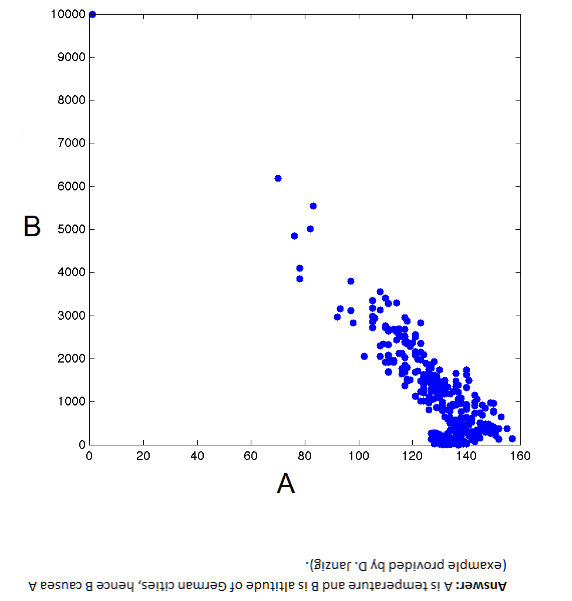
Bergmeir, Hyndman, and Benıtez (BHB) successfully combine two powerful techniques – exponential smoothing and bagging (bootstrap aggregation) – in ground-breaking research.
I predict the forecasting system described in Bagging Exponential Smoothing Methods using STL Decomposition and Box-Cox Transformation will see wide application in business and industry forecasting.
These researchers demonstrate their algorithms for combining exponential smoothing and bagging outperform all other forecasting approaches in the M3 forecasting competition database for monthly time series, and do better than many approaches for quarterly and annual data. Furthermore, the BHB approach can be implemented with extant routines in the programming language R.
This table compares bagged exponential smoothing with other approaches on monthly data from the M3 competition.
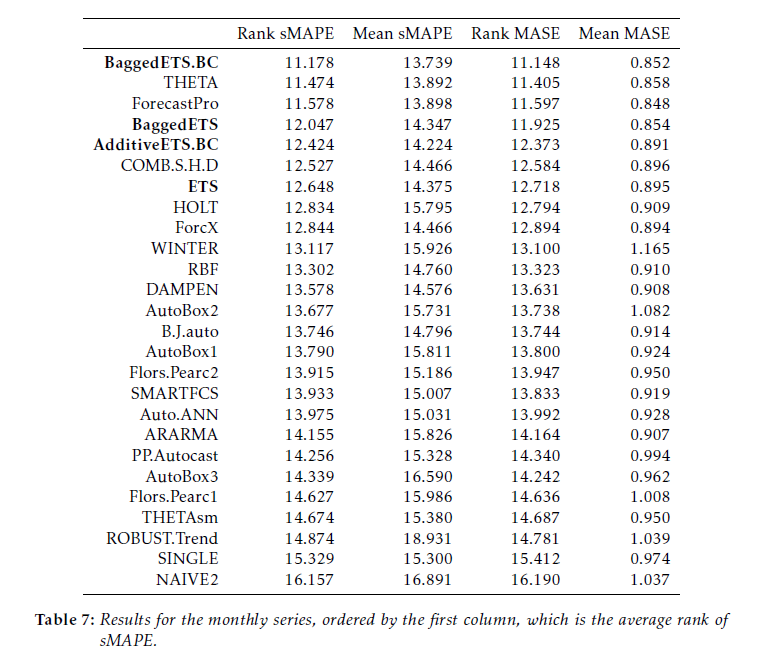
Here BaggedETS.BC refers to a variant of the bagged exponential smoothing model which uses a Box Cox transformation of the data to reduce the variance of model disturbances, The error metrics are the symmetric mean absolute percentage error (sMAPE) and the mean absolute scaled error (MASE). These are calculated for applications of the various models to out-of-sample, holdout, or test sample data from each of 1428 monthly time series in the competition.
See the online text by Hyndman and Athanasopoulos for motivations and discussions of these error metrics.
The BHB Algorithm
In a nutshell, here is the BHB description of their algorithm.
After applying a Box-Cox transformation to the data, the series is decomposed into trend, seasonal and remainder components. The remainder component is then bootstrapped using the MBB, the trend and seasonal components are added back, and the Box-Cox transformation is inverted. In this way, we generate a random pool of similar bootstrapped time series. For each one of these bootstrapped time series, we choose a model among several exponential smoothing models, using the bias-corrected AIC. Then, point forecasts are calculated using all the different models, and the resulting forecasts are averaged.
The MBB is the moving block bootstrap. It involves random selection of blocks of the remainders or residuals, preserving the time sequence and, hence, autocorrelation structure in these residuals.
Several R routines supporting these algorithms have previously been developed by Hyndman et al. In particular, the ets routine developed by Hyndman and Khandakar fits 30 different exponential smoothing models to a time series, identifying the optimal model by an Akaike information criterion.
Some Thoughts
This research lays out an almost industrial-scale effort to extract more information for prediction purposes from time series, and at the same time to use an applied forecasting workhorse – exponential smoothing.
Exponential smoothing emerged as a forecasting technique in applied contexts in the 1950’s and 1960’s. The initial motivation was error correction from forecasts of arbitrary origin, instead of an underlying stochastic model. Only later were relationships between exponential smoothing and time series processes, such as random walks, revealed with the work of Muth and others.
The M-competitions, initially organized in the 1970’s, gave exponential smoothing a big boost, since, by some accounts, exponential smoothing “won.” This is one of the sources of the meme – simpler models beat more complex models.
Then, at the end of the 1990’s, Makridakis and others organized a penultimate M-competition which was, in fact, won by the automatic forecasting software program Forecast Pro. This program typically compares ARIMA and exponential smoothing models, picking the best model through proprietary optimization of the parameters and tests on holdout samples. As in most sales and revenue forecasting applications, the underlying data are time series.
While all this was going on, the machine learning community was ginning up new and powerful tactics, such as bagging or bootstrap aggregation. Bagging can be a powerful technique for focusing on parameter estimates which are otherwise masked by noise.
So this application and research builds interestingly on a series of efforts by Hyndman and his associates and draws in a technique that has been largely confined to machine learning and data mining.
It is really almost the first of its kind – where bagging applications to time series forecasting have been less spectacularly successful than in cross-sectional regression modeling, for example.
A future post here will go through the step-by-step of this approach using some specific and familiar time series from the M competition data.