A couple of years or so ago, I analyzed a software customer satisfaction survey, focusing on larger corporate users. I had firmagraphics – specifying customer features (size, market segment) – and customer evaluation of product features and support, as well as technical training. Altogether, there were 200 questions that translated into metrics or variables, along with measures of customer satisfaction. Altogether, the survey elicited responses from about 5000 companies.
Now this is really sort of an Ur-problem for me. How do you discover relationships in this sort of data space? How do you pick out the most important variables?
Since researching this blog, I’ve learned a lot about this problem. And one of the more fascinating approaches is the recent development named complete subset regressions.
And before describing some Monte Carlo exploring this approach here, I’m pleased Elliot, Gargano, and Timmerman (EGT) validate an intuition I had with this “Ur-problem.” In the survey I mentioned above, I calculated a whole bunch of univariate regressions with customer satisfaction as the dependent variable and each questionnaire variable as the explanatory variable – sort of one step beyond calculating simple correlations. Then, it occurred to me that I might combine all these 200 simple regressions into a predictive relationship. To my surprise, EGT’s research indicates that might have worked, but not be as effective as complete subset regression.
Complete Subset Regression (CSR) Procedure
As I understand it, the idea behind CSR is you run regressions with all possible combinations of some number r less than the total number n of candidate or possible predictors. The final prediction is developed as a simple average of the forecasts from these regressions with r predictors. While some of these regressions may exhibit bias due to specification error and covariance between included and omitted variables, these biases tend to average out, when the right number r < n is selected.
So, maybe you have a database with m observations or cases on some target variable and n predictors.
And you are in the dark as to which of these n predictors or potential explanatory variables really do relate to the target variable.
That is, in a regression y = β0+β1 x1 +…+βn xn some of the beta coefficients may in fact be zero, since there may be zero influence between the associated xi and the target variable y.
Of course, calling all the n variables xi i=1,…n “predictor variables” presupposes more than we know initially. Some of the xi could in fact be “irrelevant variables” with no influence on y.
In a nutshell, the CSR procedure involves taking all possible combinations of some subset r of the n total number of potential predictor variables in the database, and mapping or regressing all these possible combinations onto the dependent variable y. Then, for prediction, an average of the forecasts of all these regressions is often a better predictor than can be generated by other methods – such as the LASSO or bagging.
EGT offer a time series example as an empirical application. based on stock returns, quarterly from 1947-2010 and twelve (12) predictors. The authors determine that the best results are obtained with a small subset of the twelve predictors, and compare these results with ridge regression, bagging, Lasso and Bayesian Model Averaging.
The article in The Journal of Econometrics is well-worth purchasing, if you are not a subscriber. Otherwise, there is a draft in PDF format from 2012.
The combination of n things taken r at a time is n!/[(n-r)!(r!)] and increases faster than exponentially, as n increases. For large n, accordingly, it is necessary to sample from the possible set of combinations – a procedure which still can generate improvements in forecast accuracy over a “kitchen sink” regression (under circumstances further delineated below). Otherwise, you need a quantum computer to process very fat databases.
When CSR Works Best – Professor Elloitt
I had email correspondence with Professor Graham Elliott, one of the co-authors of the above-cited paper in the Journal of Econometrics.
His recommendation is that CSR works best with when there are “weak predictors” sort of buried among a superset of candidate variables,
If a few (say 3) of the variables have large coefficients such as that they result in a relatively large R-square for the prediction regression when they are all included, then CSR is not likely to be the best approach. In this case model selection has a high chance of finding a decent model, the kitchen sink model is not all that much worse (about 3/T times the variance of the residual where T is the sample size) and CSR is likely to be not that great… When there is clear evidence that a predictor should be included then it should be always included…, rather than sometimes as in our method. You will notice that in section 2.3 of the paper that we construct properties where beta is local to zero – what this math says in reality is that we mean the situation where there is very little clear evidence that any predictor is useful but we believe that some or all have some minor predictive ability (the stock market example is a clear case of this). This is the situation where we expect the method to work well. ..But at the end of the day, there is no perfect method for all situations.
I have been toying with “hidden variables” and, then, measurement error in the predictor variables in simulations that further validate Graham Elliot’s perspective that CSR works best with “weak predictors.”
Monte Carlo Simulation
Here’s the spreadsheet for a relevant simulation (click to enlarge).
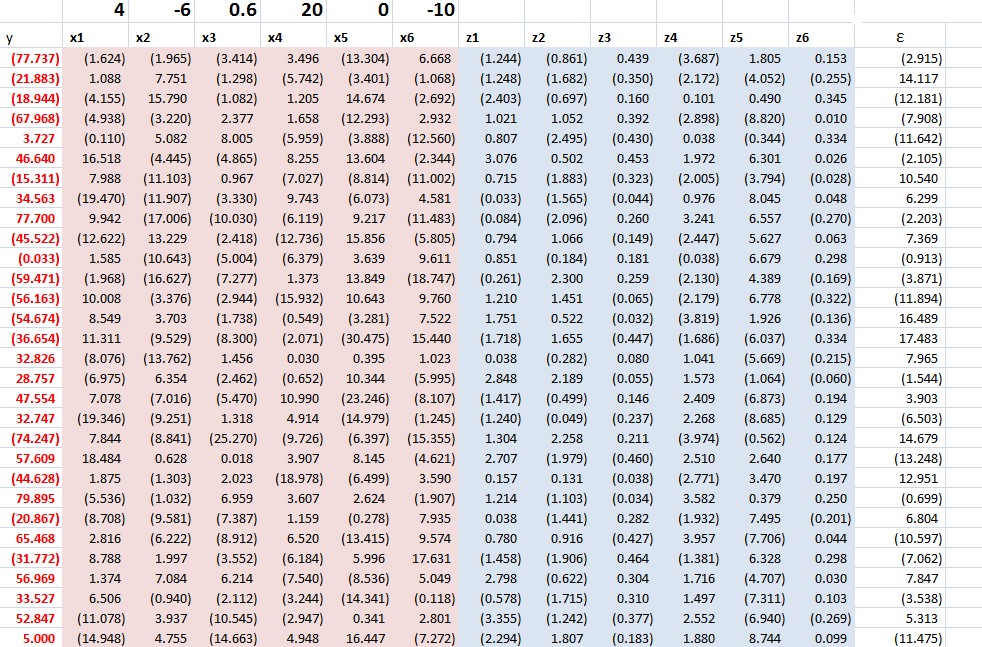
It is pretty easy to understand this spreadsheet, but it may take a few seconds. It is a case of latent variables, or underlying variables disguised by measurement error.
The z values determine the y value. The z values are multiplied by the bold face numbers in the top row, added together, and then the epsilon error ε value is added to this sum of terms to get each y value. You have to associate the first bold face coefficient with the first z variable, and so forth.
At the same time, an observer only has the x values at his or her disposal to estimate a predictive relationship.
These x variables are generated by adding a Gaussian error to the corresponding value of the z variables.
Note that z5 is an irrelevant variable, since its coefficient loading is zero.
This is a measurement error situation (see the lecture notes on “measurement error in X variables” ).
The relationship with all six regressors – the so-called “kitchen-sink” regression – clearly shows a situation of “weak predictors.”
I consider all possible combinations of these 6 variables, taken 3 at a time, or 20 possible distinct combinations of regressors and resulting regressions.
In terms of the mechanics of doing this, it’s helpful to set up the following type of listing of the combinations.

Each digit in the above numbers indicates a variable to include. So 123 indicates a regression with y and x1, x2, and x3. Note that writing the combinations in this way so they look like numbers in order of increasing size can be done by a simple algorithm for any r and n.
And I can generate thousands of cases by allowing the epsilon ε values and other random errors to vary.
In the specific run above, the CSR average soundly beats the mean square error (MSE) of this full specification in forecasts over ten out-of-sample values. The MSE of the kitchen sink regression, thus, is 2,440 while the MSE of the regression specifying all six regressors is 2653. It’s also true that picking the lowest within-sample MSE among the 20 possible combinations for k = 3 does not produce a lower MSE in the out-of-sample run.
This is characteristics of results in other draws of the random elements. I hesitate to characterize the totality without further studying the requirements for the number of runs, given the variances, and so forth.
I think CSR is exciting research, and hope to learn more about these procedures and report in future posts.