So there’s a new kid on the block, really a former resident who moved back to the neighborhood with spiffy new toys – causal discovery.
Competitions and challenges give a flavor of this rapidly developing field – for example, the Causality Challenge #3: Cause-effect pairs, sponsored by a list of pre-eminent IT organizations and scientific societies (including Kaggle).
By way of illustration, B → A but A does not cause B – Why?
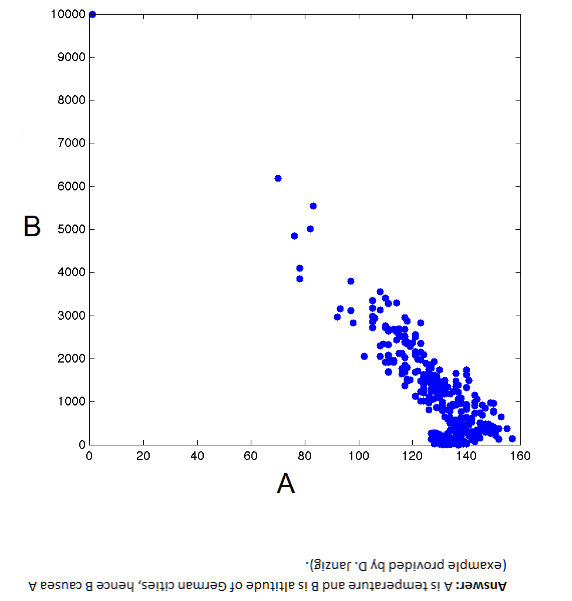
These data, as the flipped answer indicates, are temperature and altitude of German cities. So altitude causes temperature, but temperature obviously does not cause altitude.
The non-linearity in the scatter diagram is a clue. Thus, values of variable A above about 130 map onto more than one value of B, which is problematic from conventional definition of causality. One cause should not have two completely different effects, unless there are confounding variables.
It’s a little fuzzy, but the associated challenge is very interesting, and data pairs still are available.
We provide hundreds of pairs of real variables with known causal relationships from domains as diverse as chemistry, climatology, ecology, economy, engineering, epidemiology, genomics, medicine, physics. and sociology. Those are intermixed with controls (pairs of independent variables and pairs of variables that are dependent but not causally related) and semi-artificial cause-effect pairs (real variables mixed in various ways to produce a given outcome). This challenge is limited to pairs of variables deprived of their context.
Asymmetries As Clues to Causal Direction of Influence
The causal direction in the graph above is suggested by the non-invertibility of the functional relationship between B and A.
Another clue from reversing the direction of causal influence relates to the error distributions of the functional relationship between pairs of variables. This occurs when these error distributions are non-Gaussian, as Patrik Hoyer and others illustrate in Nonlinear causal discovery with additive noise models.
The authors present simulation and empirical examples.
Their first real-world example comes from data on eruptions of the Old Faithful geyser in Yellowstone National Park in the US.
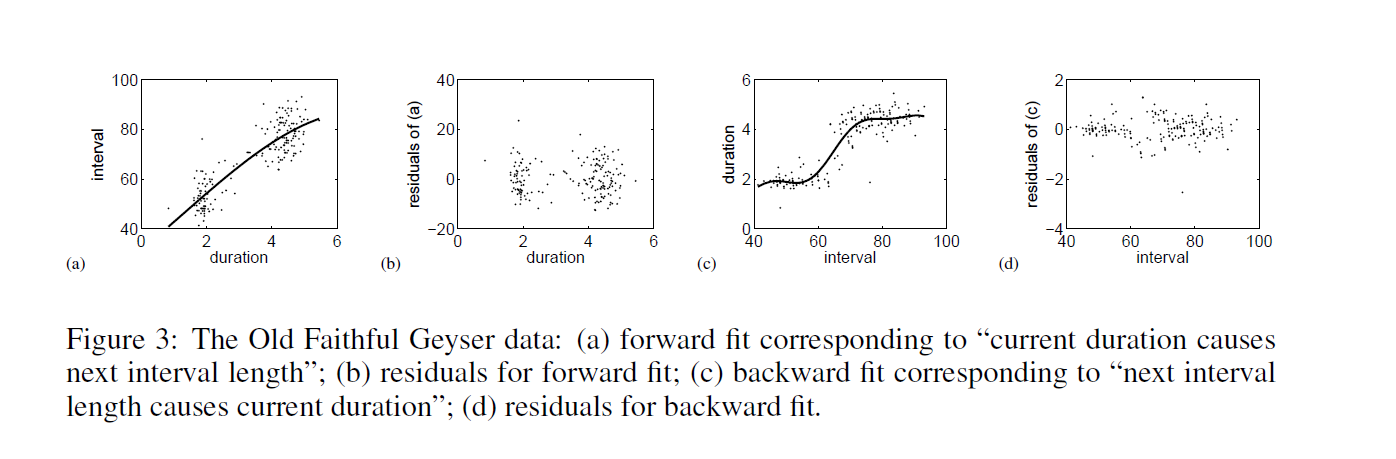 Hoyer et al write,
Hoyer et al write,
The first dataset, the “Old Faithful” dataset [17] contains data about the duration of an eruption and the time interval between subsequent eruptions of the Old Faithful geyser in Yellowstone National Park, USA. Our method obtains a p-value of 0.5 for the (forward) model “current duration causes next interval length” and a p-value of 4.4 x 10-9 for the (backward) model “next interval length causes current duration”. Thus, we accept the model where the time interval between the current and the next eruption is a function of the duration of the current eruption, but reject the reverse model. This is in line with the chronological ordering of these events. Figure 3 illustrates the data, the forward and backward fit and the residuals for both fits. Note that for the forward model, the residuals seem to be independent of the duration, whereas for the backward model, the residuals are clearly dependent on the interval length.
Then, they too consider temperature and altitude pairings.
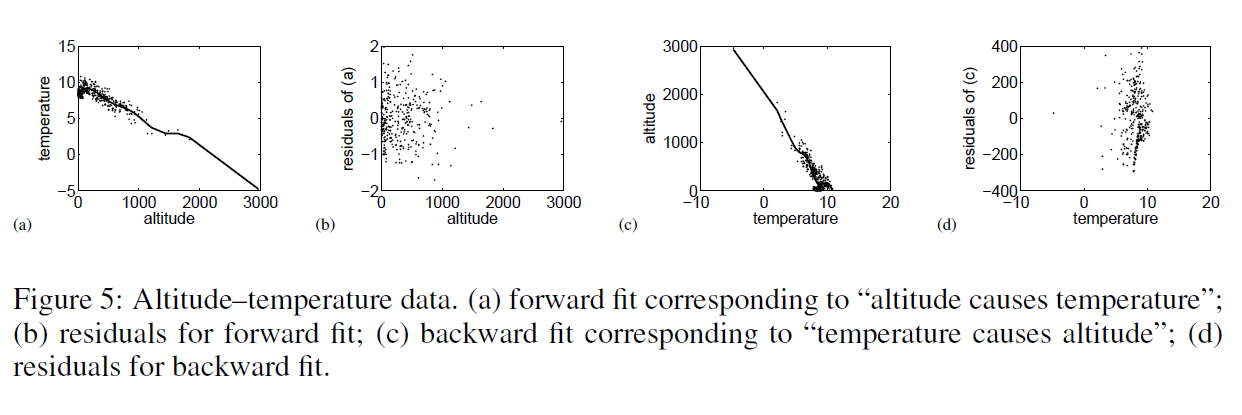 Here, the correct model – altitude causes temperature – results in a much more random scatter of residuals, than the reverse direction model.
Here, the correct model – altitude causes temperature – results in a much more random scatter of residuals, than the reverse direction model.
Patrik Hoyer and Aapo Hyvärinen are a couple of names from this Helsinki group of researchers whose papers are interesting to read and review.
One of the early champions of this resurgence of interest in causality works from a department of philosophy – Peter Spirtes. It’s almost as if the discussion of causal theory were relegated to philosophy, to be revitalized by machine learning and Big Data:
The rapid spread of interest in the last three decades in principled methods of search or estimation of causal relations has been driven in part by technological developments, especially the changing nature of modern data collection and storage techniques, and the increases in the processing power and storage capacities of computers. Statistics books from 30 years ago often presented examples with fewer than 10 variables, in domains where some background knowledge was plausible. In contrast, in new domains such as climate research (where satellite data now provide daily quantities of data unthinkable a few decades ago), fMRI brain imaging, and microarray measurements of gene expression, the number of variables can range into the tens of thousands, and there is often limited background knowledge to reduce the space of alternative causal hypotheses. Even when experimental interventions are possible, performing the many thousands of experiments that would be required to discover causal relationships between thousands or tens of thousands of variables is often not practical. In such domains, non-automated causal discovery techniques from sample data, or sample data together with a limited number of experiments, appears to be hopeless, while the availability of computers with increased processing power and storage capacity allow for the practical implementation of computationally intensive automated search algorithms over large search spaces.