
Researchers at Microsoft Research in the UK and Cambridge University report some fascinating and potentially useful results on crowdsourcing, based on a study of aggregating questions from a standard IQ test on Amazon’s Mechanical Turk (AMT).
The AMT site provides a place where workers can find problems that requesters have set up for crowdsourcing.
The introductory page to the site looks like this (click to enlarge).
So here’s an interesting way for people to make some money working from home, at their own hours, and yet stay busy. I’d like to look more deeply into this in a future post, but what these Crowd IQ researchers did is divvy up the questions from a widely utilized IQ test on the AMT site. They studied the effects of changing several parameters on their measures of Crowd IQ, but basically found that, with five or more reputable workers in a group, the Crowd IQ was usually higher than that of the individual workers in the group.
The Abstract for their 2012 study Crowd IQ: Measuring the Intelligence of Crowdsourcing Platforms describes the research and findings succinctly:
We measure crowdsourcing performance based on a standard IQ questionnaire, and examine Amazon’s Mechanical Turk (AMT) performance under different conditions. These include variations of the payment amount offered, the way incorrect responses affect workers’ reputations, threshold reputation scores of participating AMT workers, and the number of workers per task. We show that crowds composed of workers of high reputation achieve higher performance than low reputation crowds, and the effect of the amount of payment is non-monotone—both paying too much and too little affects performance. Furthermore, higher performance is achieved when the task is designed such that incorrect responses can decrease workers’ reputation scores. Using majority vote to aggregate multiple responses to the same task can significantly improve performance, which can be further boosted by dynamically allocating workers to tasks in order to break ties.
The IQ test is Raven’s Standard Progressive Matrices (SPM). If you want to take the test, look here.
SPM is a nonverbal, multiple-choice intelligence test based on the theory of general ability. The general setup is as in the following example.

Free riders are an interesting problem in a site like the Mechanical Turk. So, if people get paid by the number of correct answers, some simply select responses at random to maximize the speed at which they can put up answers. Because of this, AMT has a reputation mechanism indicating the expected quality of work of a worker, based on his or her past performance.
This research is has real-world implications. For example, increasing the payment for tasks too much results in actually diminuishing the quality of the answers, for a variety of reasons the authors consider.
The “workers” in this AMT-based study did not consult with each other about the answers, but were grouped into teams somehow by the researchers.
Here is a chart showing the increase in crowd IQ with the number of people in the group.
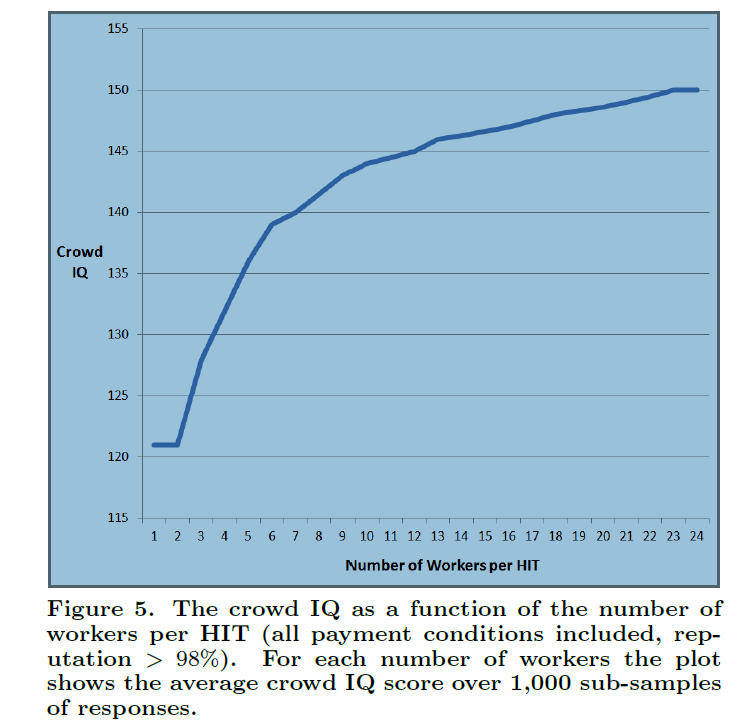
Here a HIT refers to a Human Intelligence Task.
Recommendations
First, experiment and monitor the performance. Our results suggest that relatively small changes to the parameters of the task may result in great changes in crowd performance. Changing parameters of the task (e.g. reward, time limits, reputation rage) and observing changes in performance may allow you to greatly increase performance. Second, make sure to threaten workers’ reputation by emphasizing that their solutions will be monitored and wrong responses rejected. Obviously, in a real-world setting it may be hard to detect free-riders without using a “gold-set” of test questions to which the requester already knows the correct response. However, designing and communicating HIT rejection conditions can discourage free riding or make it risky and more difficult. For instance, in the case of translation tasks requesters should determine what is not acceptable (e.g. using Google Translate) and may suggest that the response quality would be monitored and solutions of low quality would be rejected. Third, do not over-pay. Although the reward structure obviously depends on the task at hand and the expected amount of effort required to solve it, our results suggest that pricing affects not only the ability to s source enough workers to perform the task but also the quality of the obtained results. Higher rewards are likely to encourage a free-riding behavior and may affect the cognitive abilities of workers by increasing psychological pressure. Thus, for long term projects or tasks that are run repeatedly in a production environment, we believe it is worthwhile to experiment with the reward scheme in order to
find an optimum reward level. Fourth, aggregate multiple solutions to each HIT, preferably using an adaptive sourcing scheme. Even the simplest aggregation method – majority voting – has a potential to greatly improve the quality of the solution. In the context of more complicated tasks, e.g. translations, requesters may consider a two-stage design in which they first request several solutions, and then use another batch of workers to vote for the best one. Additionally, requesters may consider inspecting the responses provided by individuals that often disagree with the crowd – they might be coveted geniuses or free-riders deserving rejection.
Interesting stuff, and makes you want to try crowdsourcing.