The 2012 Global Energy Forecasting Competition was organized by an IEEE Working Group to connect academic research and industry practice, promote analytics in engineering education, and prepare for forecasting challenges in the smart grid world. Participation was enhanced by alliance with Kaggle for the load forecasting track. There also was a second track for wind power forecasting.
Hundreds of people and many teams participated.
This year’s April/June issue of the International Journal of Forecasting (IJF) features research from the winners.
Before discussing the 2012 results, note that there’s going to be another competition – the Global Energy Forecasting Competition 2014 – scheduled for launch August 15 of this year. Professor Tao Hong, a key organizer, describes the expansion of scope,
GEFCom2014 (www.gefcom.org) will feature three major upgrades: 1) probabilistic forecasts in the form of predicted quantiles; 2) four tracks on demand, price, wind and solar; 3) rolling forecasts with incremental data update on weekly basis.
Results of the 2012 Competition
The IJF has an open source article on the competition. This features a couple of interesting tables about the methods in the load and wind power tracks (click to enlarge).
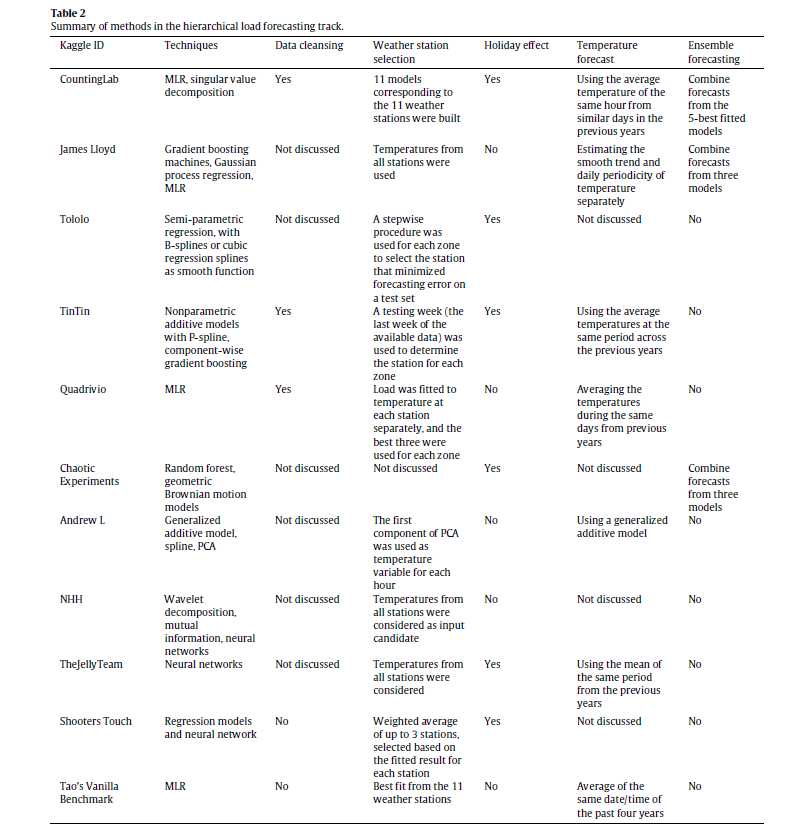
The error metric is WRMSE, standing for weighted root mean square error. One week ahead system (as opposed to zone) forecasts received the greatest weight. The top teams with respect to WRMSE were Quadrivio, CountingLab, James Lloyd, and Tololo (Électricité de France).

The top wind power forecasting teams were Leustagos, DuckTile, and MZ based on overall performance.
Innovations in Electric Power Load Forecasting
The IJF overview article pitches the hierarchical load forecasting problem as follows:
…participants were required to backcast and forecast hourly loads (in kW) for a US utility with 20 zones at both the zonal (20 series) and system (sum of the 20 zonal level series) levels, with a total of 21 series. We provided the participants with 4.5 years of hourly load and temperature history data, with eight non-consecutive weeks of load data removed. The backcasting task is to predict the loads of these eight weeks in the history, given actual temperatures, where the participants are permitted to use the entire history to backcast the loads. The forecasting task is to predict the loads for the week immediately after the 4.5 years of history without the actual temperatures or temperature forecasts being given. This is designed to mimic a short term load forecasting job, where the forecaster first builds a model using historical data, then develops the forecasts for the next few days.
One of the top entries is by a team from Électricité de France (EDF) and is written up under the title GEFCom2012: Electric load forecasting and backcasting with semi-parametric models.
This is behind the International Journal of Forecasting paywall at present, but some of the primary techniques can be studied in a slide set by Yannig Goulde.
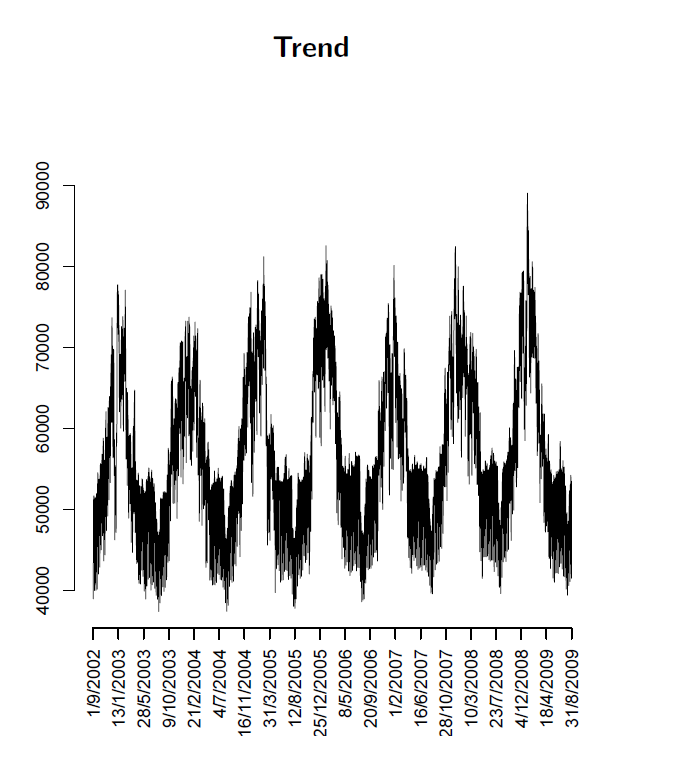
This is an interesting deck because it maps key steps in using semi-parametric models and illustrates real world system power load or demand data, as in this exhibit of annual variation showing the trend over several years.
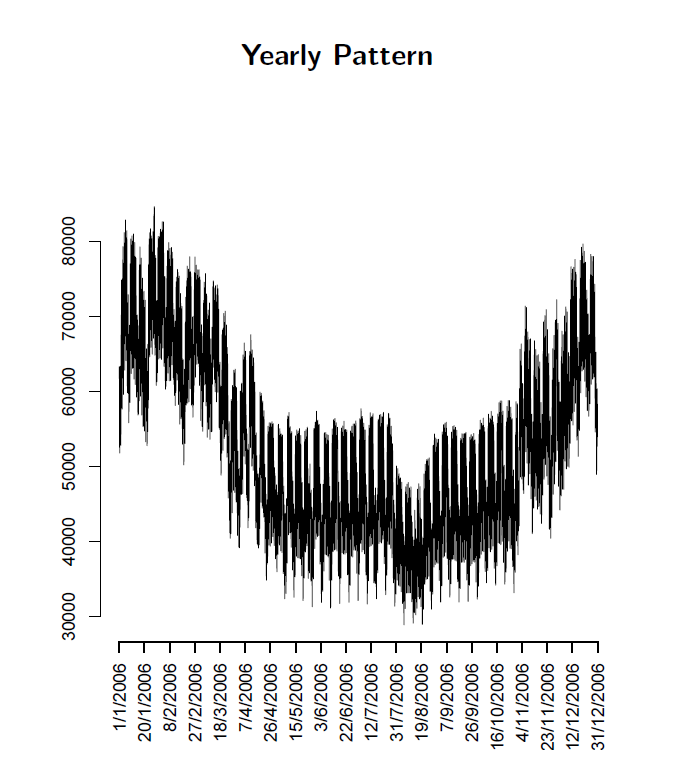
Or this exhibit showing annual variation.
What intrigues me about the EDF approach in the competition and, apparently, more generally in their actual load forecasting, is the use of splines and knots. I’ve seen this basic approach applied in other time series contexts, for example, to facilitate bagging estimates.
So these competitions seem to provide solid results which can be applied in a real-world setting.
Top image from Triple-Curve