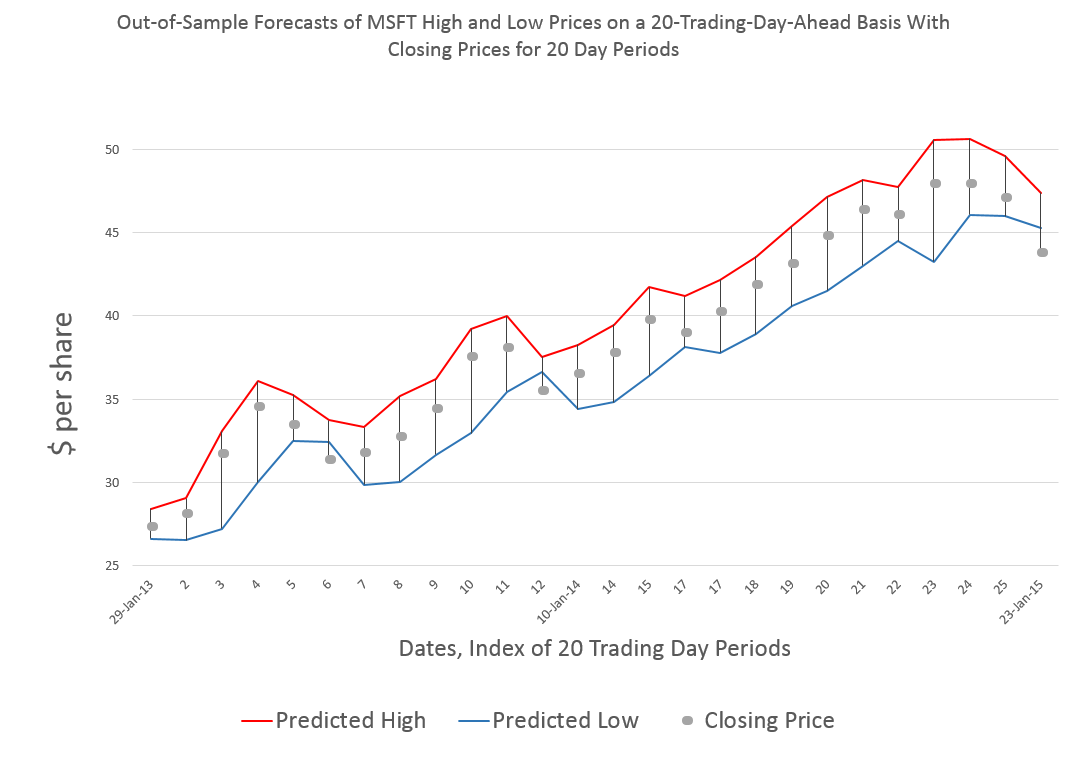
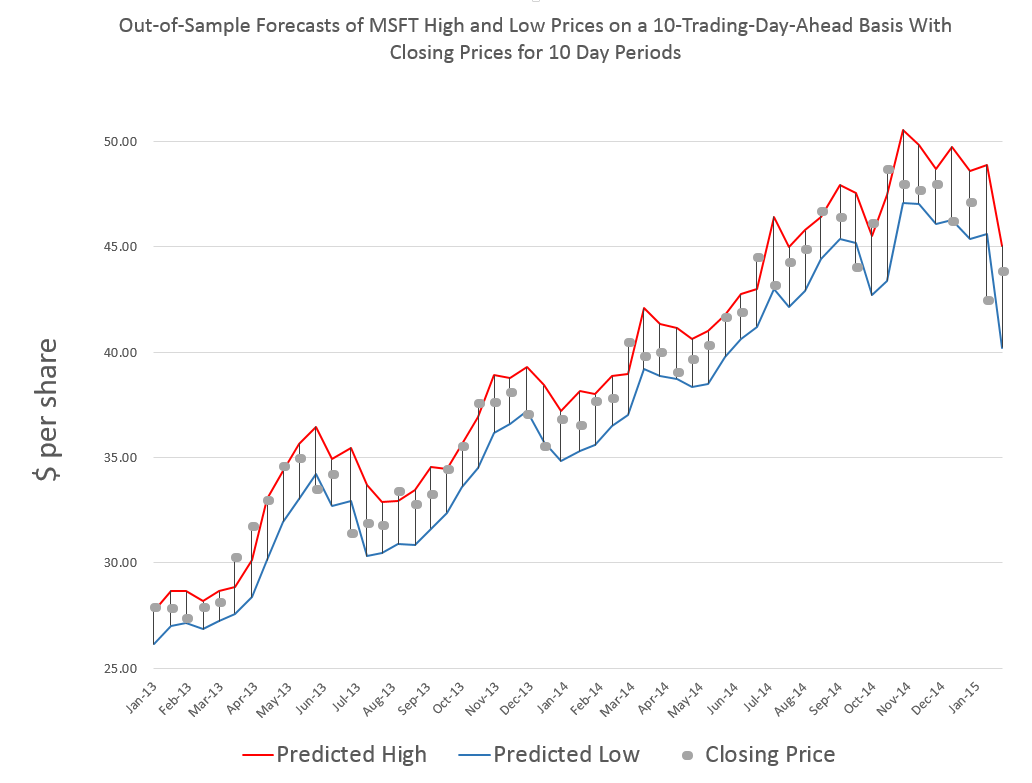
Forecasts in business are unavoidable, since decisions must be made for annual budgets and shorter term operational plans, and investments must be made.
And regardless of approach, practical problems arise.
For example, should output from formal algorithms be massaged, so final numbers include judgmental revisions? What about error metrics? Is the mean absolute percent error (MAPE) best, because everybody is familiar with percents? What are plus’es and minus’es of various forecast error metrics? And, organizationally, where should forecasting teams sit – marketing, production, finance, or maybe in a free-standing unit?
The editors of Business Forecasting – Practical Problems and Solutions integrate dozens of selections to focus on these and other practical forecasting questions.
Here are some highlights.
In my experience, many corporate managers, even VP’s and executives, understand surprisingly little about fitting models to data.
So guidelines for reporting results are important.
In “Dos and Don’ts of Forecast Accuracy Measurement: A Tutorial,” Len Tashman advises “distinguish in-sample from out-of-sample accuracy,” calling it “the most basic issue.”
The acid test is how well the forecast model does “out-of-sample.” Holdout samples and cross-validation simulate how the forecast model will perform going forward. “If your average error in-sample is found to be 10%, it is very probable that forecast errors will average substantially more than 10%.” That’s because model parameters are calibrated to the sample over which they are estimated. There is a whole discussion of “over-fitting,” R2, and model complexity hinging on similar issues. Don’t fool yourself. Try to find ways to test your forecast model on out-of-sample data.
The discussion of fitting models when there is “extreme seasonality” broke new ground for me. In retail forecasting, there might be a toy or product that sells only at Christmastime. Demand is highly intermittent. As Udo Sglavo reveals, one solution is “time compression.” Collapse the time series data into two periods – the holiday season and the rest of the year. Then, the on-off characteristics of sales can be more adequately modeled. Clever.
John Mello’s “The Impact of Sales Forecast Game Playing on Supply Chains,” is probably destined to be a kind of classic, since it rolls up a lot of what we have all heard and observed about strategic behavior vis a vis forecasts.
Mello describes stratagems including
- Enforcing – maintaining a higher forecast than actually anticipated, to keep forecasts in line with goals
- Filtering – changing forecasts to reflect product on hand for sale
- Hedging – overestimating sales to garner more product or production capability
- Sandbagging – underestimating sales to set expectations lower than actually anticipated demand
- Second-guessing – changing forecasts to reflect instinct or intuition
- Spinning – manipulating forecasts to get favorable reactions from individuals or departments in the organization
- Withholding – refusing to share current sales information
I’ve seen “sand-bagging” at work, when the salesforce is allowed to generate the forecasts, setting expectations for future sales lower than should, objectively, be the case. Purely by coincidence, of course, sales quotas are then easier to meet and bonuses easier to achieve.
I’ve always wondered why Gonik’s system, mentioned in an accompanying article by Michael Gilliland on the “Role of the Sales Force in Forecasting,” is not deployed more often. Gonik, in a classic article in the Harvard Business Review, ties sales bonuses jointly to the level of sales that are forecast by the field, and also to how well actual sales match the forecasts that were made. It literally provides incentives for field sales staff to come up with their best, objective estimate of sales in the coming period. (See Sales Forecasts and Incentives)
Finally, Larry Lapide’s “Where Should the Forecasting Function Reside?” asks a really good question.
The following graphic (apologies for the scan reproduction) summarizes some of his key points.

There is no fixed answer, Lapide provides a list of things to consider for each organization.
This book is a good accompaniment for Rob Hyndman and George Athanasopoulos’s online Forecasting: Principles and Practice.