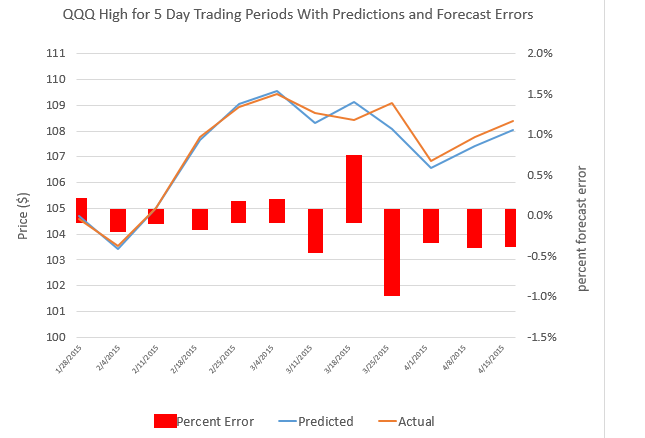
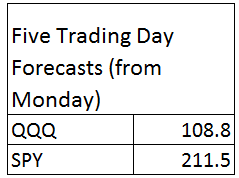
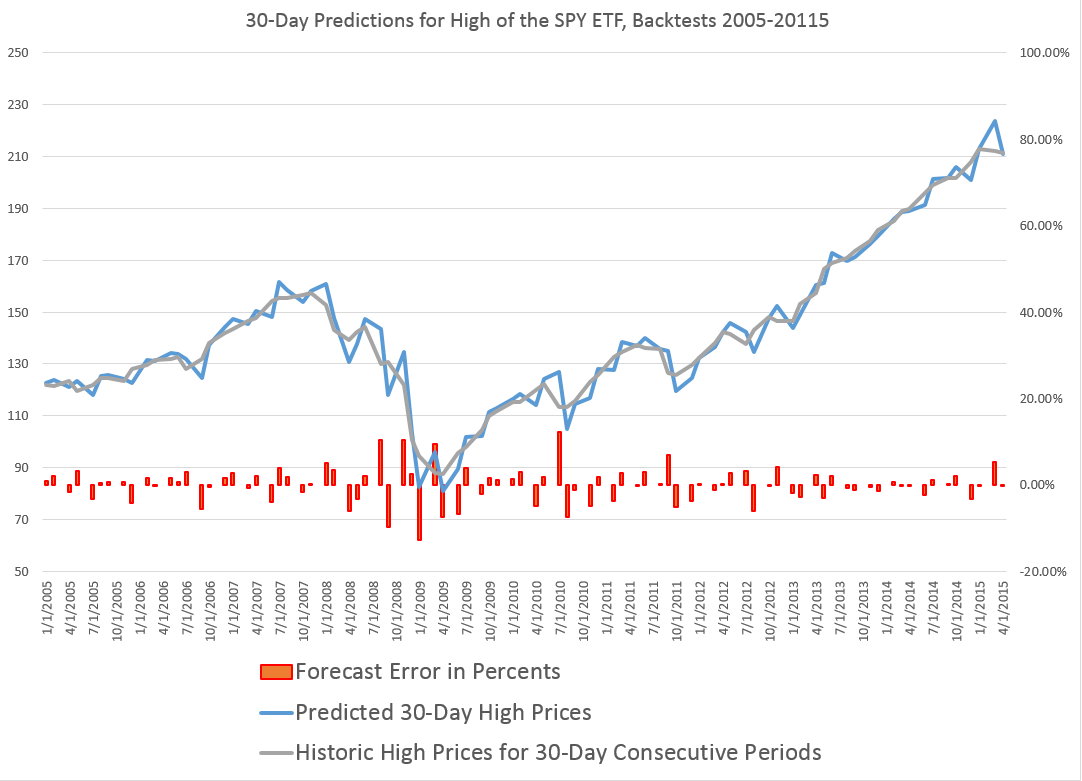
There is a topic I think you can call the “structure of randomness.” Power laws are included, as are various “arcsine laws” governing the probability of leads and changes in scores in competitive games and, of course, in winnings from gambling.
I ran onto a recent article showing how basketball scores follow arcsine laws.
Safe Leads and Lead Changes in Competitive Team Sports is based on comprehensive data from league games over several seasons in the National Basketball Association (NBA).
“..we find that many …statistical properties are explained by modeling the evolution of the lead time X as a simple random walk. More strikingly, seemingly unrelated properties of lead statistics, specifically, the distribution of the times t: (i) for which one team is leading..(ii) for the last lead change..(and (iii) when the maximal lead occurs, are all described by the ..celebrated arcsine law..”
The chart below shows the arcsine probability distribution function (PDF). This probability curve is almost the opposite or reverse of the widely known normal probability distribution. Instead of a bell-shape with a maximum probability in the middle, the arcsine distribution has the unusual property that probabilities are greatest at the lower and upper bounds of the range. Of course, what makes both curves probability distributions is that the area they span adds up to 1.
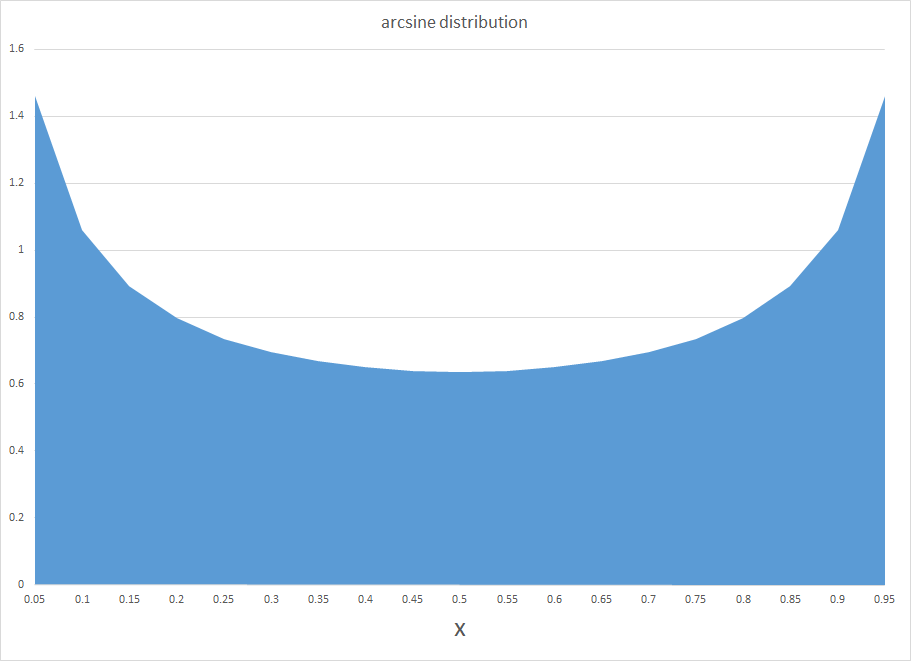
So, apparently, the distribution of time that a basketball team holds a lead in a basketball game is well-described by the arcsine distribution. This means lead changes are most likely at the beginning and end of the game, and least likely in the middle.
An earlier piece in the Financial Analysts Journal (The Arc Sine Law and the Treasure Bill Futures Market) notes,
..when two sports teams play, even though they have equal ability, the arc sine law dictates that one team will probably be in the lead most of the game. But the law also says that games with a close final score are surprisingly likely to be “last minute, come from behind” affairs, in which the ultimate winner trailed for most of the game..[Thus] over a series of games in which close final scores are common, one team could easily achieve a string of several last minute victories. The coach of such a team might be credited with being brilliantly talented, for having created a “second half” team..[although] there is a good possibility that he owes his success to chance.
There is nice mathematics underlying all this.
The name “arc sine distribution” derives from the integration of the PDF in the chart – a PDF which has the formula –
f(x) = 1/(π (x(1-x).5)
Here, the integral of f(x) yields the cumulative distribution function F(x) and involves an arcsine function,
F(x) = 2/(π arcsin(x.5))
Fundamentally, the arcsine law relates to processes where there are probabilities of winning and losing in sequential trials. The PDF follows from the application of Stirling’s formula to estimate expressions with factorials, such as the combination of p+q things taken p at a time, which quickly becomes computationally cumbersome as p+q increases in size.
There is probably no better introduction to the relevant mathematics than Feller’s exposition in his classic An Introduction to Probability Theory and Its Applications, Volume I.
Feller had an unusual ability to write lucidly about mathematics. His Chapter III “Fluctuations in Coin Tossing and Random Walks” in IPTAIA is remarkable, as I have again convinced myself by returning to study it again.

He starts out this Chapter III with comments:
We shall encounter theoretical conclusions which not only are unexpected but actually come as a shock to intuition and common sense. They will reveal that commonly accepted motions concerning chance fluctuations are without foundation and that the implications of the law of large numbers are widely misconstrued. For example, in various applications it is assumed that observations on an individual coin-tossing game during a long time interval will yield the same statistical characteristics as the observation of the results of a huge number of independent games at one given instant. This is not so..
Most pointedly, for example, “contrary to popular opinion, it is quite likely that in a long coin-tossing game one of the players remains practically the whole time on the winning side, the other on the losing side.”
The same underlying mathematics produces the Ballot Theorem, which states the chances a candidate will be ahead from an early point in vote counting, based on the final number of votes for that candidate.
This application, of course, comes very much to the fore in TV coverage of the results of on-going primaries at the present time. CNN’s initial announcement, for example, that Bernie Sanders beat Hillary Clinton in the New Hampshire primary came when less than half the precincts had reported in their vote totals.
In returning to Feller’s Volume 1, I recommend something like Sholmo Sternberg’s Lecture 8. If you read Feller, you have to be prepared to make little derivations to see the links between formulas. Sternberg cleared up some puzzles for me, which, alas, otherwise might have absorbed hours of my time.
The arc sine law may be significant for social and economic inequality, which perhaps can be considered in another post.