I often present at confabs where there are engineers with management or executive portfolios. You start the slides, but, beforehand, prepare for the tough question. Make sure the numbers in the tables add up and that round-off errors or simple typos do not creep in to mess things up.
To carry this on a bit, I recall a Hewlett Packard VP whose preoccupation during meetings was to fiddle with their calculator – which dates the story a little. In any case, the only thing that really interested them was to point out mistakes in the arithmetic. The idea is apparently that if you cannot do addition, why should anyone believe your more complex claims?
I’m bending this around to the theory of efficient markets and rational expectations, by the way.
And I’m playing the role of the engineer.
Rational Expectations
The theory of rational expectations dates at least to the work of Muth in the 1960’s, and is coupled with “efficient markets.”
Lim and Brooks explain market efficiency in – The Evolution of Stock Market Efficiency Over Time: A Survey of the Empirical Literature
The term ‘market efficiency’, formalized in the seminal review of Fama (1970), is generally referred to as the informational efficiency of financial markets which emphasizes the role of information in setting prices.. More specifically, the efficient markets hypothesis (EMH) defines an efficient market as one in which new information is quickly and correctly reflected in its current security price… the weak-form version….asserts that security prices fully reflect all information contained in the past price history of the market.
Lim and Brooks focus, among other things, on statistical tests for random walks in financial time series, noting this type of research is giving way to approaches highlighting adaptive expectations.
Proof US Stock Markets Are Not Efficient (or Maybe That HFT Saves the Concept)
I like to read mathematically grounded research, so I have looked a lot of the papers purporting to show that the hypothesis that stock prices are random walks cannot be rejected statistically.
But really there is a simple constructive proof that this literature is almost certainly wrong.
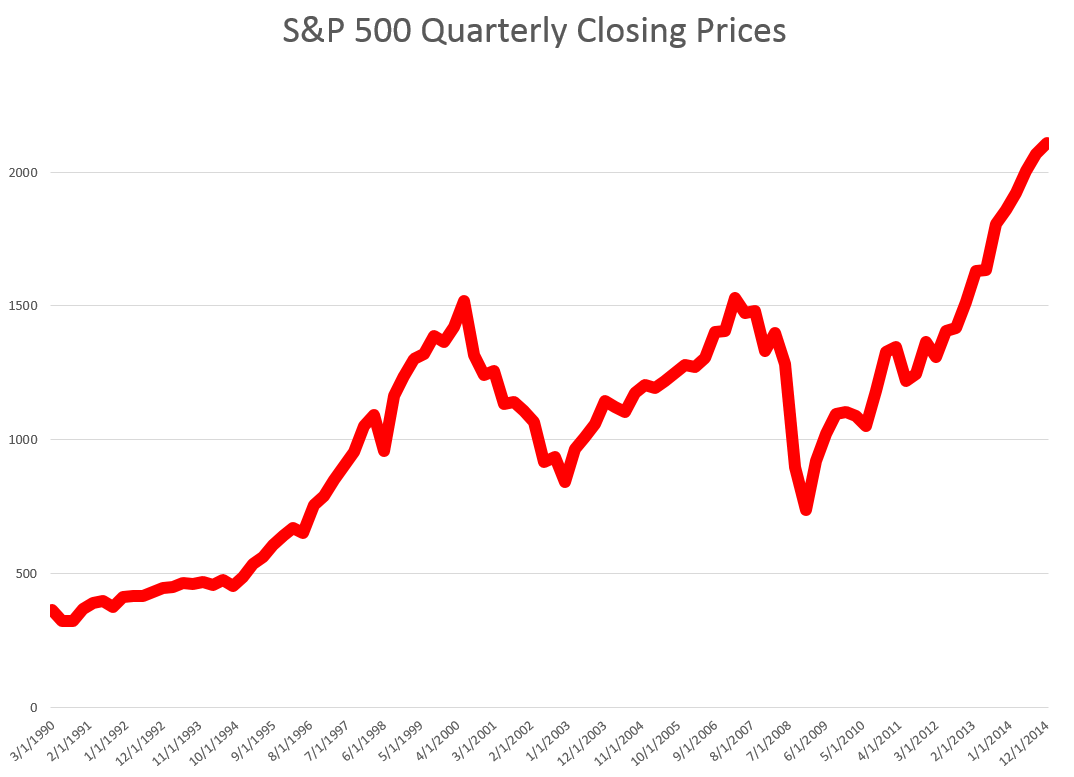
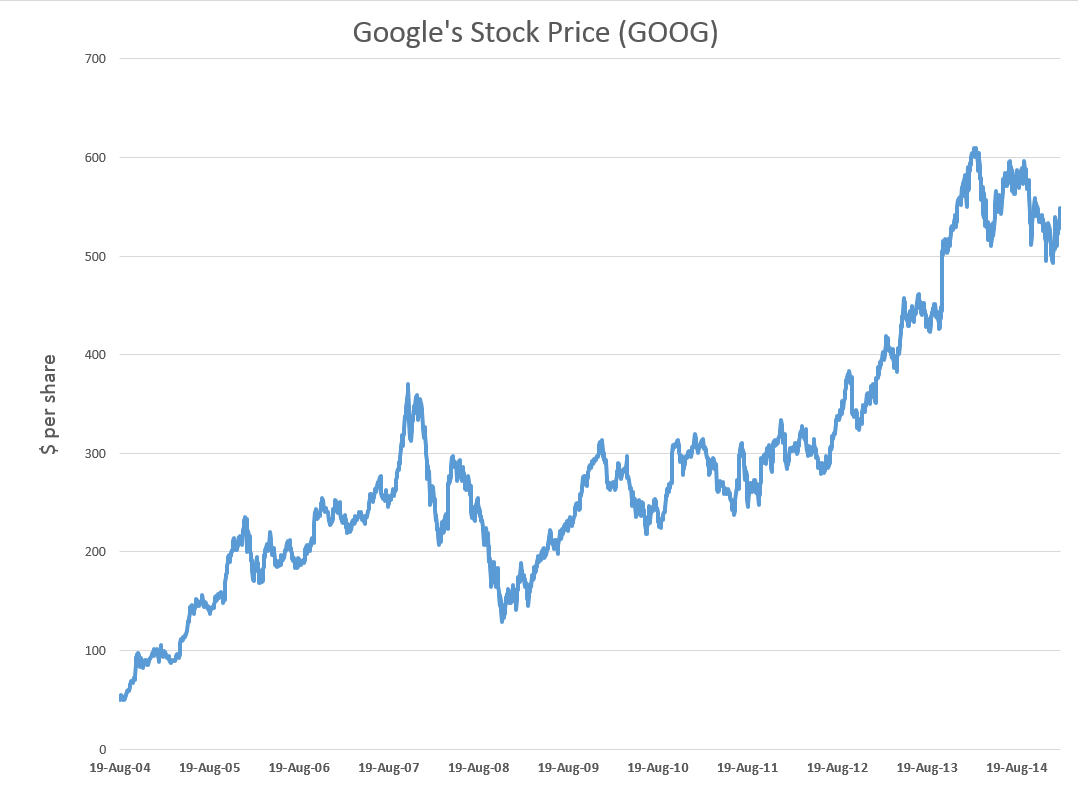
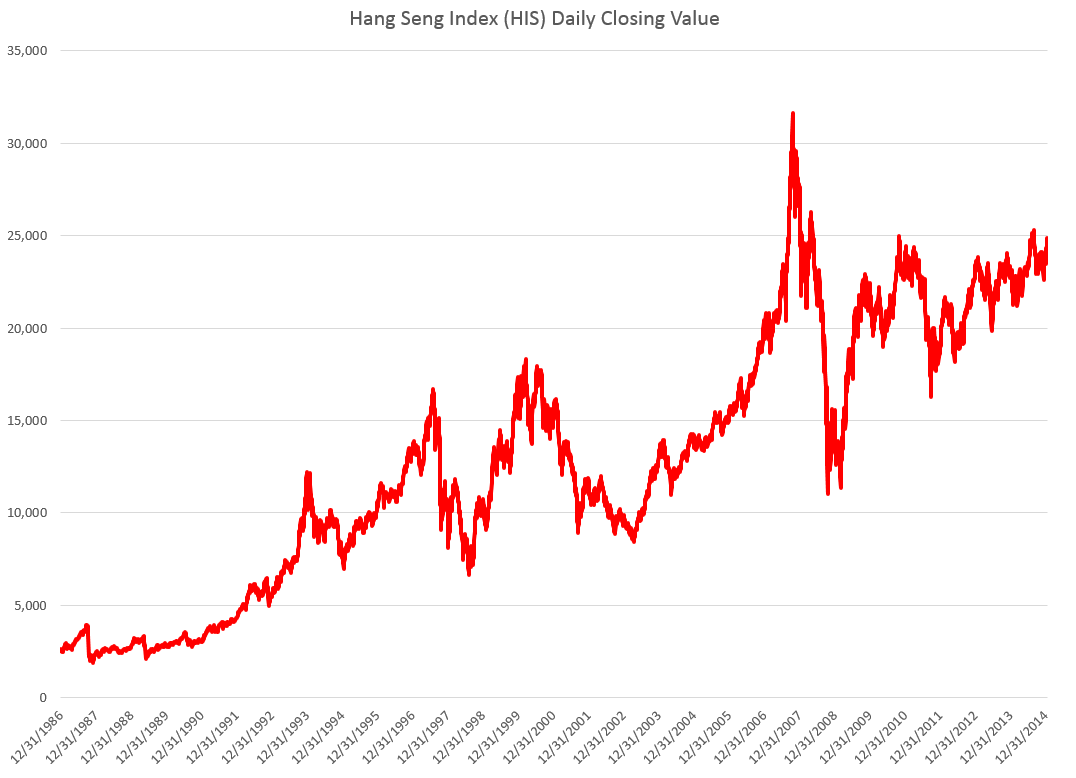
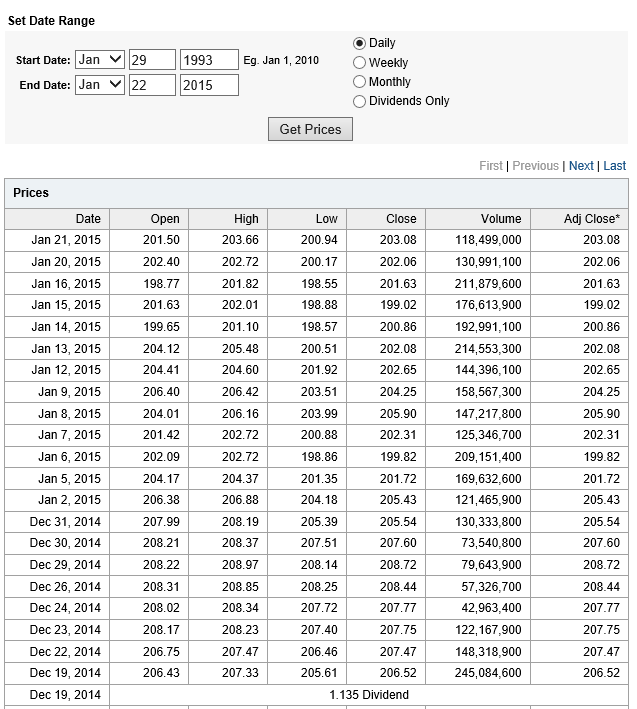
STEP 1: Grab the data. Download daily adjusted closing prices for the S&P 500 from some free site (e,g, Yahoo Finance). I did this again recently, collecting data back to 1990. Adjusted closing prices, of course, are based on closing prices for the trading day, adjusted for dividends and stock splits. Oh yeah, you may have to resort the data from oldest to newest, since a lot of sites present the newest data on top, originally.
Here’s a graph of the data, which should be very familiar by now.
STEP 2: Create the relevant data structure. In the same spreadsheet, compute the trading-day-over-treading day growth in the adjusted closing price (ACP). Then, side-by-side with this growth rate of the ACP, create another series which, except for the first value, maps the growth in ACP for the previous trading day onto the growth of the ACP for any particular day. That gives you two columns of new data.
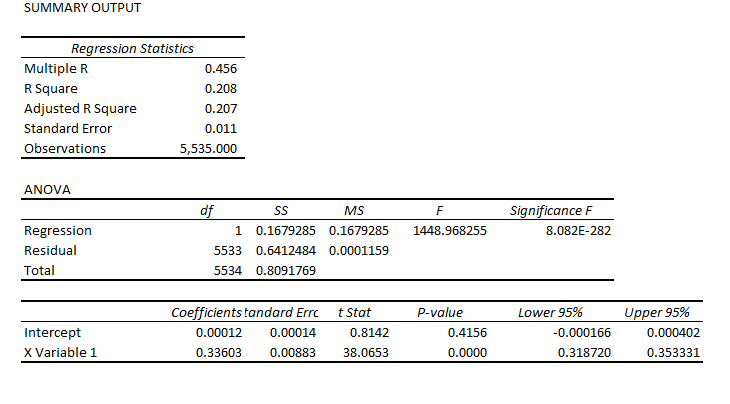
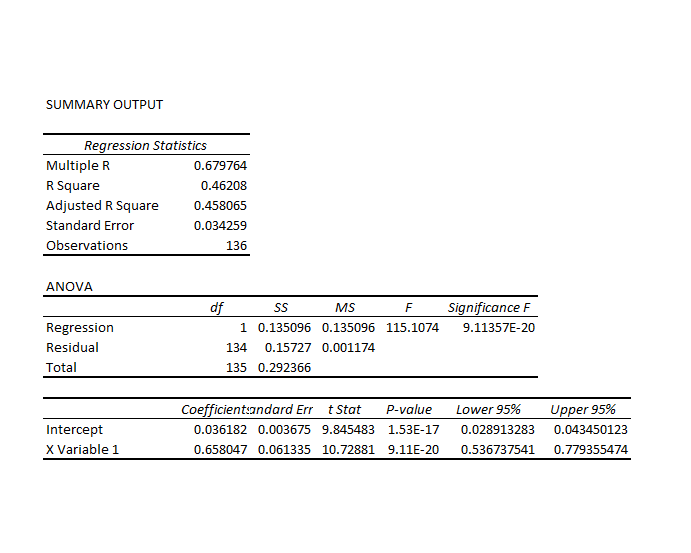
STEP 3: Run adaptive regressions. Most spreadsheet programs include an ordinary least squares (OLS) regression routine. Certainly, Excel does. In any case, you want to setup up a regression to predict the growth in the ACP, based on one trading lags in the growth of the ACP.
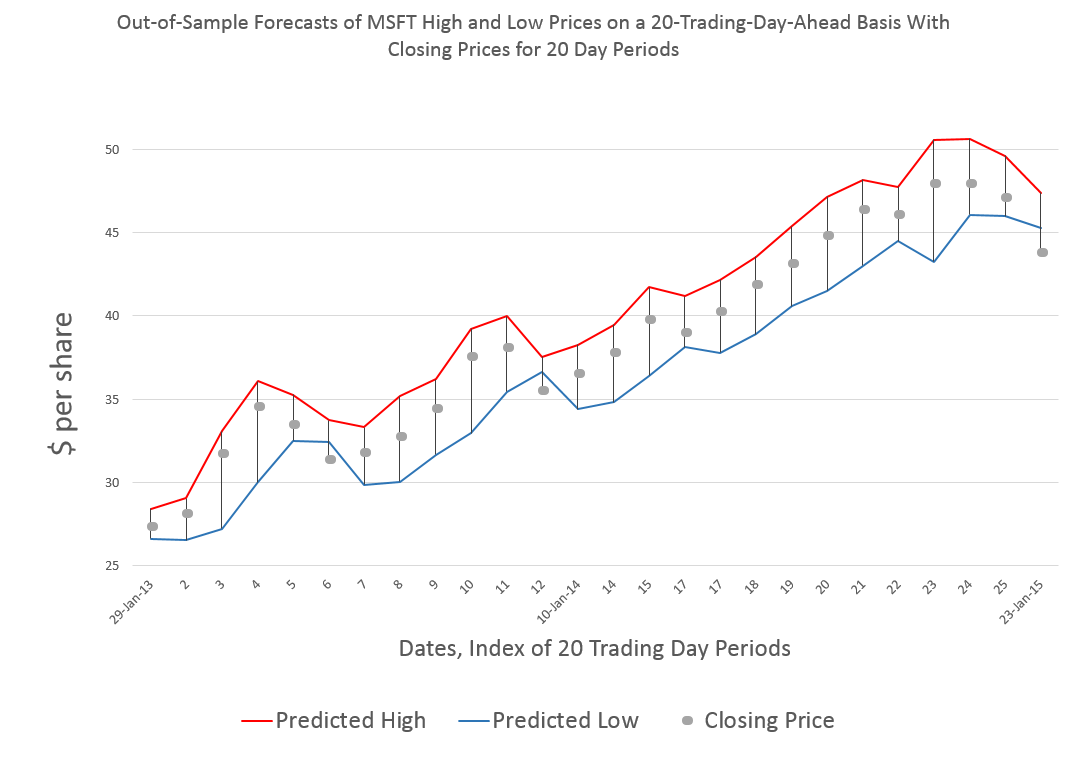
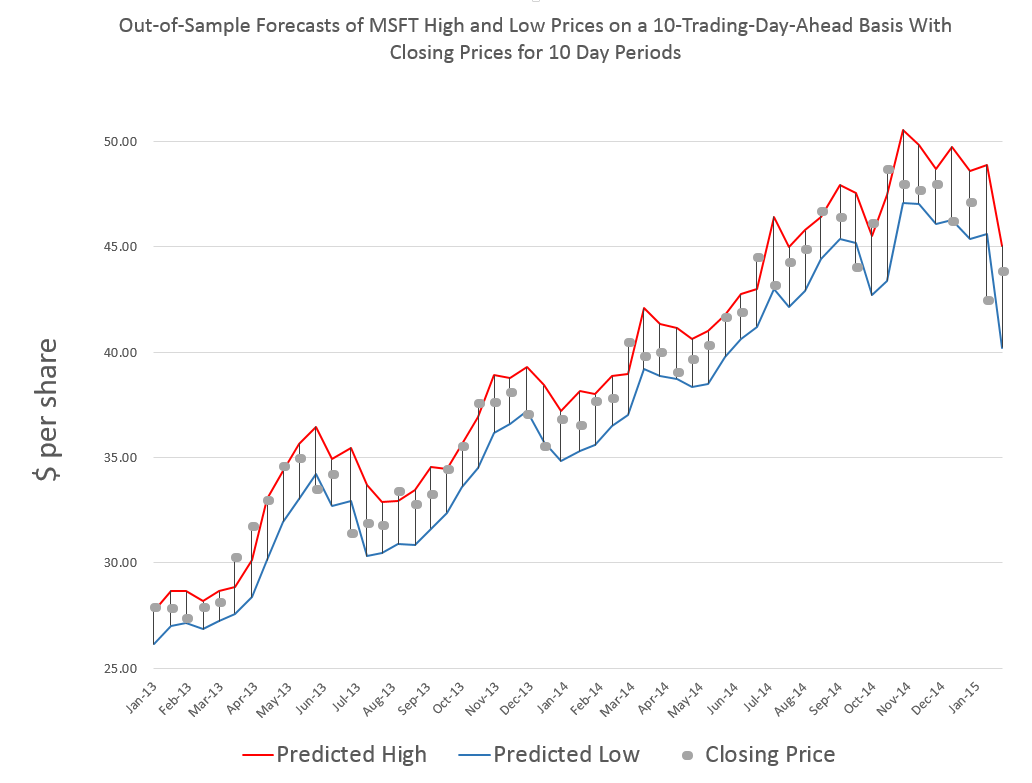
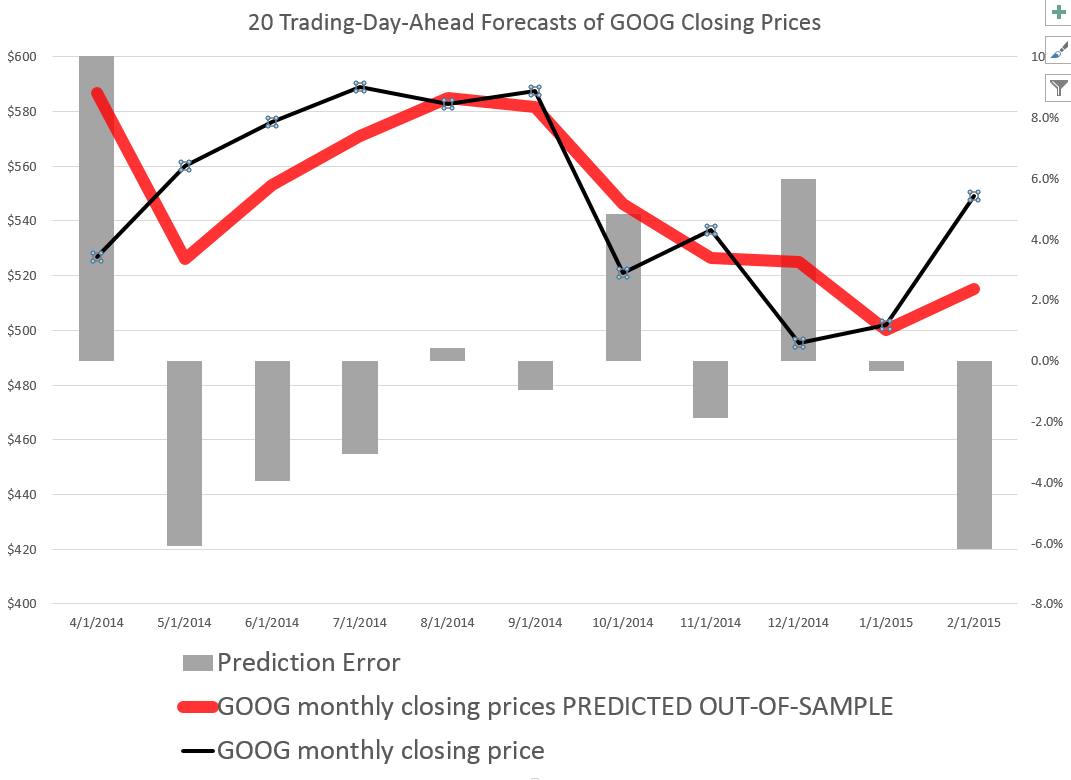
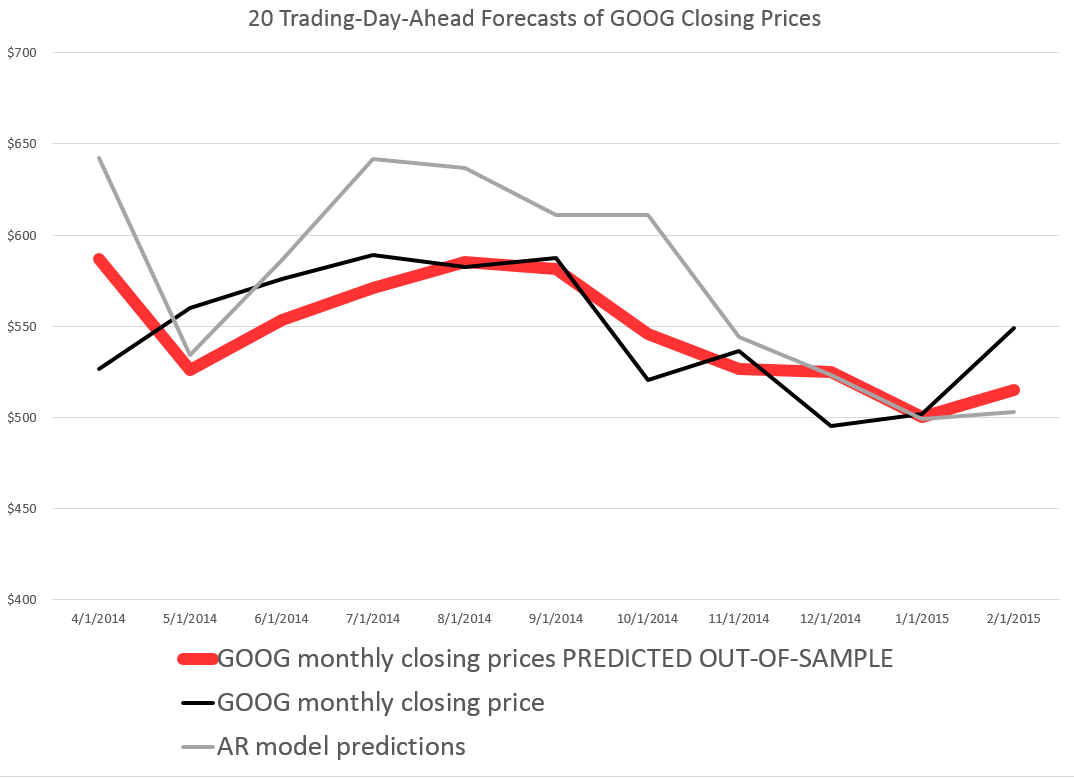
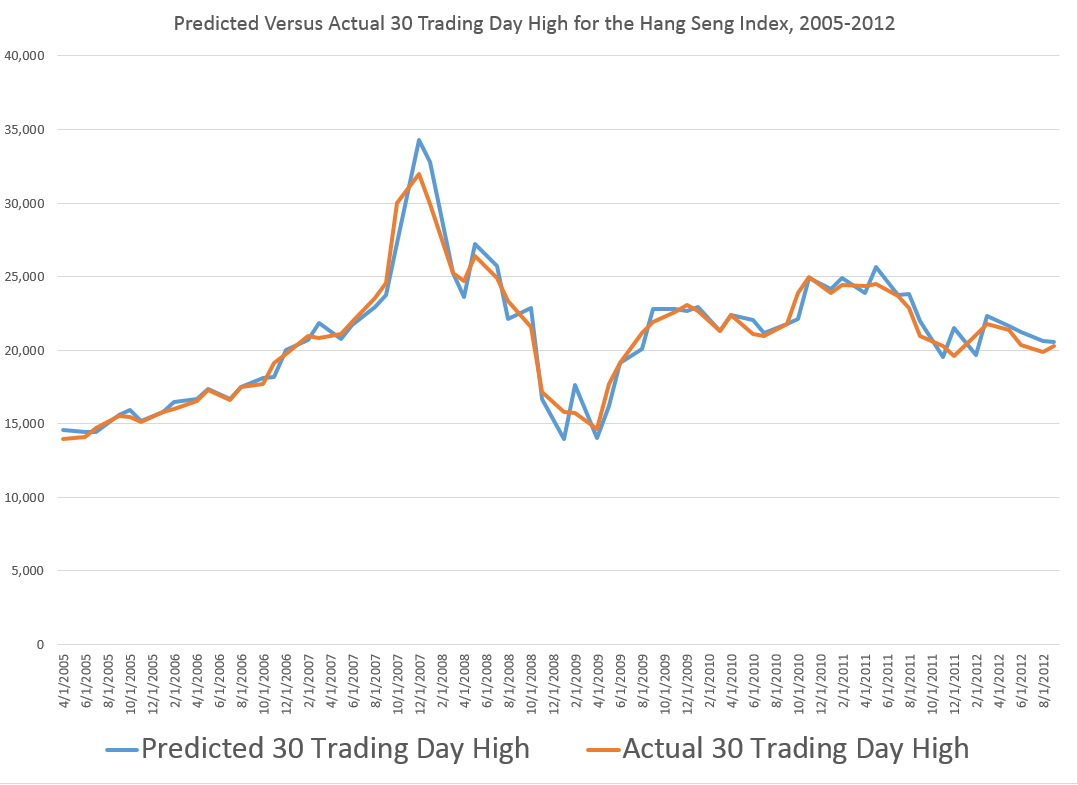
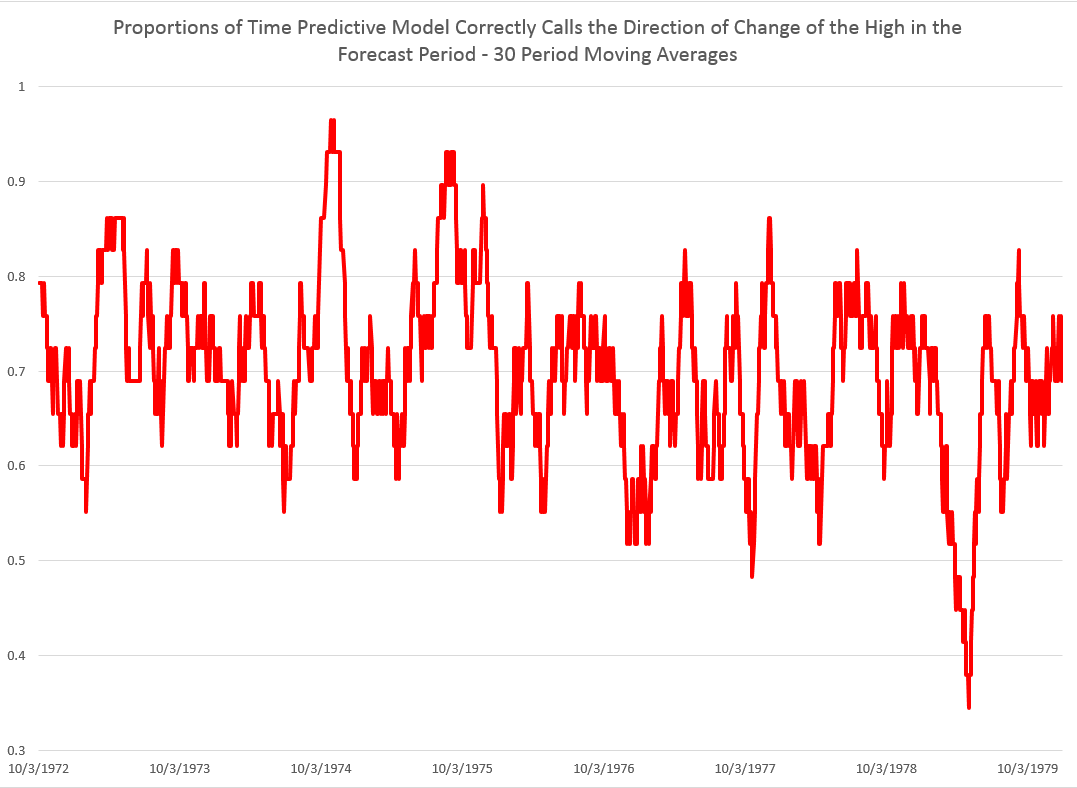
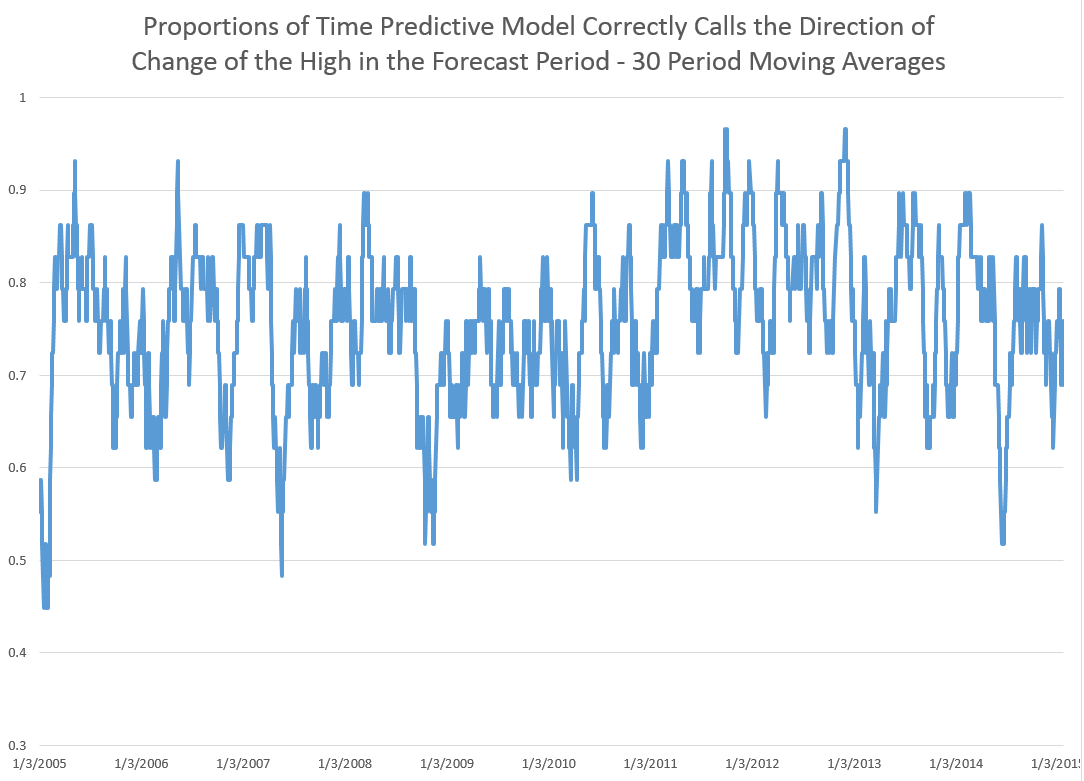
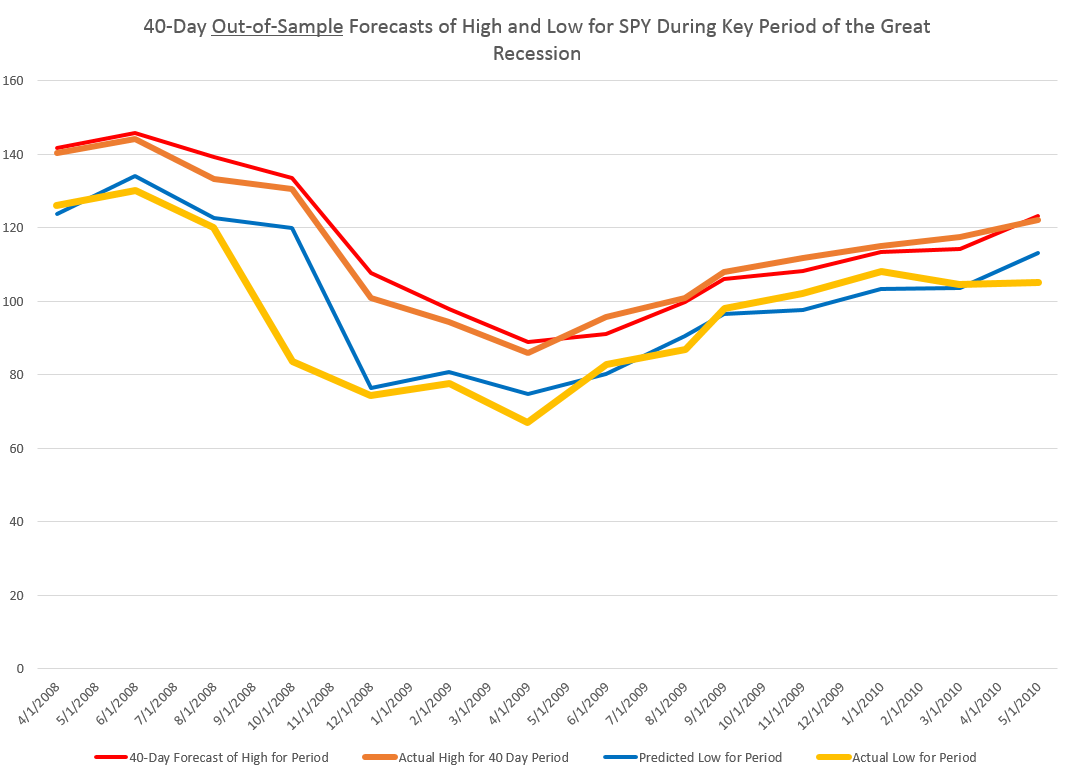
I did this, initially, to predict the growth in ACP for January 3, 2000, based on data extending back to January 3, 1990 – a total of 2528 trading days. Then, I estimated regressions going down for later dates with the same size time window of 2528 trading days.
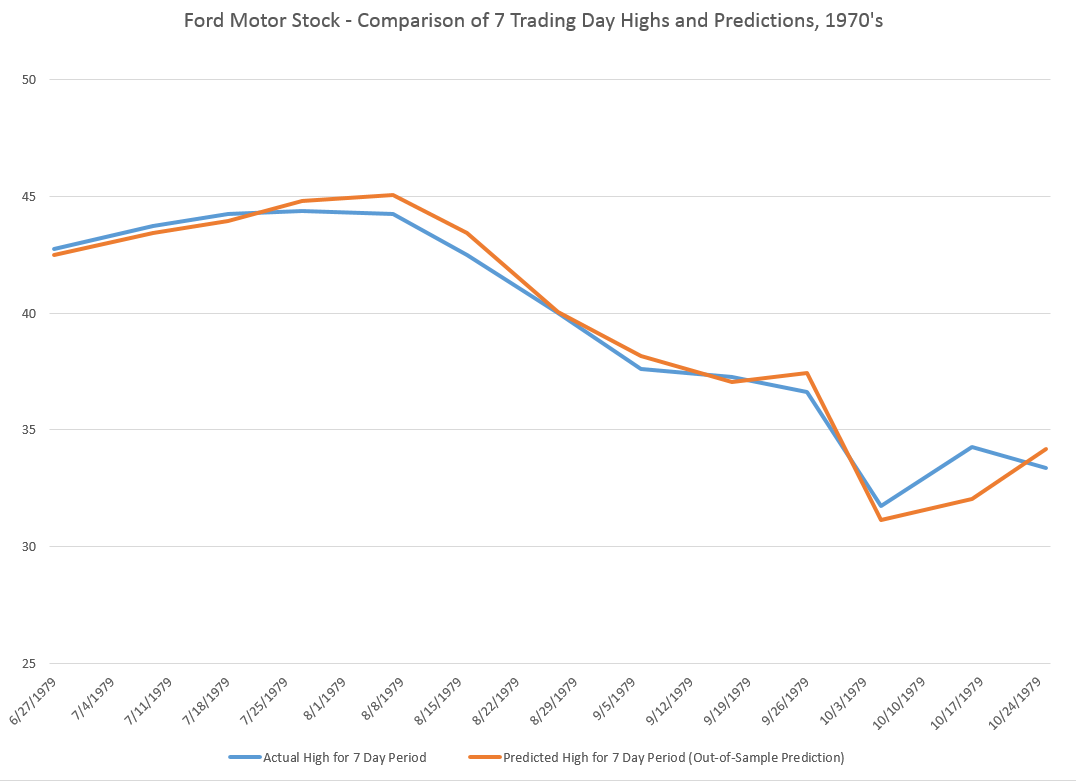
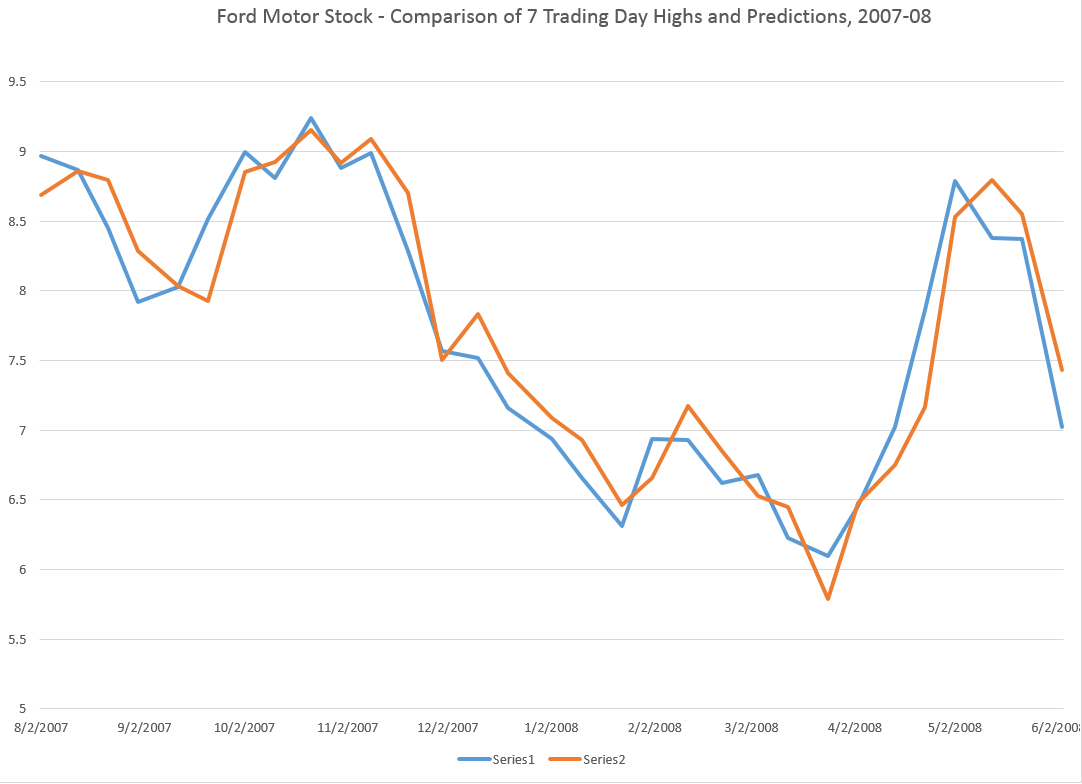
The resulting “predictions” for the growth in ACP are out-of-sample, in the sense that each prediction stands outside the sample of historic data used to develop the regression parameters used to forecast it.
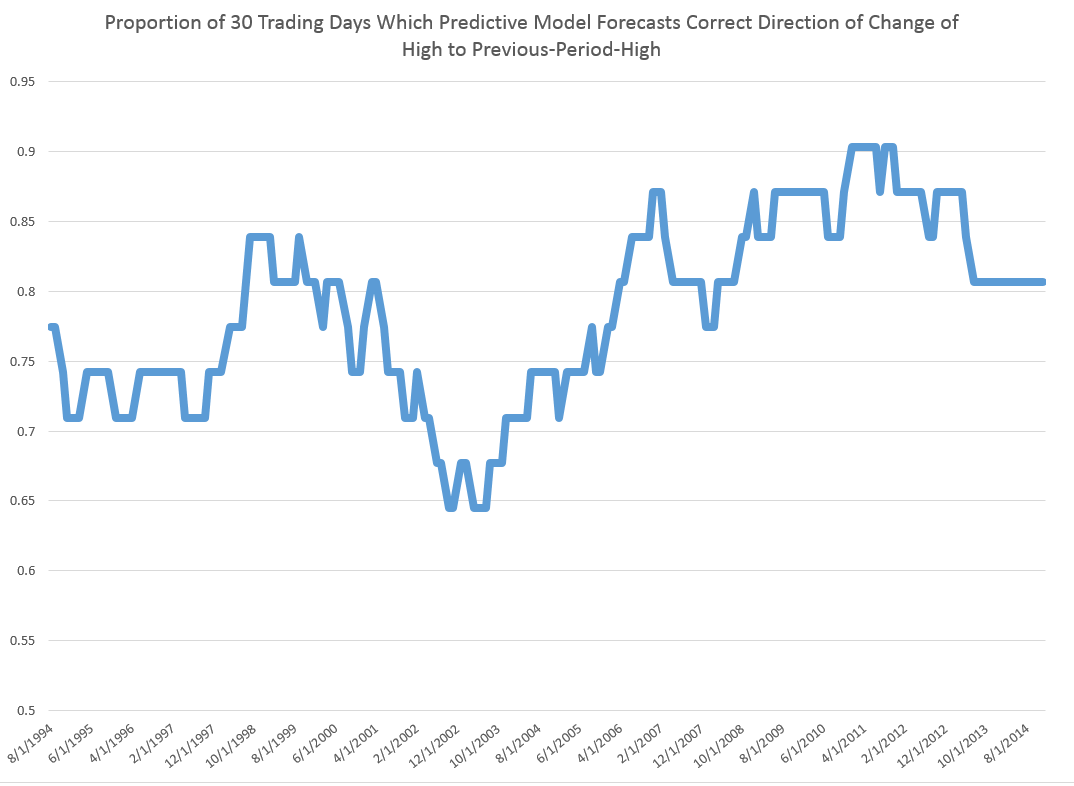
It needs to be said that these predictions for the growth of the adjusted closing price (ACP) are marginal, correctly predicting the sign of the ACP only about 53 percent of the time.
An interesting question, though, is whether these just barely predictive forecasts can be deployed in a successful trading model. Would a trading algorithm based on this autoregressive relationship beat the proverbial “buy-and-hold?”
So, for example, suppose we imagine that we can trade at closing each trading day, close enough to the actual closing prices.
Then, you get something like this, if you invest $100,000 at the beginning of 2000, and trade through last week. If the predicted growth in the ACP is positive, you buy at the previous day’s close. If not, you sell at the previous day’s close. For the Buy-and-Hold portfolio, you just invest the $100,000 January 3, 2000, and travel to Tahiti for 15 years or so.
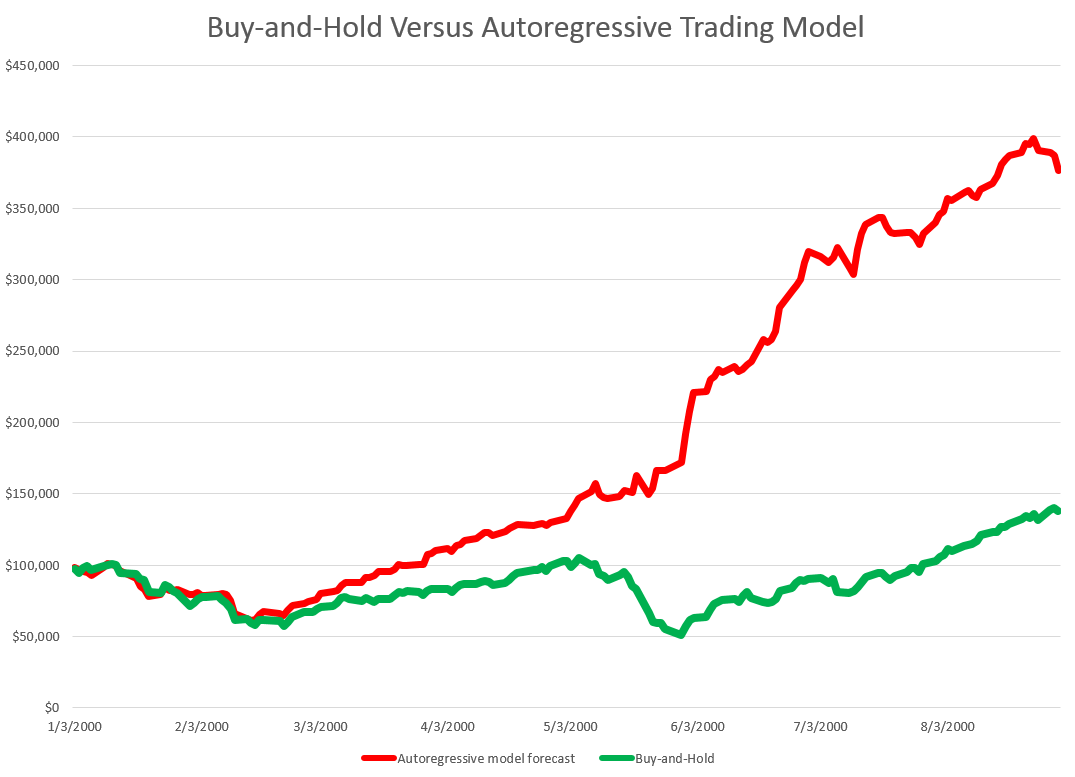
So, as should be no surprise, the Buy-and-Hold strategy results in replicating the S&P 500 Index on a $100,000 base.
The trading strategy based on the simple first order autoregressive model, on the other hand, achieves more than twice these cumulative earnings.
Now I suppose you could say that all this was an accident, or that it was purely a matter of chance, distributed over more than 3,810 trading days. But I doubt it. After all, this trading interval 2000-2015 includes the worst economic crisis since before World War II.
Or you might claim that the profits from the simple AR trading strategy would be eaten up by transactions fees and taxes. On this point, there were 1,774 trades, for an average of $163 per trade. So, worst case, if trading costs $10 a transaction, and there is a tax rate of 40 percent, that leaves $156K over these 14-15 years in terms of take-away profit, or about $10,000 a year.
Where This May Go Wrong
This does sound like a paen to stock market investing – even “day-trading.”
What could go wrong?
Well, I assume here, of course, that exchange traded funds (ETF’s) tracking the S&P 500 can be bought and sold with the same tactics, as outlined here.
Beyond that, I don’t have access to the data currently (although I will soon), but I suspect high frequency trading (HFT) may stand in the way of realizing this marvelous investing strategy.
So remember you have to trade some small instant before market closing to implement this trading strategy. But that means you get into the turf of the high frequency traders. And, as previous posts here observe, all kinds of unusual things can happen in a blink of an eye, faster than any human response time.
So – a conjecture. I think that the choicest situations from the standpoint of this more or less macro interday perspective, may be precisely the places where you see huge spikes in the volume of HFT. This is a proposition that can be tested.
I also think something like this has to be appealed to in order to save the efficient markets hypothesis, or rational expectations. But in this case, it is not the rational expectations of human subjects, but the presumed rationality of algorithms and robots, as it were, which may be driving the market, when push comes to shove.
Top picture from CommSmart Global.