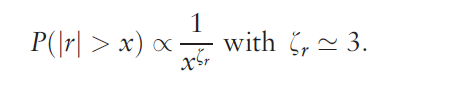This is a kind of wrap-up discussion of probability distributions and daily stock returns.
When I did autoregressive models for daily stock returns, I kept getting this odd, pointy, sharp-peaked distribution of residuals with heavy tails. Recent posts have been about fitting a Laplace distribution to such data.
I have recently been working with the first differences of the logarithm of daily closing prices – an entity the quantitative finance literature frequently calls “daily returns.”
It turns out many researchers have analyzed the distribution of stock returns, finding fundamental similarities in the resulting distributions. There are also similarities for many stocks in many international markets in the distribution of trading volumes and the number of trades. These similarities exist at a range of frequencies – over a few minutes, over trading days, and longer periods.
The paradigmatic distribution of returns looks like this:
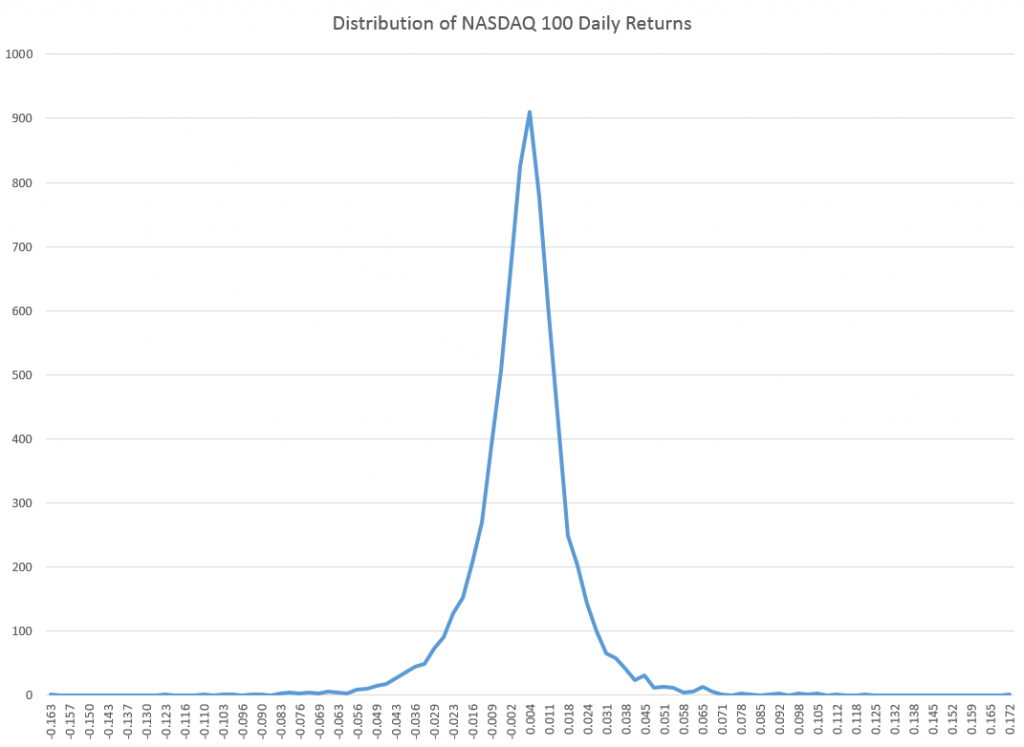
This is based on closing prices of the NASDAQ 100 from October 1985 to the present.
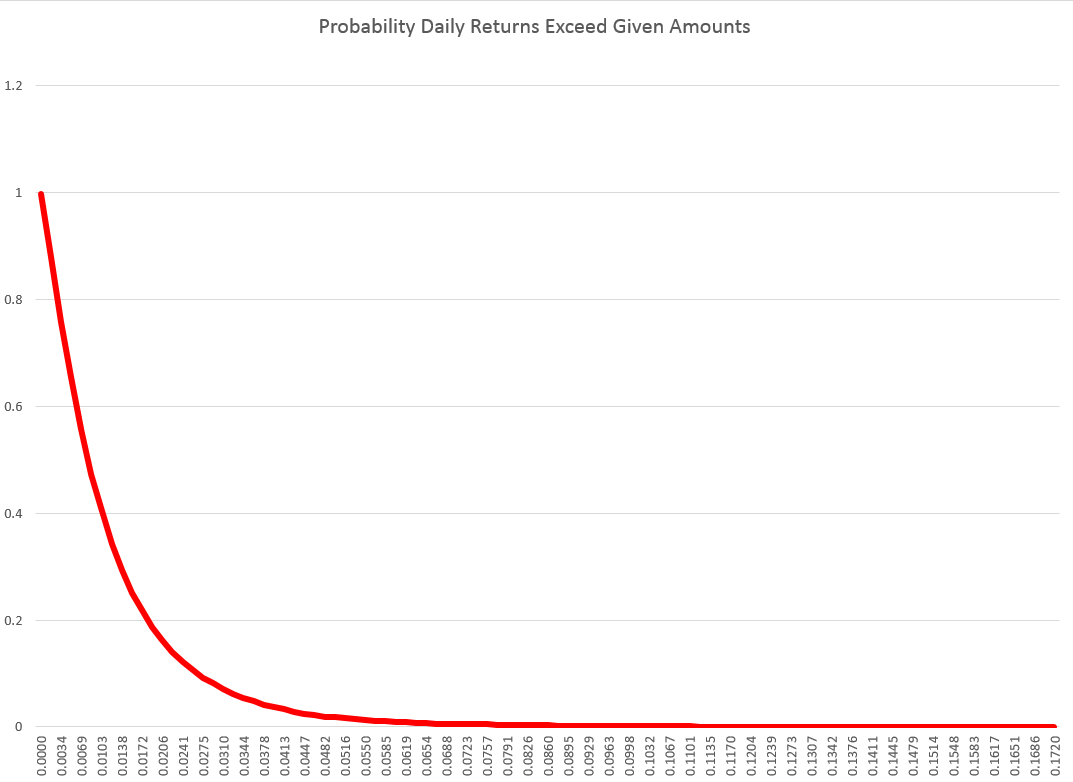
There also are power laws that can be extracted from the probabilities that the absolute value of returns will exceed a certain amount.
For example, again with daily returns from the NASDAQ 100, we get an exponential distribution if we plot these probabilities of exceedance. This curve can be fit by a relationship ~x-θ where θ is between 2.7 and 3.7, depending on where you start the estimation from the top or largest probabilities.
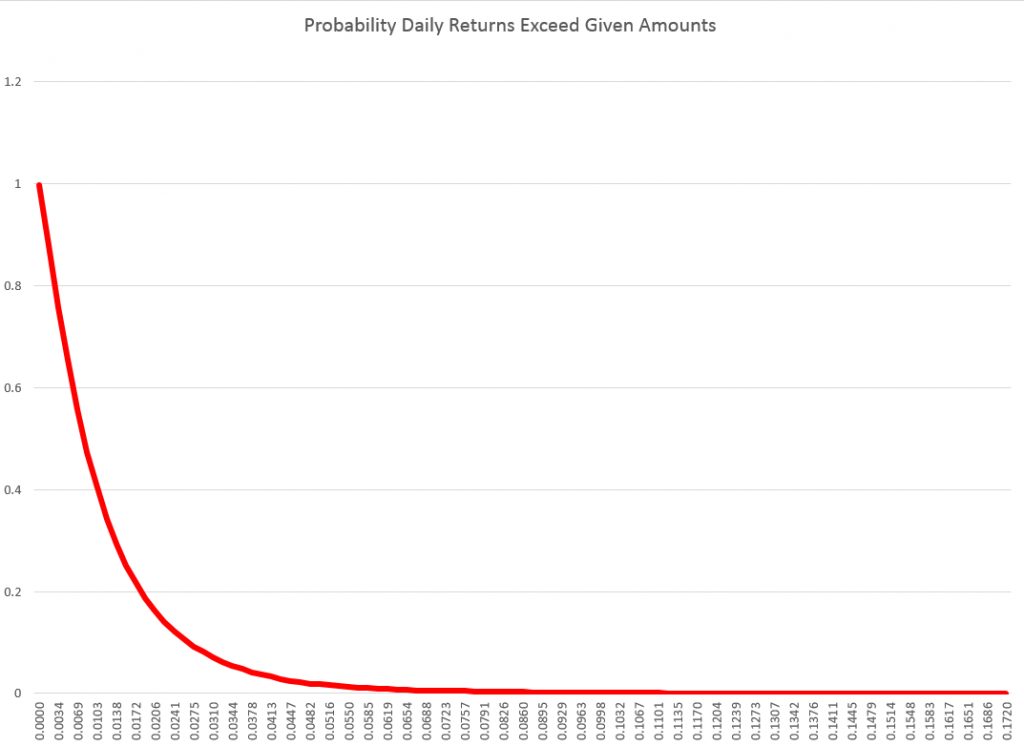
These magnitudes of the exponent are significant, because they seem to rule out whole classes, such as Levy stable distributions, which require θ < 2.
Also, let me tell you why I am not “extracting the autoregressive components” here. There are probably nonlinear lag effects in these stock price data. So my linear autoregressive equations probably cannot extract all the time dependence that exist in the data. For that reason, and also because it seems pro forma in quantitative finance, my efforts have turned to analyzing what you might call the raw daily returns calculated with price data and suitable transformations.
Levy Stable Distributions
At the turn of the century, Mandelbrot, then Sterling Professor of Mathematics at Yale, wrote an introductory piece for a new journal called Quantitative Finance called Scaling in financial prices: I. Tails and dependence. In that piece, which is strangely convoluted by my lights, Mandelbrot discusses how he began working with Levy-stable distributions in the 1960’s to model the heavy tails of various stock and commodity price returns.
The terminology is a challenge, since there appear to be various ways of discussing so-called stable distributions, which are distributions which yield other distributions of the same type under operations like summing random variables, or taking their ratios.
The Quantitative Finance section of Stack Exchange has a useful Q&A on Levy-stable distributions in this context.
Answers refer readers to Nolan’s 2005 paper Modeling Financial Data With Stable Distributions which tells us that the class of all distributions that are sum-stable is described by four parameters. The distributions controlled by these parameters, however, are generally not accessible as closed algebraic expressions, but must be traced out numerically by computer computations.
Nolan gives several applications, for example, to currency data, illustrated with the following graphs.
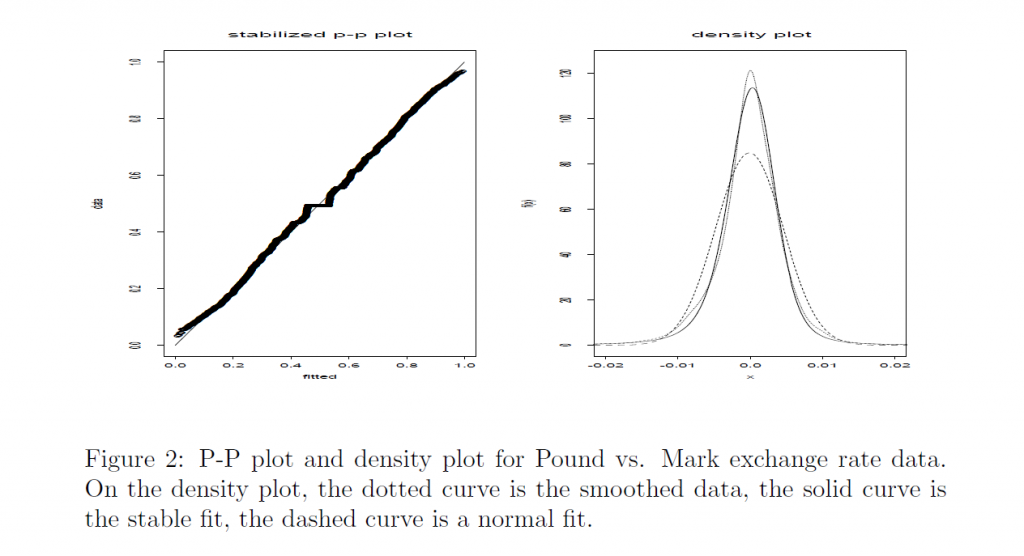
So, the characteristics of the Laplace distribution I find so compelling are replicated to an extent by the Levy-stable distributions.
While Levy-stable distributions continue to be the focus of research in some areas of quantitative finance – risk assessment, for instance – it’s probably true that applications to stock returns are less popular lately. There are two reasons in particular. First, Levy stable distributions apparently have infinite variance, and as Cont writes, there is conclusive evidence that stock prices have finite second moments. Secondly, Levy stable distributions imply power laws for the probability of exceedance of a given level of absolute value of returns, but unfortunately these power laws have an exponent less than 2.
Neither of these “facts” need prove conclusive, though. Various truncated versions of Levy stable distributions have been used in applications like estimating Value at Risk (VAR).
Nolan also maintains a webpage which addresses some of these issues, and provides tools to apply Levy stable distributions.
Why Do These Regularities in Daily Returns and Other Price Data Exist?
If I were to recommend a short list of articles as “must-reads” in this field, Rama Cont’s 2001 survey in Quantitative Finance would be high on the list, as well as Gabraix et al’s 2003 paper on power laws in finance.
Cont provides a list of11 stylized facts regarding the distribution of stock returns.
1. Absence of autocorrelations: (linear) autocorrelations of asset returns are often insignificant, except for very small intraday time scales (
20 minutes) for which microstructure effects come into play.
2. Heavy tails: the (unconditional) distribution of returns seems to display a power-law or Pareto-like tail, with a tail index which is finite, higher than two and less than five for most data sets studied. In particular this excludes stable laws with infinite variance and the normal distribution. However the precise form of the tails is difficult to determine.
3. Gain/loss asymmetry: one observes large drawdowns in stock prices and stock index values but not equally large upward movements.
4. Aggregational Gaussianity: as one increases the time scale �t over which returns are calculated, their distribution looks more and more like a normal distribution. In particular, the shape of the distribution is not the same at different time scales.
5. Intermittency: returns display, at any time scale, a high degree of variability. This is quantified by the presence of irregular bursts in time series of a wide variety of volatility estimators.
6. Volatility clustering: different measures of volatility display a positive autocorrelation over several days, which quantifies the fact that high-volatility events tend to cluster in time.
7. Conditional heavy tails: even after correcting returns for volatility clustering (e.g. via GARCH-type models), the residual time series still exhibit heavy tails. However, the tails are less heavy than in the unconditional distribution of returns.
8. Slow decay of autocorrelation in absolute returns: the autocorrelation function of absolute returns decays slowly as a function of the time lag, roughly as a power law with an exponent β ∈ [0.2, 0.4]. This is sometimes interpreted as a sign of long-range dependence.
9. Leverage effect: most measures of volatility of an asset are negatively correlated with the returns of that asset.
10. Volume/volatility correlation: trading volume is correlated with all measures of volatility.
11. Asymmetry in time scales: coarse-grained measures of volatility predict fine-scale volatility better than the other way round.
There’s a huge amount here, and it’s very plainly and well stated.
But then why?
Gabraix et al address this question, in a short paper published in Nature.
Insights into the dynamics of a complex system are often gained by focusing on large fluctuations. For the financial system, huge databases now exist that facilitate the analysis of large fluctuations and the characterization of their statistical behavior. Power laws appear to describe histograms of relevant financial fluctuations, such as fluctuations in stock price, trading volume and the number of trades. Surprisingly, the exponents that characterize these power laws are similar for different types and sizes of markets, for different market trends and even for different countries suggesting that a generic theoretical basis may underlie these phenomena. Here we propose a model, based on a plausible set of assumptions, which provides an explanation for these empirical power laws. Our model is based on the hypothesis that large movements in stock market activity arise from the trades of large participants. Starting from an empirical characterization of the size distribution of those large market participants (mutual funds), we show that the power laws observed in financial data arise when the trading behaviour is performed in an optimal way. Our model additionally explains certain striking empirical regularities that describe the relationship between large fluctuations in prices, trading volume and the number of trades.
The kernel of this paper in Nature is as follows:

Thus, Gabraix links the distribution of purchases in stock and commodity markets with the resulting distribution of daily returns.
I like this hypothesis and see ways it connects with the Laplace distribution and its variants. Probably, I will write more about this in a later post.