In a recent post on logistic regression, I mentioned research which developed diagnostic tools for breast cancer based on true Big Data parameters – notably 62,219 consecutive mammography records from 48,744 studies in 18,270 patients reported using the Breast Imaging Reporting and Data System (BI-RADS) lexicon and the National Mammography Database format between April 5, 1999 and February 9, 2004.
This research built a logistic regression model with 36 predictors, selected from the following information residing in the National Mammography Database (click to enlarge).
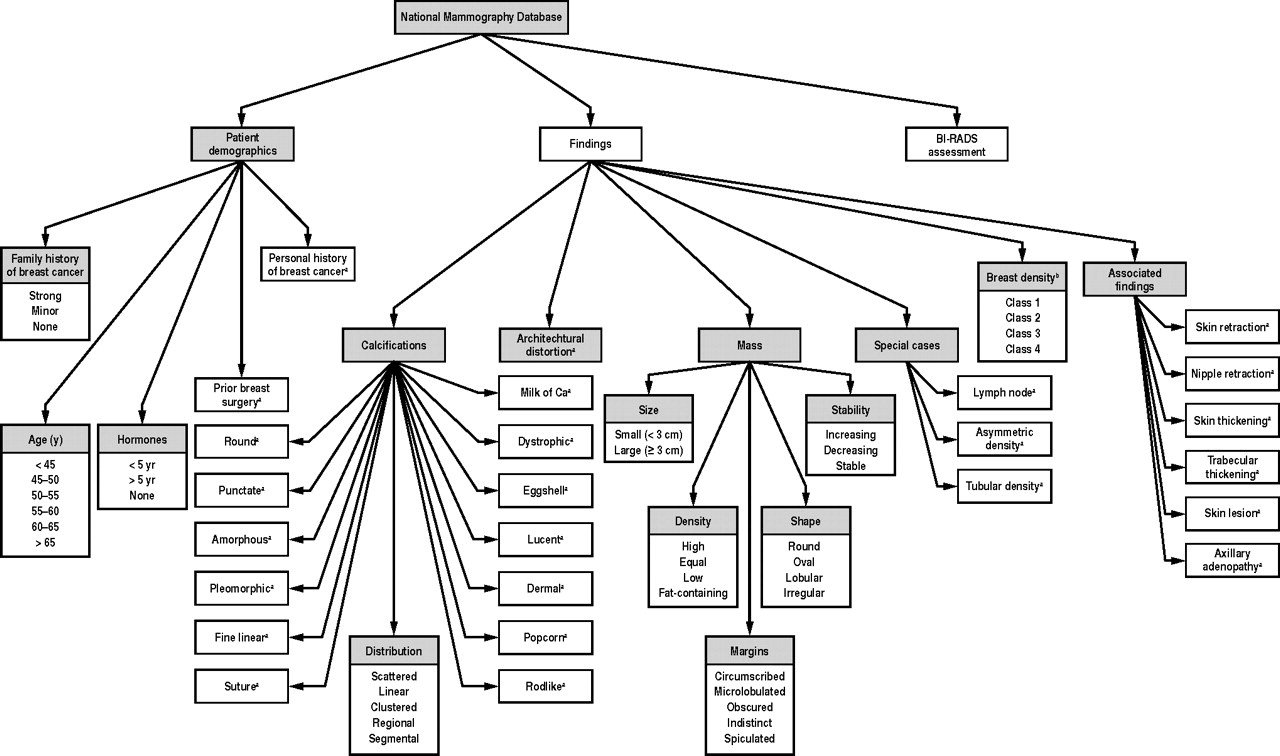
The question arises – are all these 36 predictors significant? Or what is the optimal model? How does one select the subset of the available predictor variables which really count?
This is the problem of selecting predictors in multivariate analysis – my focus for several posts coming up.
So we have a target variable y and set of potential predictors x={x1,x2,….,xn}. We are interested in discovering a predictive relationship, y=F(x*) where x* is some possibly proper subset of x. Furthermore, we have data comprising m observations on y and x, which in due time we will label with subscripts.
There are a range of solutions to this very real, very practical modeling problem.
Here is my short list.
- Forward Selection. Begin with no candidate variables in the model. Select the variable that boosts some goodness-of-fit or predictive metric the most. Traditionally, this has been R-Squared for an in-sample fit. At each step, select the candidate variable that increases the metric the most. Stop adding variables when none of the remaining variables are significant. Note that once a variable enters the model, it cannot be deleted.
- Backward Selection. This starts with the superset of potential predictors and eliminates variables which have the lowest score by some metric – traditionally, the t-statistic.
- Stepwise regression. This combines backward and forward selection of regressors.
- Regularization and Selection by means of the LASSO. Here is the classic article and here is a post, and here is a post in this blog on the LASSO.
- Information criteria applied to all possible regressions – pick the best specification by applying the Aikaike Information Criterion (AIC) or Bayesian Information Criterion (BIC) to all possible combinations of regressors. Clearly, this is only possible with a limited number of potential predictors.
- Cross-validation or other out-of-sample criteria applied to all possible regressions – Typically, the error metrics on the out-of-sample data cuts are averaged, and the lowest average error model is selected out of all possible combinations of predictors.
- Dimension reduction or data shrinkage with principal components. This is a many predictors formulation, whereby it is possible to reduce a large number of predictors to a few principal components which explain most of the variation in the data matrix.
- Dimension reduction or data shrinkage with partial least squares. This is similar to the PC approach, but employs a reduction to information from both the set of potential predictors and the dependent or target variable.
There certainly are other candidate techniques, but this is a good list to start with.
Wonderful topic, incidentally. Dives right into the inner sanctum of the mysteries of statistical science as practiced in the real world.
Let me give you the flavor of how hard it is to satisfy the classical criterion for variable selection, arriving at unbiased or consistent estimates of effects of a set of predictors.
And, really, the paradigmatic model is ordinary least squares (OLS) regression in which the predictive function F(.) is linear.
The Specification Problem
The problem few analysts understand is called specification error.
So assume that there is a true model – some linear expression in variables multiplied by their coefficients, possibly with a constant term added.
Then, we have some data to estimate this model.
Now the specification problem is that when predictors are not orthogonal, i.e. when they are correlated, leaving out a variable from the “true” specification imparts a bias to the estimates of coefficients of variables included in the regression.
This complications sequential methods of selecting predictors for the regression.
So in any case I will have comments forthcoming on methods of selecting predictors.