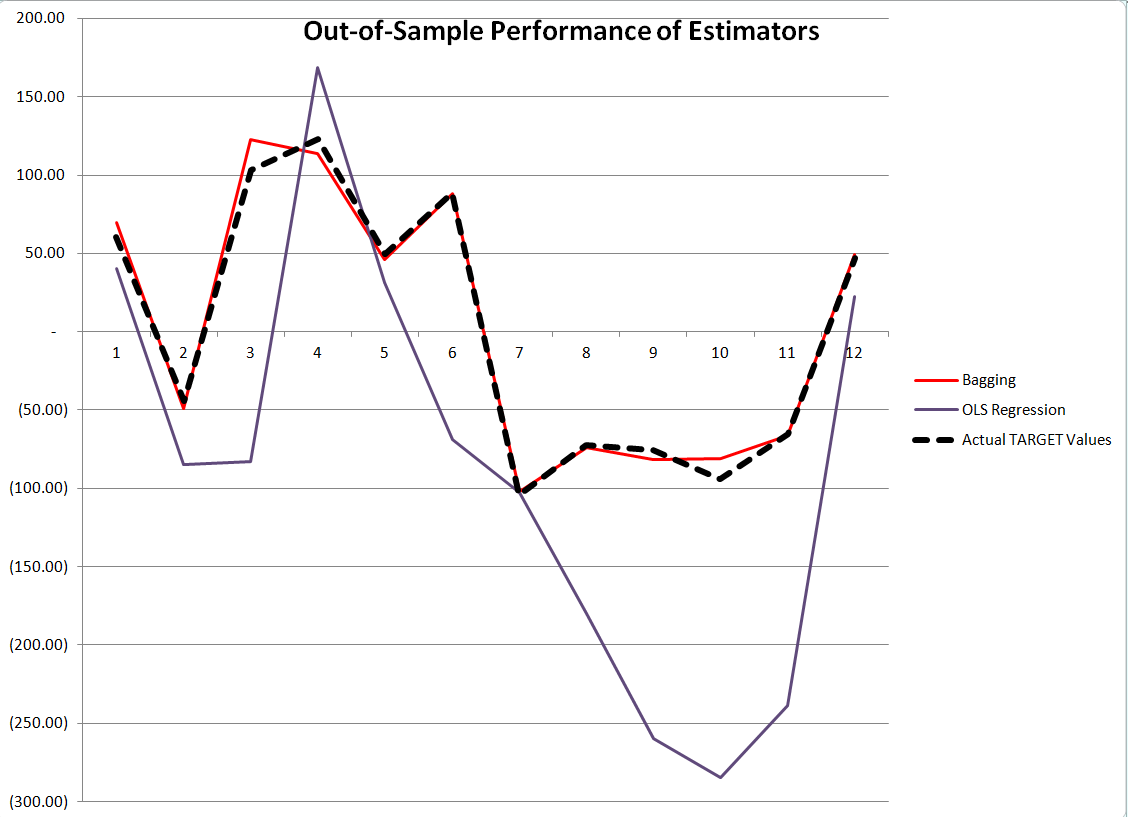
The contrast is truly stark. Although, as we will see, the ordinary least squares (OLS) regression has an R2 or “goodness of fit” of 0.99, it does not generalize well out-of-sample, producing the purple line in the graph with 12 additional cases or observations. Bagging the original sample 200 times and re-estimating OLS regression on the bagged samples, then averaging the regression constants and coefficients, produces a much tighter fit on these out-of-sample observations.
Example Spreadsheet
The spreadsheet below illustrates 12 “observations” on a TARGET or dependent variable and nine (9) explanatory variables, x1 through x9.
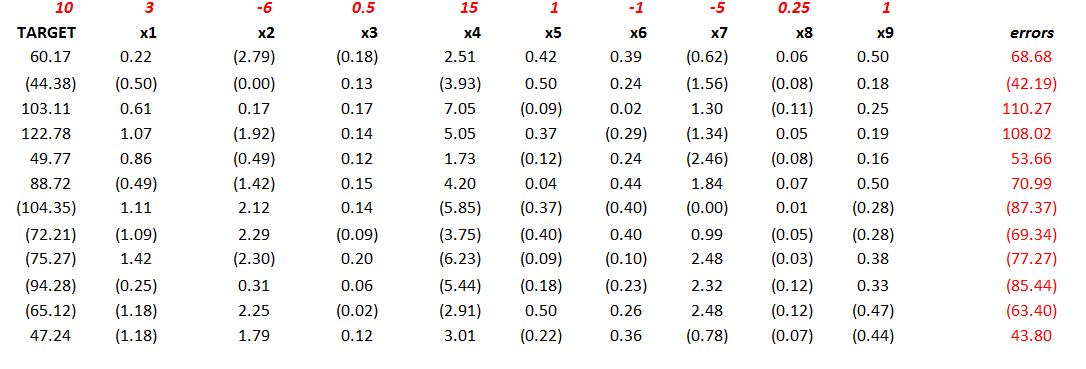
The top row with numbers in red lists the “true” values of these explanatory variables or drivers, and the column of numbers in red on the far right are the error terms (which are generated by a normal distribution with zero mean and standard deviation of 50).
So if we multiply 3 times 0.22 and add -6 times -2.79 and so forth, adding 68.68 at the end, we get the first value of the TARGET variable 60.17.
While this example is purely artificial, an artifact, one can imagine that these numbers are first differences – that is the current value of a variable minus its preceding value. Thus, the TARGET variable might record first differences in sales of a product quarter by quarter. And we suppose forecasts for x1 through x9 are available, although not shown above. In fact, they are generated in simulations with the same generating mechanisms utilized to create the sample.
Using the simplest multivariate approach, the ordinary least squares (OLS) regression, displayed in the Excel format, is –
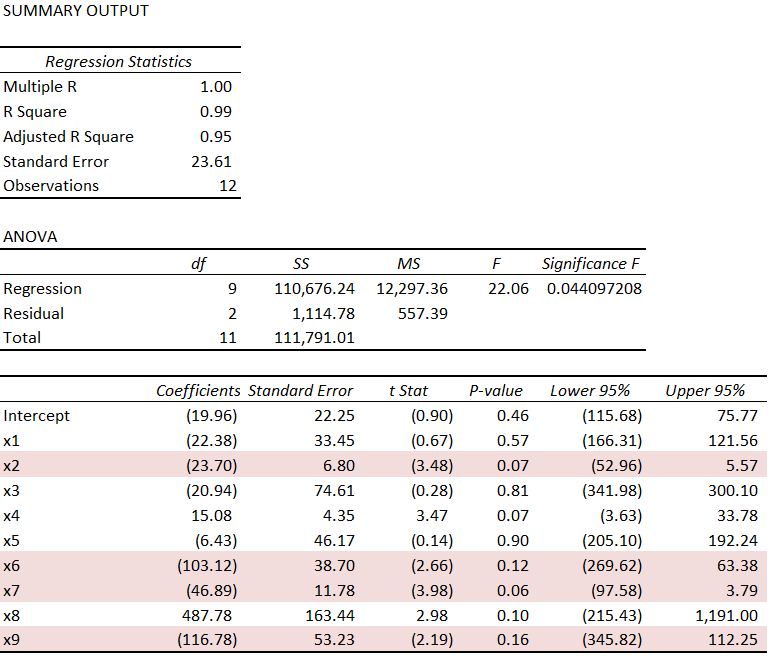
There’s useful information in this display, often the basis of a sort of “talk-through” the regression result. Usually, the R2 is highlighted, and it is terrific here, “explaining” 99 percent of the variation in the data, in, that is, the 12 in-sample values for the TARGET variable. Furthermore, four explanatory variables have statistically significant coefficients, judged by their t-statistics – x2, x6, x7, and x9. These are highlighted in a kind of purple in the display.
Of course, the estimated values of x1 through x9 are, for the most part, numerically quite different than the true values of the constant term and coefficients {10, 3, -6, 0.5, 15, 1, -1, -5, 0.25, 1}. Nevertheless, because of the large variances or standard errors of the estimates, as noted above some estimated coefficients are within a 95 percent confidence interval of these true values. It’s just that the confidence intervals are very wide.
The in-sample predicted values are accurate, generally speaking. These loopy coefficient estimates essentially balance one another off in-sample.
But it’s not the in-sample performance we are interested in, but the out-of-sample performance. And we want to compare the out-of-sample performance of this OLS regression estimate with estimates of the coefficients and TARGET variable produced by ridge regression and bagging.
Bagging
Bagging [bootstrap aggregating] was introduced by Breiman in the 1990’s to reduce the variance of predictors. The idea is that you take N bootstrap samples of the original data, and with each of these samples, estimate your model, creating, in the end, an ensemble prediction.
Bootstrap sampling draws random samples with replacement from the original sample, creating other samples of the same size. With 12 cases or observations on the TARGET and explanatory variables there are a large number of possible random samples of these 12 cases drawn with replacement; in fact, given nine explanatory variables and the TARGET variable, there are 129 or somewhat more than 5 billion distinct samples, 12 of which, incidentally, are comprised of exactly the same case drawn repeatedly from the original sample.
A primary application of bagging has been in improving the performance of decision trees and systems of classification. Applications to regression analysis seem to be more or less an after-thought in the literature, and the technique does not seem to be in much use in applied business forecasting contexts.
Thus, in the spreadsheet above, random draws with replacement are taken of the twelve rows of the spreadsheet (TARGET and drivers) 200 times, creating 200 samples. An ordinary least squares regression is estimated over each regression, and the constant and parameter estimates are averaged at the end of the process.
Here is a comparison of the estimated coefficients from Bagging and OLS, compared with the true values.

There’s still variation of the parameter estimates from the true values with bagging, but the variance of the error process (50) is, by design, high. For example, most of the value of TARGET is from the error process, so this is noisy data.
Discussion
Some questions. For example – Are there specific features of the problem presented here which tip the results markedly in favor of bagging? What are the criteria for determining whether bagging will improve regression forecasts? Another question regards the ease or difficulty of bagging regressions in Excel.
The criterion for bagging to deliver dividends is basically parameter instability over the sample. Thus, in the problem here, deleting any observation from the 12 cases and re-estimating the regression results in big changes to estimated parameters. The basic reason is the error terms constitute by far the largest contribution to the value of TARGET for each case.
In practical forecasting, this criterion, which not very clearly defined, can be explored, and then comparisons with regard to actual outcomes can be studied. Thus, estimate the bagged regression forecast, wait a period, and compare bagged and simple OLS forecasts. Substantial improvement in forecast accuracy, combined with parameter instability in the sample, would seem to be a smoking gun.
Apart from the large contribution of the errors or residuals to the values of TARGET, the other distinctive feature of the problem presented here is the large number of predictors in comparison with the number of cases or observations. This, in part, accounts for the high coefficient of determination or R2, and also suggests that the close in-sample fit and poor out-of-sample performance are probably related to “over-fitting.”