It started innocently enough, when an article in the scientific journal Nature caught my attention – When Google got flu wrong. This highlights big errors in Google flu trends in the 2012-2013 flu season.
Then digging into the backstory, I’m intrigued to find real controversy bubbling below the surface. Phrases like “big data hubris” are being thrown around, and there are insinuations Google is fudging model outcomes, at least in backtests. Beyond that, there are substantial statistical criticisms of the Google flu trends model – relating to autocorrelation and seasonality of residuals.
I’m using this post to keep track of some of the key documents and developments.
Background on Google Flu Trends
Google flu trends, launched in 2008, targets public health officials, as well as the general public.
Cutting lead-time on flu forecasts can support timely stocking and distribution of vaccines, as well as encourage health practices during critical flue months.
What’s the modeling approach?
There seem to be two official Google-sponsored reports on the underlying prediction model.
Detecting influenza epidemics using search engine query data appears in Nature in early 2009, and describes a logistic regression model estimating the probability that a random physician visit in a particular region is related to an influenza-like illness (ILI). This approach is geared to historical logs of online web search queries submitted between 2003 and 2008, and publicly available data series from the CDC’s US Influenza Sentinel Provider Surveillance Network (http://www.cdc.gov/flu/weekly).
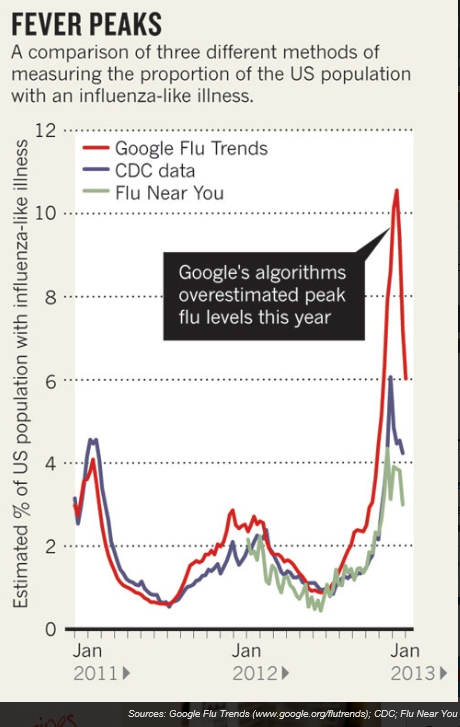
The second Google report – Google Disease Trends: An Update – came out recently, in response to our algorithm overestimating influenza-like illness (ILI) and the 2013 Nature article. It mentions in passing corrections discussed in a 2011 research study, but focuses on explaining the over-estimate in peak doctor visits during the 2012-2013 flu season.
The current model, while a well performing predictor in previous years, did not do very well in the 2012-2013 flu season and significantly deviated from the source of truth, predicting substantially higher incidence of ILI than the CDC actually found in their surveys. It became clear that our algorithm was susceptible to bias in situations where searches for flu-related terms on Google.com were uncharacteristically high within a short time period. We hypothesized that concerned people were reacting to heightened media coverage, which in turn created unexpected spikes in the query volume. This assumption led to a deep investigation into the algorithm that looked for ways to insulate the model from this type of media influence
The antidote – “spike detectors” and more frequent updating.
The Google Flu Trends Still Appears Sick Report
A just-published critique –Google Flu Trends Still Appears Sick – available as a PDF download from a site at Harvard University – provides an in-depth review of the errors and failings of Google foray into predictive analytics. This latest critique of Google flu trends even raises the issue of “transparency” of the modeling approach and seems to insinuate less than impeccable honesty at Google with respect to model performance and model details.
This white paper follows the March 2014 publication of The Parable of Google Flu: Traps in Big Data Analysis in Science magazine. The Science magazine article identifies substantive statistical problems with the Google flu trends modeling, such as the fact that,
..the overestimation problem in GFT was also present in the 2011‐2012 flu season (2). The report also found strong evidence of autocorrelation and seasonality in the GFT errors, and presented evidence that the issues were likely, at least in part, due to modifications made by Google’s search algorithm and the decision by GFT engineers not to use previous CDC reports or seasonality estimates in their models – what the article labeled “algorithm dynamics” and “big data hubris” respectively.
Google Flu Trends Still Appears Sick follows up on the very recent science article, pointing out that the 2013-2014 flu season also shows fairly large errors, and asking –
So have these changes corrected the problem? While it is impossible to say for sure based on one subsequent season, the evidence so far does not look promising. First, the problems identified with replication in GFT appear to, if anything, have gotten worse. Second, the evidence that the problems in 2012‐2013 were due to media coverage is tenuous. While GFT engineers have shown that there was a spike in coverage during the 2012‐2013 season, it seems unlikely that this spike was larger than during the 2005‐2006 A/H5N1 (“bird flu”) outbreak and the 2009 A/H1N1 (“swine flu”) pandemic. Moreover, it does not explain why the proportional errors were so large in the 2011‐2012 season. Finally, while the changes made have dampened the propensity for overestimation by GFT, they have not eliminated the autocorrelation and seasonality problems in the data.
The white paper authors also highlight continuing concerns with Google’s transparency.
One of our main concerns about GFT is the degree to which the estimates are a product of a highly nontransparent process… GFT has not been very forthcoming with this information in the past, going so far as to release misleading example search terms in previous publications (2, 3, 8). These transparency problems have, if anything, become worse. While the data on the intensity of media coverage of flu outbreaks does not involve privacy concerns, GFT has not released this data nor have they provided an explanation of how the information was collected and utilized. This information is critically important for future uses of GFT. Scholars and practitioners in public health will need to be aware of where the information on media coverage comes from and have at least a general idea of how it is applied in order to understand how to interpret GFT estimates the next time there is a season with both high flu prevalence and high media coverage.
They conclude by stating that GFT is still ignoring data that could help it avoid future problems.
Finally, to really muddy the waters Columbia University medical researcher Jeffrey Shaman recently announced First Real-Time Flu Forecast Successful. Shaman’s model apparently keys off Google flu trends.
What Does This Mean?
I think the Google flu trends controversy is important for several reasons.
First, predictive models drawing on internet search activity and coordinated with real-time clinical information are an ambitious and potentially valuable undertaking, especially if they can provide quicker feedback on prospective ILI in specific metropolitan areas. And the Google teams involved in developing and supporting Google flu trends have been somewhat forthcoming in presenting their modeling approach and acknowledging problems that have developed.
“Somewhat” but not fully forthcoming – and that seems to be the problem. Unlike research authored by academicians or the usual scientific groups, the authors of the two main Google reports mentioned above remain difficult to reach directly, apparently. So question linger and critics start to get impatient.
And it appears that there are some standard statistical issues with the Google flu forecasts, such as autocorrelation and seasonality in residuals that remain uncorrected.
I guess I am not completely surprised, since the Google team may have come from the data mining or machine learning community, and not be sufficiently indoctrinated in the “old ways” of developing statistical models.
Craig Venter has been able to do science, and yet operate in private spaces, rather than in the government or nonprofit sector. Whether Google as a company will allow scientific protocols to be followed – as apparently clueless as these are to issues of profit or loss – remains to be seen. But if we are going to throw the concept of “data scientist” around, I guess we need to think through the whole package of stuff that goes with that.