
I’ve posted on ridge regression and the LASSO (Least Absolute Shrinkage and Selection Operator) some weeks back.
Here I want to compare them in connection with variable selection where there are more predictors than observations (“many predictors”).
1. Ridge regression does not really select variables in the many predictors situation. Rather, ridge regression “shrinks” all predictor coefficient estimates toward zero, based on the size of the tuning parameter λ. When ordinary least squares (OLS) estimates have high variability, ridge regression estimates of the betas may, in fact, produce lower mean square error (MSE) in prediction.
2. The LASSO, on the other hand, handles estimation in the many predictors framework and performs variable selection. Thus, the LASSO can produce sparse, simpler, more interpretable models than ridge regression, although neither dominates in terms of predictive performance. Both ridge regression and the LASSO can outperform OLS regression in some predictive situations – exploiting the tradeoff between variance and bias in the mean square error.
3. Ridge regression and the LASSO both involve penalizing OLS estimates of the betas. How they impose these penalties explains why the LASSO can “zero” out coefficient estimates, while ridge regression just keeps making them smaller. From
An Introduction to Statistical Learning

Similarly, the objective function for the LASSO procedure is outlined by An Introduction to Statistical Learning, as follows
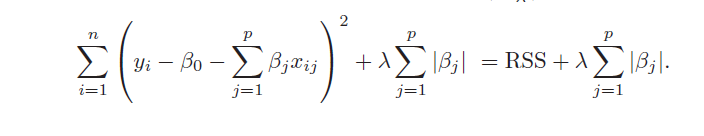
4. Both ridge regression and the LASSO, by imposing a penalty on the regression sum of squares (RWW) shrink the size of the estimated betas. The LASSO, however, can zero out some betas, since it tends to shrink the betas by fixed amounts, as λ increases (up to the zero lower bound). Ridge regression, on the other hand, tends to shrink everything proportionally.
5.The tuning parameter λ in ridge regression and the LASSO usually is determined by cross-validation. Here are a couple of useful slides from Ryan Tibshirani’s Spring 2013 Data Mining course at Carnegie Mellon.


6.There are R programs which estimate ridge regression and lasso models and perform cross validation, recommended by these statisticians from Stanford and Carnegie Mellon. In particular, see glmnet at CRAN. Mathworks MatLab also has routines to do ridge regression and estimate elastic net models.
Here, for example, is R code to estimate the LASSO.
lasso.mod=glmnet(x[train,],y[train],alpha=1,lambda=grid)
plot(lasso.mod)
set.seed(1)
cv.out=cv.glmnet(x[train,],y[train],alpha=1)
plot(cv.out)
bestlam=cv.out$lambda.min
lasso.pred=predict(lasso.mod,s=bestlam,newx=x[test,])
mean((lasso.pred-y.test)^2)
out=glmnet(x,y,alpha=1,lambda=grid)
lasso.coef=predict(out,type=”coefficients”,s=bestlam)[1:20,]
lasso.coef
lasso.coef[lasso.coef!=0]
What You Get
I’ve estimated quite a number of ridge regression and LASSO models, some with simulated data where you know the answers (see the earlier posts cited initially here) and other models with real data, especially medical or health data.
As a general rule of thumb, An Introduction to Statistical Learning notes,
..one might expect the lasso to perform better in a setting where a relatively small number of predictors have substantial coefficients, and the remaining predictors have coefficients that are very small or that equal zero. Ridge regression will perform better when the response is a function of many predictors, all with coefficients of roughly equal size.
The R program glmnet linked above is very flexible, and can accommodate logistic regression, as well as regression with continuous, real-valued dependent variables ranging from negative to positive infinity.
