Often, working with software and electronics engineers, a question comes up – “if you are so good at forecasting (company sales, new product introductions), why don’t you forecast the stock market?” This might seem to be a variant of “if you are so smart, why aren’t you rich?” but I think it usually is asked more out of curiosity, than malice.
In any case, my standard reply has been that basically you could not forecast the stock market; that the stock market was probably more or less a random walk. If it were possible to forecast the stock market, someone would have done it. And the effect of successful forecasts would be to nullify further possibility of forecasting. I own an early edition of Burton Malkiel’s Random Walk Down Wall Street.
Today, I am in the amazing position of earnestly attempting to bring attention to the fact that, at least since 2008, a major measure of the stock market – the SPY ETF which tracks the S&P 500 Index, in fact, can be forecast. Or, more precisely, a forecasting model for daily returns of the SPY can lead to sustainable, increasing returns over the past several years, despite the fact the forecasting model, is, by many criteria, a weak predictor.
I think this has to do with special features of this stock market time series which have not, heretofore, received much attention in econometric modeling.
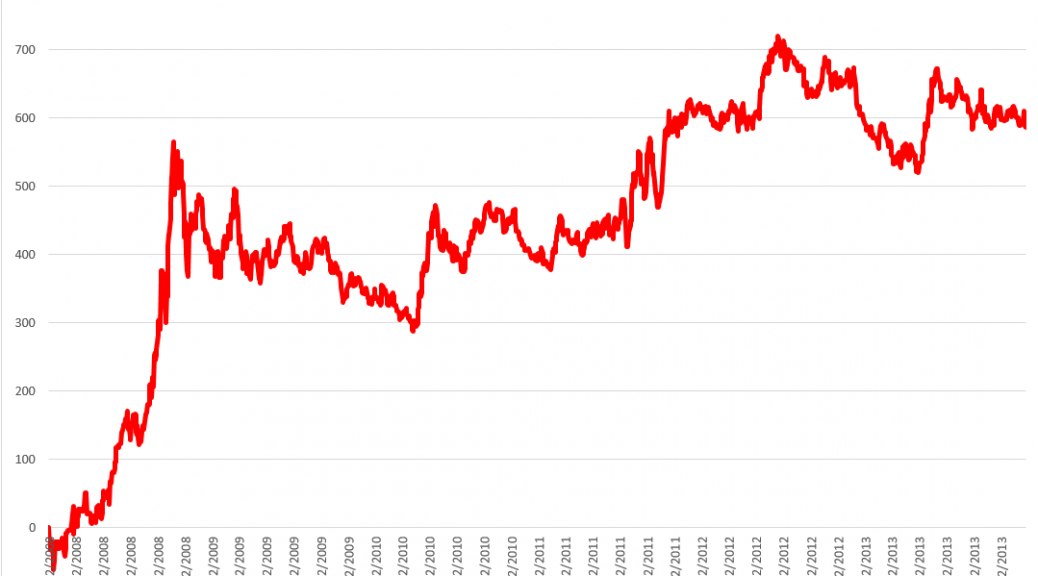
So here are the returns from applying this SPY from early 2008 to early 2014 (click to enlarge).
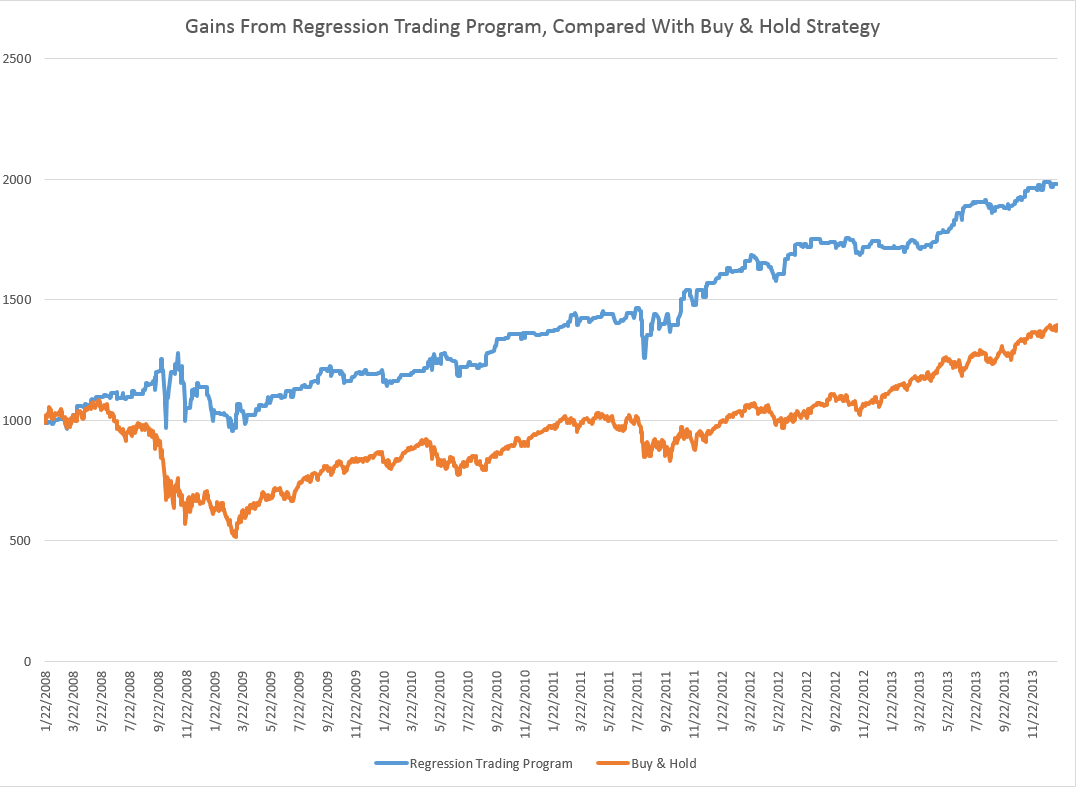
I begin with a $1000 investment 1/22/2008 and trade potentially every day, based on either the Trading Program or a Buy & Hold strategy.
Now there are several remarkable things about this Trading Program and the underlying regression model.
First, the regression model is a most unlikely candidate for making money in the stock market. The R2 or coefficient of determination is 0.0238, implying that the 60 regressors predict only 2.38 percent of the variation in the SPY rates of return. And it’s possible to go on in this vein – for example, the F-statistic indicating whether there is a relation between the regressors and the dependent variable is 1.42, just marginally above the 1 percent significance level, according to my reading of the Tables.
And the regression with 60 regressors correctly predicts the correct sign of the next days’ SPY rates of return only 50.1 percent of the time.
This, of course, is a key fact, since the Trading Program (see below) is triggered by positive predictions of the next day’s rate of return. When the next day rate of return is predicted to be positive and above a certain minimum value, the Trading Program buys SPY with the money on hand from previous sales – or, if the investor is already holding SPY because the previous day’s prediction also was positive, the investor stands pat.
The Conventional Wisdom
Professor Jim Hamilton, one of the principals (with Menzie Chin) in Econbrowser had a post recently On R-squared and economic prediction which makes the sensible point that R2 or the coefficient of determination in a regression is not a great guide to predictive performance. The post shows, among other things, that first differences of the daily S&P 500 index values regressed against lagged values of these first differences have low R2 – almost zero.
Hamilton writes,
Actually, there’s a well-known theory of stock prices that claims that an R-squared near zero is exactly what you should find. Specifically, the claim is that everything anybody could have known last month should already have been reflected in the value of pt -1. If you knew last month, when pt-1 was 1800, that this month it was headed to 1900, you should have bought last month. But if enough savvy investors tried to do that, their buy orders would have driven pt-1 up closer to 1900. The stock price should respond the instant somebody gets the news, not wait around a month before changing.
That’s not a bad empirical description of stock prices– nobody can really predict them. If you want a little fancier model, modern finance theory is characterized by the more general view that the product of today’s stock return with some other characteristics of today’s economy (referred to as the “pricing kernel”) should have been impossible to predict based on anything you could have known last month. In this formulation, the theory is confirmed– our understanding of what’s going on is exactly correct– only if when regressing that product on anything known at t – 1 we always obtain an R-squared near zero.
Well, I’m in the position here of seeking to correct one of my intellectual mentors. Although Professor Hamilton and I have never met nor communicated directly, I did work my way through Hamilton’s seminal book on time series analysis – and was duly impressed.
I am coming to the opinion that the success of this fairly low-power regression model on the SPY must have to do with special characteristics of the underlying distribution of rates of return.
For example, it’s interesting that the correlations between the (61) regressors and the daily returns are higher, when the absolute values of the dependent variable rates of return are greater. There is, in fact, a lot of meaningless buzz at very low positive and negative rates of return. This seems consistent with the odd shape of the residuals of the regression, shown below.
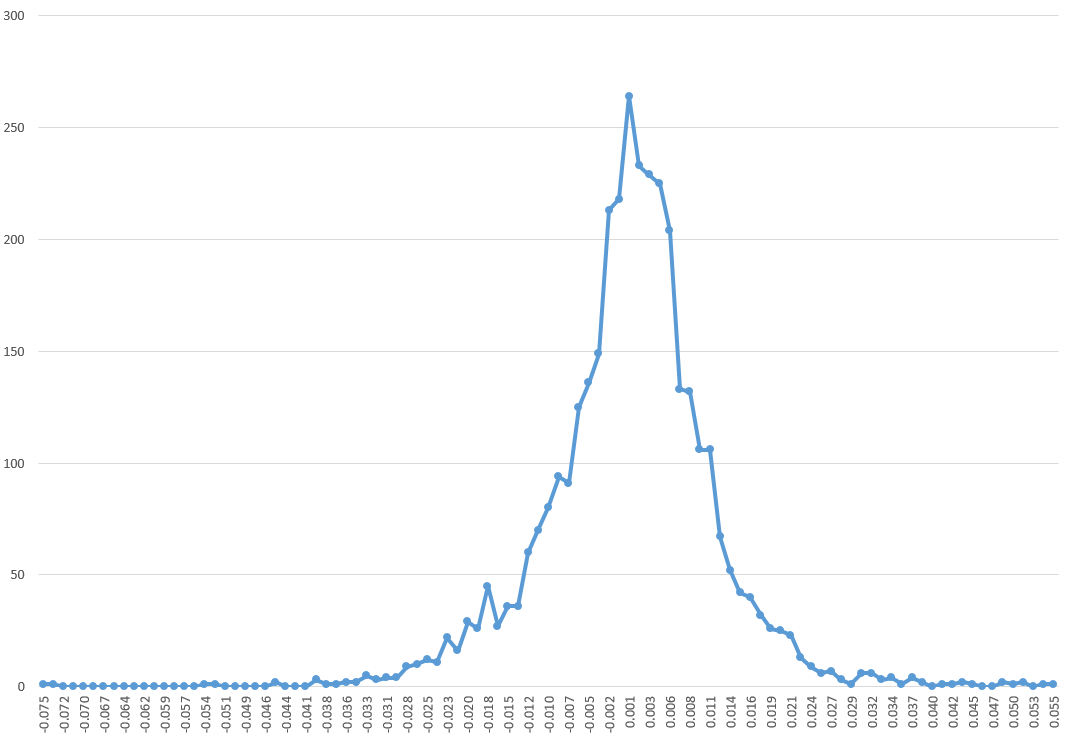
I’ve made this point before, most recently in a post-2014 post Predicting the S&P 500 or the SPY Exchange-Traded Fund, where I actually provide coefficients for a autoregressive model estimated by Matlab’s arima procedure. That estimation, incidentally, takes more account of the non-normal characteristics of the distribution of the rates of return, employing a t-distribution in maximum likelihood estimates of the parameters. It also only uses lagged values of SPY daily returns, and does not include any contribution from the VIX.
I guess in the remote possibility Jim Hamilton glances at either of these posts, it might seem comparable to reading claims of a perpetual motion machine, a method to square the circle, or something similar- quackery or wrong-headedness and error.
A colleague with a Harvard Ph.D in applied math, incidentally, has taken the trouble to go over my data and numbers, checking and verifying I am computing what I say I am computing.
Further details follow on this simple ordinary least squares (OLS) regression model I am presenting here.
Data and the Model
The focus of this modeling effort is on the daily returns of the SPDR S&P 500 (SPY), calculated with daily closing prices, as -1+(today’s closing price/the previous trading day’s closing price). The data matrix includes 30 lagged values of the daily returns of the SPY (SPYRR) along with 30 lagged values of the daily returns of the VIX volatility index (VIXRR). The data span from 11/26/1993 to 1/16/2014 – a total of 5,072 daily returns.
There is enough data to create separate training and test samples, which is good, since in-sample performance can be a very poor guide to out-of-sample predictive capabilities. The training sample extends from 11/26/1993 to 1/18/2008, for a total of 3563 observations. The test sample is the complement of this, extending from 1/22/2008 to 1/16/2014, including 1509 cases.
So the basic equation I estimate is of the form
SPYRRt=a0+a1SPYRRt-1…a30SPYRRt-30+b1VIXRRt-1+..+b30VIXRRt-30
Thus, the equation has 61 parameters – 60 coefficients multiplying into the lagged returns for the SPY and VIX indices and a constant term.
Estimation Technique
To make this simple, I estimate the above equation with the above data by ordinary least squares, implementing the standard matrix equation b = (XTX)-1XTY, where T indicates ‘transpose.’ I add a leading column of ‘1’s’ to the data matrix X to allow for a constant term a0. I do not mean center or standardize the observations on daily rates of return.
Rule for Trading Program and Summing UP
The Trading Program is the same one I described in earlier blog posts on this topic. Basically, I update forecasts every day and react to the forecast of the next day’s daily return. If it is positive, and now above a certain minimum, I either buy or hold. If it is not, I sell or do not enter the market. Oh yeah, I start out with $1000 in all these simulations and only trade with proceeds from this initial investment.
The only element of unrealism is that I have to predict the closing price of the SPY some short period before the close of the market to be able to enter my trade. I have not looked closely at this, but I am assuming volatility in the last few seconds is bounded, except perhaps in very unusual circumstances.
I take the trouble to present the results of an OLS regression to highlight the fact that what looks like a weak model in this context can work to achieve profits. I don’t think that point has ever been made. There are, of course, all sorts of possibilities for further optimizing this model.
I also suspect that monetary policy has some role in the success of this Trading Program over this period – so it would be interesting to look at similar models at other times and perhaps in other markets.





{kind=link}