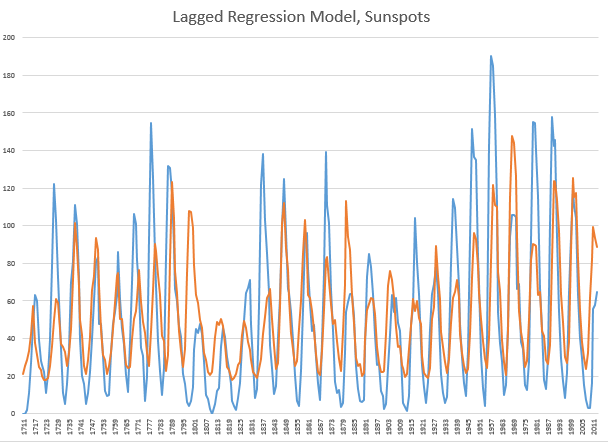
In 1927, the Russian statistician Eugen Slutsky wrote a classic article called ‘The summation of random causes as the source of cyclic processes,’ a short summary of which is provided by Barnett –
If the variables that were taken to represent business cycles were moving averages of past determining quantities that were not serially correlated – either real-world moving averages or artificially generated moving averages – then the variables of interest would become serially correlated, and this process would produce a periodicity approaching that of sine waves
It’s possible to illustrate this phenomena with rolling sums of the digits of pi (π). The following chart illustrates the wave-like result of charting rolling sums of ten consecutive digits of pi.
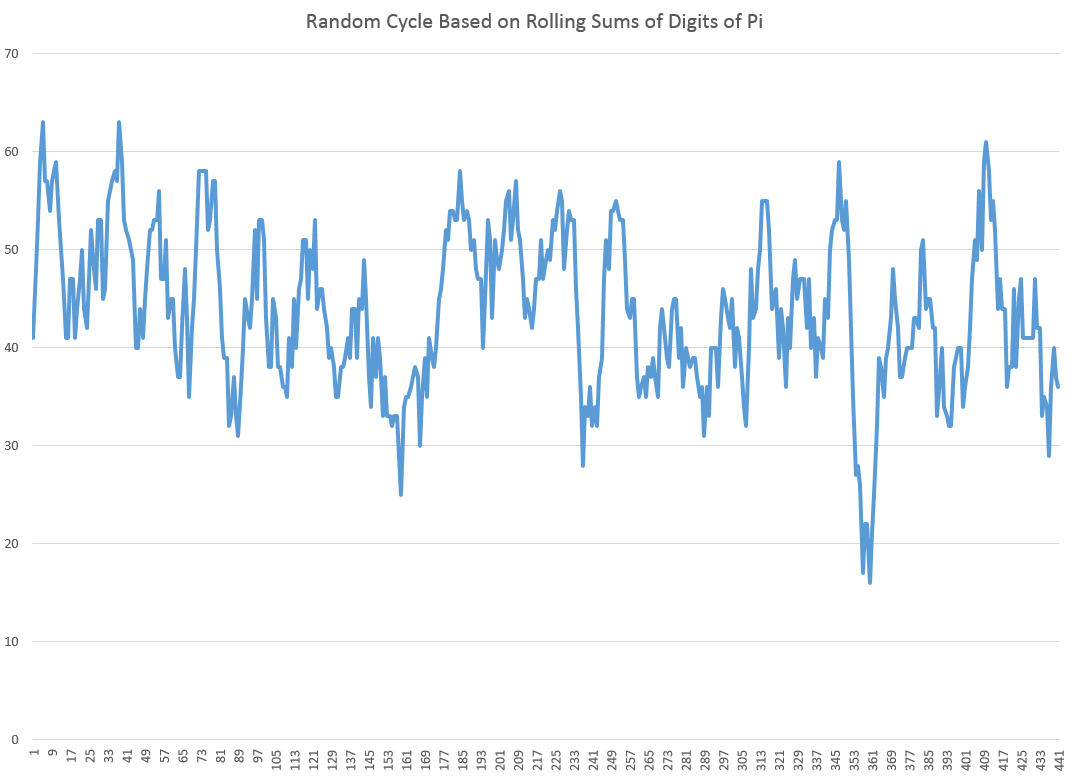
So to be explicit, I downloaded the first 450 digits of pi, took them apart, and then graphed the first 440 rolling sums.
The wave-like pattern Illustrates a random cycle.
Forecasting Random Cycles
If we consider this as a time series, each element xk is the following sum,
xk = dk+dk-1+..+dk-10
where dj is the jth digit in the decimal expansion of pi to the right of the initial value of 3.
Now, apparently, it is not proven that the digits of pi are truly random, although one can show that, so far as we can compute, these digits are described by a uniform distribution.
As far as we know, the probability that the next digit will be any digit from 0 to 9 is 1/10=0.1
So as one moves through the digits of pi, generating rolling sums, each new sum means the addition of a new digit, which is unknown and can only be predicted up to its probability. And, at the same time, a digit at the beginning of the preceding sum drops away in the new sum.
Note also that we can always deduce what the series of original digits is, given a series of these rolling sums up to some point.
So the issue is whether the new digit added to the next sum is greater than, equal to, or less than the leading digit of the current sum – which is where we now stand in this sort of analysis. This determines whether the next rolling sum will be greater than, equal to, or less than the current sum.
Here’s where the forecasts can be produced. If the rolling sum is large enough, approaching or equal to 90, there is a high probability that the next rolling sum will be lower, leading to this wave-like pattern. Conversely, if the rolling sum is near zero, the chances are the subsequent sum will be larger. And all this arm-waving can be complemented by exact probabilistic calculations.
Some Ultimate Thoughts
It’s interesting we are really dealing here with a random cycle. That’s proven by the fact that, at any time, the series could go flat-line or trace out some other kind of weird movement.
Thus, the quasi-periodic aspect can be violated for as many periods as you might choose, if one arrives at a run of the same digit in the expansion of pi.
This reminds me of something George Gamow wrote in one of his popular books, where he discusses thermodynamics and the random movement of atoms and molecules in the air of a room. Gamow observes it is entirely possible all the air by chance will congregate in one corner, leaving a vacuum elsewhere. Of course, this is highly improbable.
The only difference would be that there are a finite number of atoms and molecules in the air of any room, but, presumably, an infinite number of digits in the expansion of pi.
The morale of the story is, in any case, to be cautious in imposing a fixed cycle on this type of series.