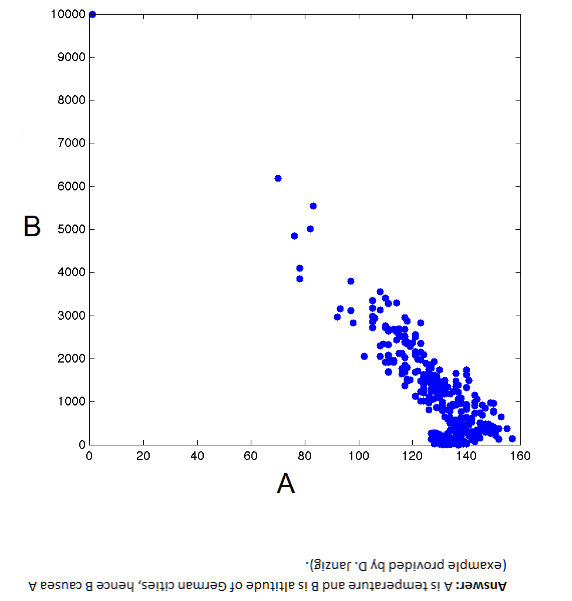
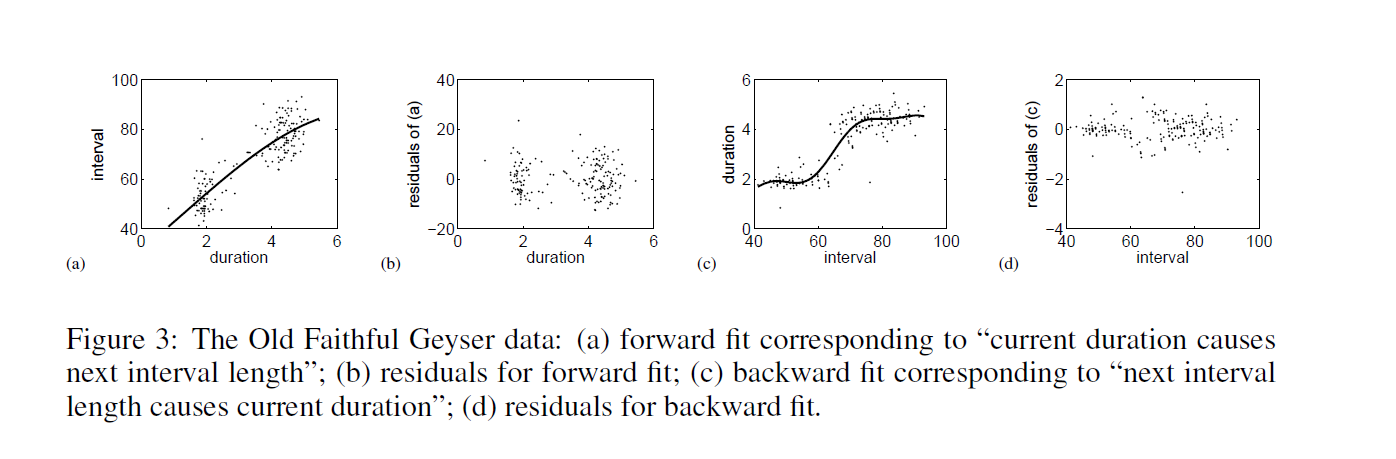
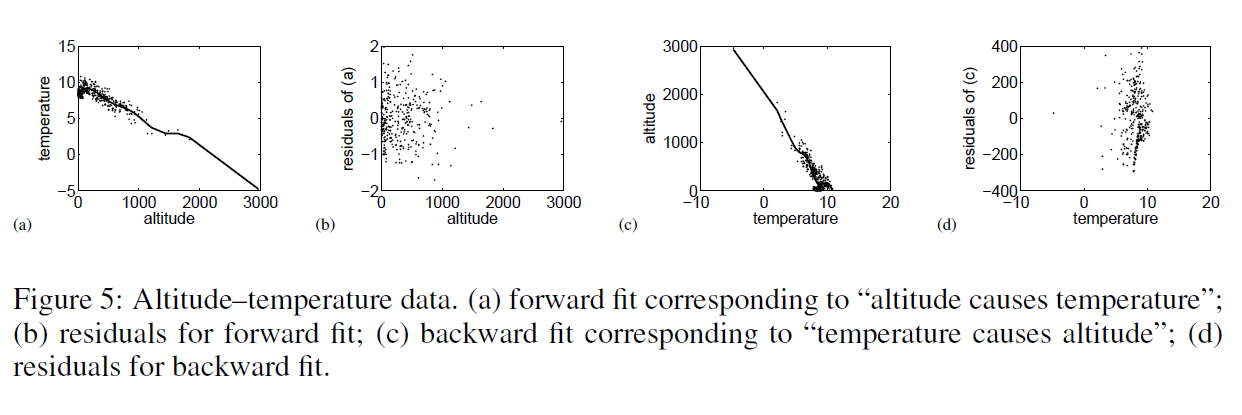
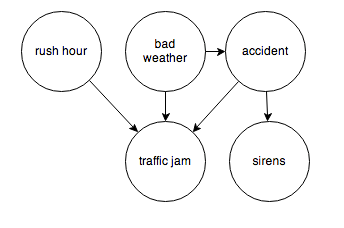
I’ve been exploring cycles in the semiconductor, computer and IT industries generally for quite some time.
Here is an exhibit I prepared in 2000 for a magazine serving the printed circuit board industry.
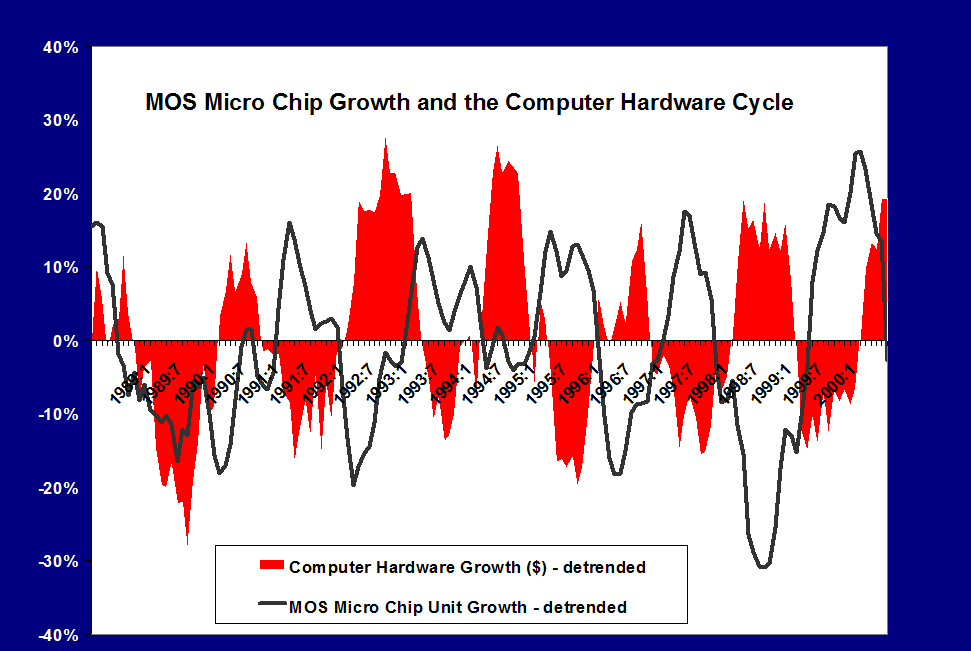
The data come from two sources – the Semiconductor Industry Association (SIA) World Semiconductor Trade Statistics database and the Census Bureau manufacturing series for computer equipment.
This sort of analytics spawned a spate of academic research, beginning more or less with the work of Tan and Mathews in Australia.
One of my favorites is a working paper released by DRUID – the Danish Research Unit for Industrial Dynamics called Cyclical Dynamics in Three Industries. Tan and Mathews consider cycles in semiconductors, computers, and what they call the flat panel display industry. They start with quoting “industry experts” and, specifically, some of my work with Economic Data Resources on the computer (PC) cycle. These researchers went on to publish in the Journal of Business Research and Technological Forecasting and Social Change in 2010. A year later in 2011, Tan published an interesting article on the sequencing of cyclical dynamics in semiconductors.
Essentially, the appearance of cycles and what I have called quasi-cycles or pseudo-cycles in the semiconductor industry and other IT categories, like computers, result from the interplay of innovation, investment, and pricing. In semiconductors, for example, Moore’s law – which everyone always predicts will fail at some imminent future point – indicates that continuing miniaturization will lead to periodic reductions in the cost of information processing. At some point in the 1980’s, this cadence was firmly established by introductions of new microprocessors by Intel roughly every 18 months. The enhanced speed and capacity of these microprocessors – the “central nervous system” of the computer – was complemented by continuing software upgrades, and, of course, by the movement to graphical interfaces with Windows and the succession of Windows releases.
Back along the supply chain, semiconductor fabs were retooling periodically to produce chips with more and more transitors per volume of silicon. These fabs were, simply put, fabulously expensive and the investment dynamics factors into pricing in semiconductors. There were famous gluts, for example, of memory chips in 1996, and overall the whole IT industry led the recession of 2001 with massive inventory overhang, resulting from double booking and the infamous Y2K scare.
Statistical Modeling of IT Cycles
A number of papers, summarized in Aubrey deploy VAR (vector autoregression) models to capture leading indicators of global semiconductor sales. A variant of these is the Bayesian VAR or BVAR model. Basically, VAR models sort of blindly specify all possible lags for all possible variables in a system of autoregressive models. Of course, some cutoff point has to be established, and the variables to be included in the VAR system have to be selected by one means or another. A BVAR simply reduces the number of possibilities by imposing, for example, sign constraints on the resulting coefficients, or, more ambitiously, employs some type of prior distribution for key variables.
Typical variables included in these models include:
- WSTS monthly semiconductor shipments (now by subscription only from SIA)
- Philadelphia semiconductor index (SOX) data
- US data on various IT shipments, orders, inventories from M3
- data from SEMI, the association of semiconductor equipment manufacturers
Another tactic is to filter out low and high frequency variability in a semiconductor sales series with something like the Hodrick-Prescott (HP) filter, and then conduct a spectral analysis.
Does the Semiconductor/Computer/IT Cycle Still Exist?
I wonder whether academic research into IT cycles is a case of “redoubling one’s efforts when you lose sight of the goal,” or more specifically, whether new configurations of forces are blurring the formerly fairly cleanly delineated pulses in sales growth for semiconductors, computers, and other IT hardware.
“Hardware” is probably a key here, since there have been big changes since the 1990’s and early years of this brave new century.
For one thing, complementarities between software and hardware upgrades seem to be breaking down. This began in earnest with the development of virtual servers – software which enabled many virtual machines on the same hardware frame, in part because the underlying circuitry was so massively powerful and high capacity now. Significant declines in the growth of sales of these machines followed on wide deployment of this software designed to achieve higher efficiencies of utilization of individual machines.
Another development is cloud computing. Running the data side of things is gradually being taken away from in-house IT departments in companies and moved over to cloud computing services. Of course, critical data for a company is always likely to be maintained in-house, but the need for expanding the number of big desktops with the number of employees is going away – or has indeed gone away.
At the same time, tablets, Apple products and Android machines, created a wave of destructive creation in people’s access to the Internet, and, more and more, for everyday functions like keeping calendars, taking notes, even writing and processing photos.
But note – I am not studding this discussion with numbers as of yet.
I suspect that underneath all this change it should be possible to identify some IT invariants, perhaps in usage categories, which continue to reflect a kind of pulse and cycle of activity.