While I dig deeper on the current business outlook and one or two other issues, here are some links for this pre-Fourth of July week.
Predictive Analytics
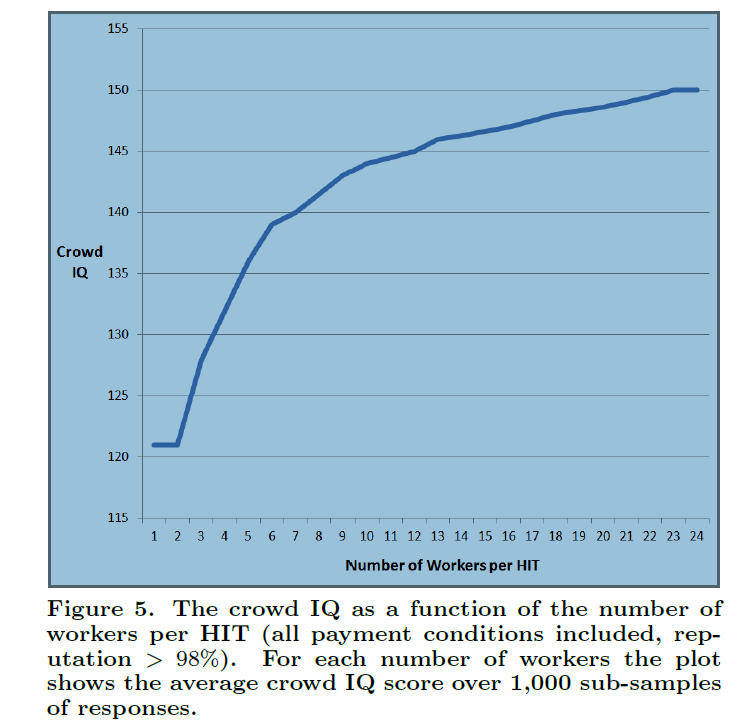
A bunch of papers about the widsom of smaller, smarter crowds I think the most interesting of these (which I can readily access) is Identifying Expertise to Extract the Wisdom of Crowds which develops a way by eliminating poorly performing individuals from the crowd to improve the group response.
Application of Predictive Analytics in Customer Relationship Management: A Literature Review and Classification From the Proceedings of the Southern Association for Information Systems Conference, Macon, GA, USA March 21st–22nd, 2014. Some minor problems with writing English in the article, but solid contribution.
US and Global Economy
Nouriel Roubini: There’s ‘schizophrenia’ between what stock and bond markets tell you Stocks tell you one thing, but bond yields suggest another. Currently, Roubini is guardedly optimistic – Eurozone breakup risks are receding, US fiscal policy is in better order, and Japan’s aggressively expansionist fiscal policy keeps deflation at bay. On the other hand, there’s the chance of a hard landing in China, trouble in emerging markets, geopolitical risks (Ukraine), and growing nationalist tendencies in Asia (India). Great list, and worthwhile following the links.
The four stages of Chinese growth Michael Pettis was ahead of the game on debt and China in recent years and is now calling for reduction in Chinese growth to around 3-4 percent annually.
Because of rapidly approaching debt constraints China cannot continue what I characterize as the set of “investment overshooting” economic polices for much longer (my instinct suggests perhaps three or four years at most). Under these policies, any growth above some level – and I would argue that GDP growth of anything above 3-4% implies almost automatically that “investment overshooting” policies are still driving growth, at least to some extent – requires an unsustainable increase in debt. Of course the longer this kind of growth continues, the greater the risk that China reaches debt capacity constraints, in which case the country faces a chaotic economic adjustment.
Politics
Is This the Worst Congress Ever? Barry Ritholtz decries the failure of Congress to lower interest rates on student loans, observing –
As of July 1, interest on new student loans rises to 4.66 percent from 3.86 percent last year, with future rates potentially increasing even more. This comes as interest rates on mortgages and other consumer credit hovered near record lows. For a comparison, the rate on the 10-year Treasury is 2.6 percent. Congress could have imposed lower limits on student-loan rates, but chose not to.
This is but one example out of thousands of an inability to perform the basic duties, which includes helping to educate the next generation of leaders and productive citizens. It goes far beyond partisanship; it is a matter of lack of will, intelligence and ability.
Hear, hear.
Climate Change
Climate news: Arctic seafloor methane release is double previous estimates, and why that matters This is a ticking time bomb. Article has a great graphic (shown below) which contrasts the projections of loss of Artic sea ice with what actually is happening – underlining that the facts on the ground are outrunning the computer models. Methane has more than an order of magnitude more global warming impact that carbon dioxide, per equivalent mass.
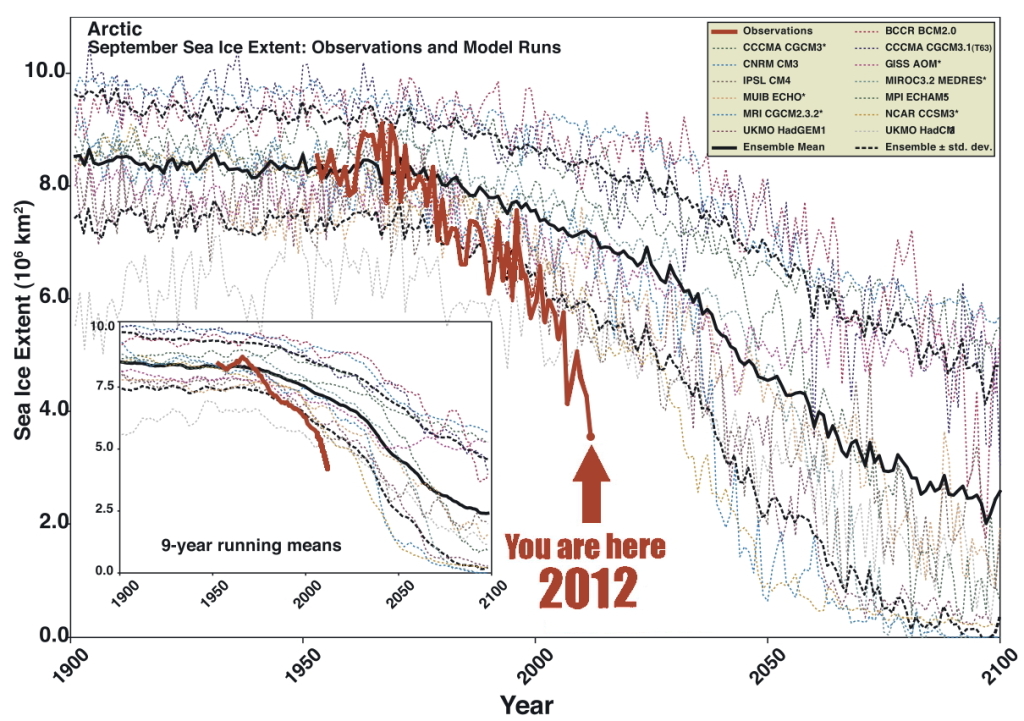
I think the sea level rise is the most concerning. Not because it’s the biggest threat, although it is an enormous threat, but because it is the most irrefutable outcome of the ice loss. We can debate about what the loss of sea ice would mean for ocean circulation. We can debate what a warming Arctic means for global and regional climate. But there’s no question what an added meter or two of sea level rise coming from the Greenland ice sheet would mean for coastal regions. It’s very straightforward.
Machine Learning
Computer simulating 13-year-old boy becomes first to pass Turing test A milestone – “Eugene Goostman” fooled more than a third of the Royal Society testers into thinking they were texting with a human being, during a series of five minute keyboard conversations.
The Milky Way Project: Leveraging Citizen Science and Machine Learning to Detect Interstellar Bubbles Combines Big Data and crowdsourcing.