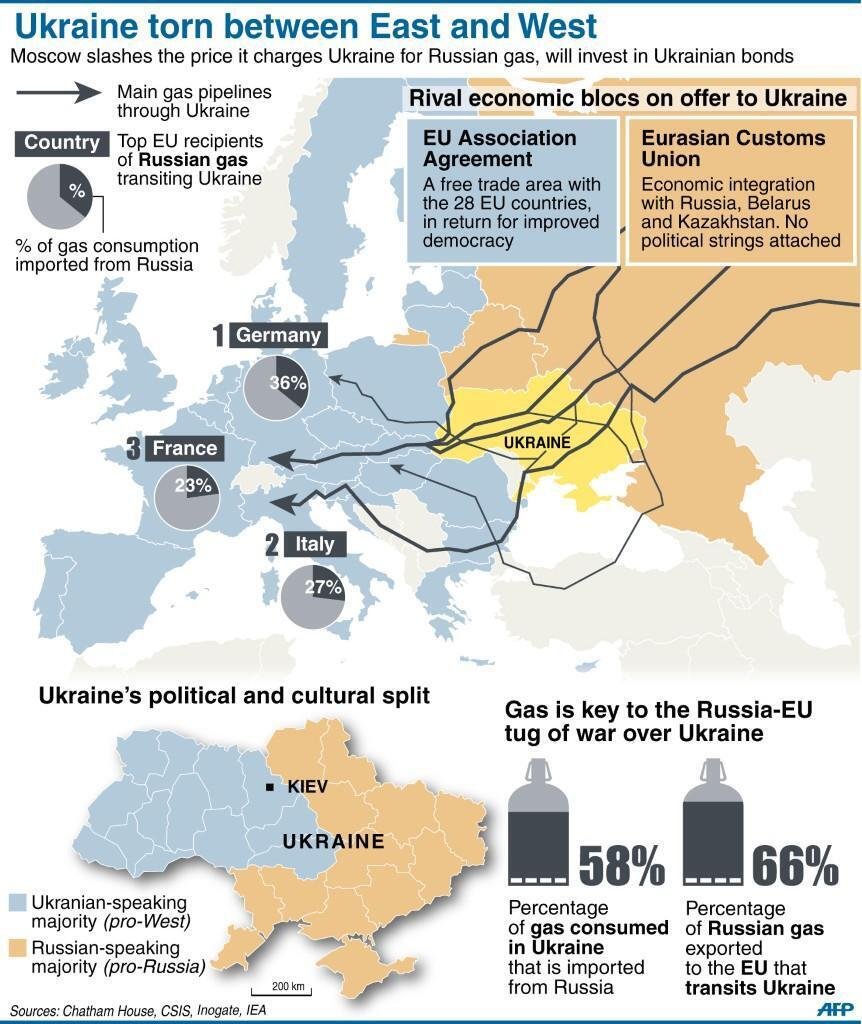
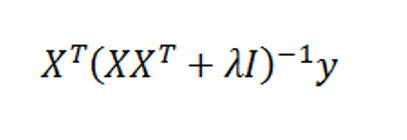The LASSO (Least Absolute Shrinkage and Selection Operator) is a method of automatic variable selection which can be used to select predictors X* of a target variable Y from a larger set of potential or candidate predictors X.
Developed in 1996 by Tibshirani, the LASSO formulates curve fitting as a quadratic programming problem, where the objective function penalizes the absolute size of the regression coefficients, based on the value of a tuning parameter λ. In doing so, the LASSO can drive the coefficients of irrelevant variables to zero, thus performing automatic variable selection.
This post features a toy example illustrating tactics in variable selection with the lasso. The post also dicusses the issue of consistency – how we know from a large sample perspective that we are honing in on the true set of predictors when we apply the LASSO.
My take is a two-step approach is often best. The first step is to use the LASSO to identify a subset of potential predictors which are likely to include the best predictors. Then, implement stepwise regression or other standard variable selection procedures to select the final specification, since there is a presumption that the LASSO “over-selects” (Suggested at the end of On Model Selection Consistency of Lasso).
Toy Example
The LASSO penalizes the absolute size of the regression coefficients, based on the value of a tuning parameter λ. When there are many possible predictors, many of which actually exert zero to little influence on a target variable, the lasso can be especially useful in variable selection.
For example, generate a batch of random variables in a 100 by 15 array – representing 100 observations on 15 potential explanatory variables. Mean-center each column. Then, determine coefficient values for these 15 explanatory variables, allowing several to have zero contribution to the dependent variable. Calculate the value of the dependent variable y for each of these 100 cases, adding in a normally distributed error term.
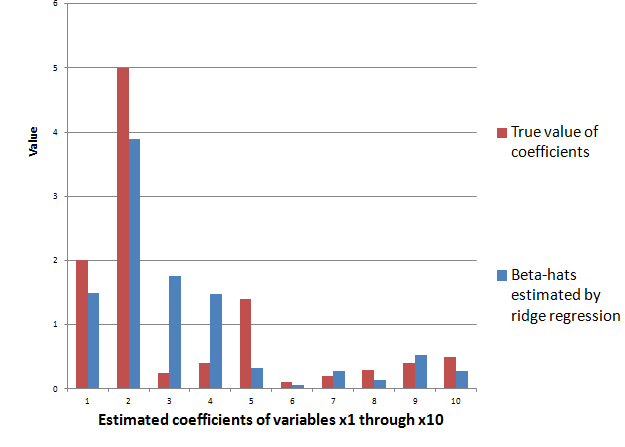
The following Table illustrates something of the power of the lasso.
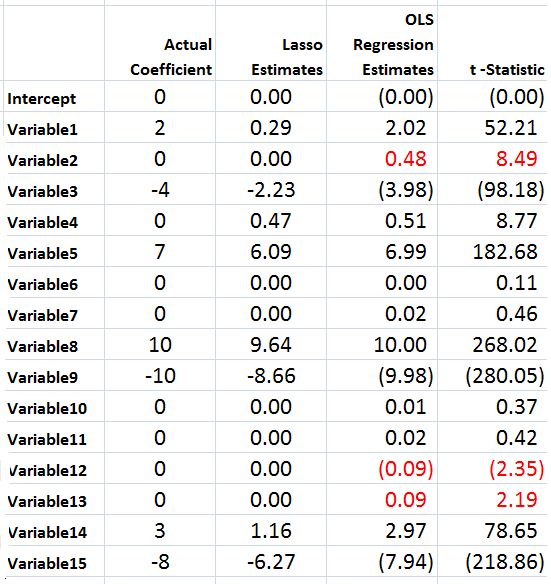
Using the Matlab lasso procedure and a lambda value of 0.3, seven of the eight zero coefficients are correctly identified. The OLS regression estimate, on the other hand, indicates that three of the zero coefficients are nonzero at a level of 95 percent statistical significance or more (magnitude of the t-statistic > 2).
Of course, the lasso also shrinks the value of the nonzero coefficients. Like ridge regression, then, the lasso introduces bias to parameter estimates, and, indeed, for large enough values of lambda drives all coefficient to zero.
Note OLS can become impossible, when the number of predictors in X* is greater than the number of observations in Y and X. The LASSO, however, has no problem dealing with many predictors.
Real World Examples
For a recent application of the lasso, see the Dallas Federal Reserve occasional paper Hedge Fund Dynamic Market Stability. Note that the lasso is used to identify the key drivers, and other estimation techniques are employed to hone in on the parameter estimates.
For an application of the LASSO to logistic regression in genetics and molecular biology, see Lasso Logistic Regression, GSoft and the Cyclic Coordinate Descent Algorithm, Application to Gene Expression Data. As the title suggests, this illustrates the use of the lasso in logistic regression, frequently utilized in biomedical applications.
Formal Statement of the Problem Solved by the LASSO
The objective function in the lasso involves minimizing the residual sum of squares, the same entity figuring in ordinary least squares (OLS) regression, subject to a bound on the sum of the absolute value of the coefficients. The following clarifies this in notation, spelling out the objective function.
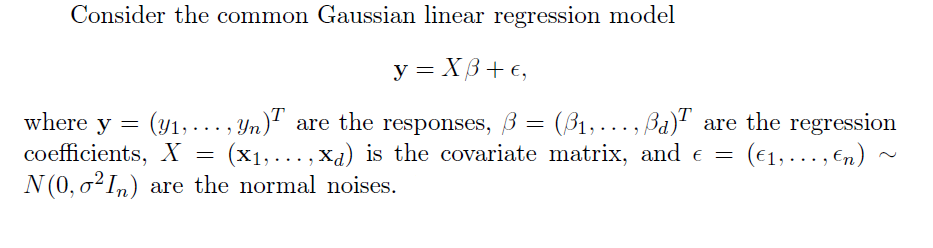

The computation of the lasso solutions is a quadratic programming problem, tackled by standard numerical analysis algorithms. For an analytical discussion of the lasso and other regression shrinkage methods, see the outstanding free textbook The Elements of Statistical Learning by Hastie, Tibshirani, and Friedman.
The Issue of Consistency
The consistency of an estimator or procedure concerns its large sample characteristics. We know the LASSO produces biased parameter estimates, so the relevant consistency is whether the LASSO correctly predicts which variables from a larger set are in fact the predictors.
In other words, when can the LASSO select the “true model?”
Now in the past, this literature is extraordinarily opaque, involving something called the Irrepresentable Condition, which can be glossed as –
Fortunately a ray of light has burst through with Assumptionless Consistency of the Lasso by Chatterjee. Apparently, the LASSO selects the true model almost always – with minimal side assumptions – providing we are satisfied with the prediction error criterion – the mean square prediction error – employed in Tibshirani’s original paper.
Finally, cross-validation is typically used to select the tuning parameter λ, and is another example of this procedure highlighted by Varian’s recent paper.