My reading on procedures followed by the Bureau of Labor Statistics (BLS) and the Bureau of Economic Analysis (BLS) suggests some key US macroeconomic data series are in a profound state of disarray. Never-ending budget cuts to these “non-essential” agencies, since probably the time of Bill Clinton, have taken their toll.
For example, for some years now it has been impossible for independent analysts to verify or replicate real GDP and many other numbers issued by the BEA, since, only SA (seasonally adjusted) series are released, originally supposedly as an “economy measure.” Since estimates of real GDP growth by quarter are charged with political significance in an Election Year, this is a potential problem. And the problem is immediate, since the media naturally will interpret a weak 2nd quarter growth – less than, say, 2.9 percent – as a sign the economy has slipped into recession.
Evidence of Political Pressure on Government Statistical Agencies
John Williams has some fame with his site Shadow Government Statistics. But apart from extreme stances from time to time (“hyperinflation”), he does document the politicization of the BLS Consumer Price Index (CPI).
In a recent white paper called No. 515—PUBLIC COMMENT ON INFLATION MEASUREMENT AND THE CHAINED-CPI (C-CPI), Williams cites Katharine Abraham, former commissioner of the Bureau of Labor Statistics, when she notes,
“Back in the early winter of 1995, Federal Reserve Board Chairman Alan Greenspan testified before the Congress that he thought the CPI substantially overstated the rate of growth in the cost of living. His testimony generated a considerable amount of discussion. Soon afterwards, Speaker of the House Newt Gingrich, at a town meeting in Kennesaw, Georgia, was asked about the CPI and responded by saying, ‘We have a handful of bureaucrats who, all professional economists agree, have an error in their calculations. If they can’t get it right in the next 30 days or so, we zero them out, we transfer the responsibility to either the Federal Reserve or the Treasury and tell them to get it right.’”[v]
Abraham is quoted in newspaper articles as remembering sitting in Republican House Speaker Newt Gingrich’s office:
“ ‘He said to me, If you could see your way clear to doing these things, we might have more money for BLS programs.’ ” [vi]
The “things” in question were to move to quality adjustments for the basket of commodities used to calculate the CPI. The analogue today, of course, is the chained-CPI measure which many suggest is being promoted to slow cost-of-living adjustments in Social Security payments.
Of course, the “real” part in real GDP is linked with the CPI inflation outlook though a process supervised by the BEA.
Seasonal Adjustment Procedures for GDP
Here is a short video by Johnathan H. Wright, a young economist whose Unseasonal Seasonals? is featured in a recent issue of the Brookings Papers on Economic Activity.
Wright’s research is interesting to forecasters, because he concludes that algorithms for seasonally adjusting GDP should be selected based on their predictive performance.
Wright favors state-space models, rather than the moving-average techniques associated with the X-12 seasonal filters that date back to the 1980’s and even the 1960’s.
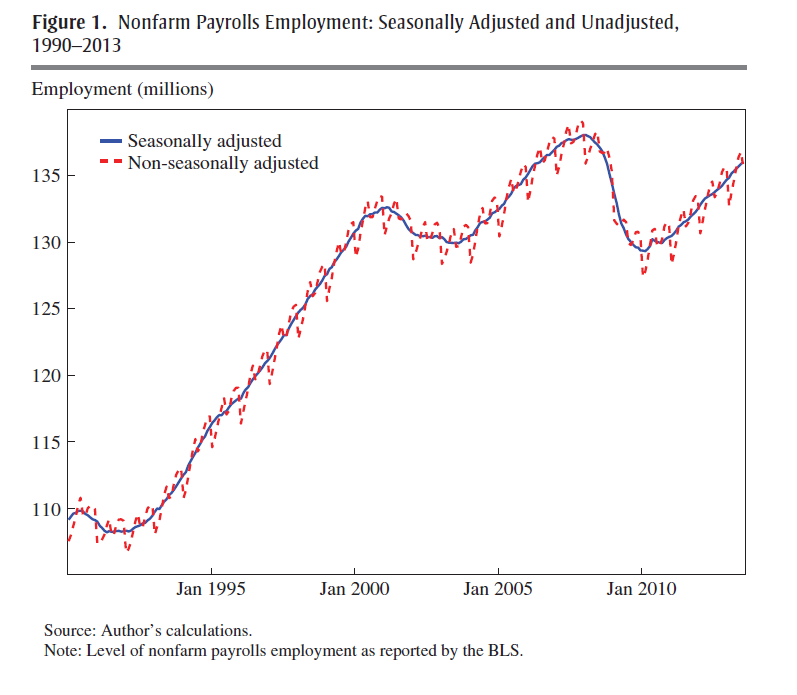
Given BLS methods of seasonal adjustment, seasonal and cyclical elements are confounded in the SA nonfarm payrolls series, due to sharp drops in employment concentrated in the November 2008 to March 2009 time window.
The upshot – initially this effect pushed reported seasonally adjusted nonfarm payrolls up in the first half of the year and down in the second half of the year, by slightly more than 100,000 in both cases…
One of his prime exhibits compares SA and NSA nonfarm payrolls, showing that,
The regular within-year variation in employment is comparable in magnitude to the effects of the 1990–1991 and 2001 recessions. In monthly change, the average absolute difference between the SA and NSA number is 660,000, which dwarfs the normal month-over-month variation in the SA data.
The basic procedure for this data and most releases since 2008-2009 follows what Wright calls the X-12 process.
The X-12 process focuses on certain types of centered moving averages with a fixed weights, based on distance from the central value.
A critical part of the X-12 process involves estimating the seasonal factors by taking weighted moving averages of data in the same period of different years. This is done by taking a symmetric n-term moving average of m-term averages, which is referred to as an n × m seasonal filter. For example, for n = m = 3, the weights are 1/3 on the year in question, 2/9 on the years before and after, and 1/9 on the two years before and after.16 The filter can be a 3 × 1, 3 × 3, 3 × 5, 3 × 9, 3 × 15, or stable filter. The stable filter averages the data in the same period of all available years. The default settings of the X-12…involve using a 3 × 3, 3 × 5, or 3 × 9 seasonal filter, depending on [various criteria]
Obviously, a problem arises at the beginning and at the end of the time series data. A work-around is to use an ARIMA model to extend the time series back and forward in time sufficiently to calculate these centered moving averages.
Wright shows these arbitrary weights and time windows lead to volatile seasonal adjustments, and that, predictively, the BEA and BLS would be better served with a state-space model based on the Kalman filter.
Loopy seasonal adjustment leads to controversy that airs on the web – such as this piece by Zero Hedge from 2012 which highlights the “ficititious” aspect of seasonal adjustments of highly tangible series, such as the number of persons employed –
What is very notable is that in January, absent BLS smoothing calculation, which are nowhere in the labor force, but solely in the mind of a few BLS employees, the real economy lost 2,689,000 jobs, while net of the adjustment, it actually gained 243,000 jobs: a delta of 2,932,000 jobs based solely on statistical assumptions in an excel spreadsheet!
To their credit, Census now documents an X-13ARIMA-SEATS Seasonal Adjustment Program with software incorporating elements of the SEATS procedure originally developed at the Bank of Spain and influenced by the state space models of Andrew Harvey.
Maybe Wright is getting some traction.
What Is The Point of Seasonal Adjustment?
You can’t beat the characterization, apparently from the German Bundesbank, of the purpose and objective of “seasonal adjustment.”
..seasonal adjustment transforms the world we live in into a world where no seasonal and working-day effects occur. In a seasonally adjusted world the temperature is exactly the same in winter as in the summer, there are no holidays, Christmas is abolished, people work every day in the week with the same intensity (no break over the weekend)..
I guess the notion is that, again, if we seasonally adjust and see a change in direction of a time series, why then it probably is a change in trend, rather than from special uses of a certain period.
But I think most of the professional forecasting community is beyond just taking their cue from a single number. It would be better to have the raw or not seasonally adjusted (NSA) series available with every press release, so analysts can apply their own models.