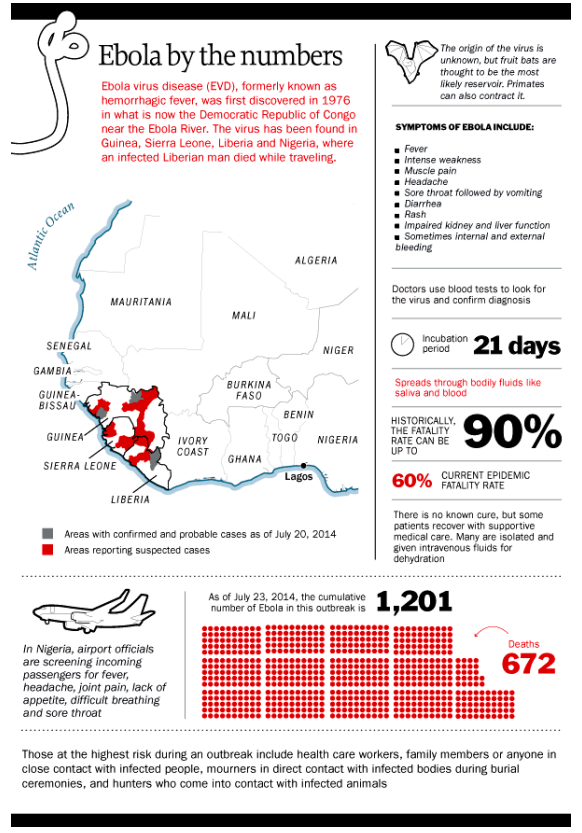
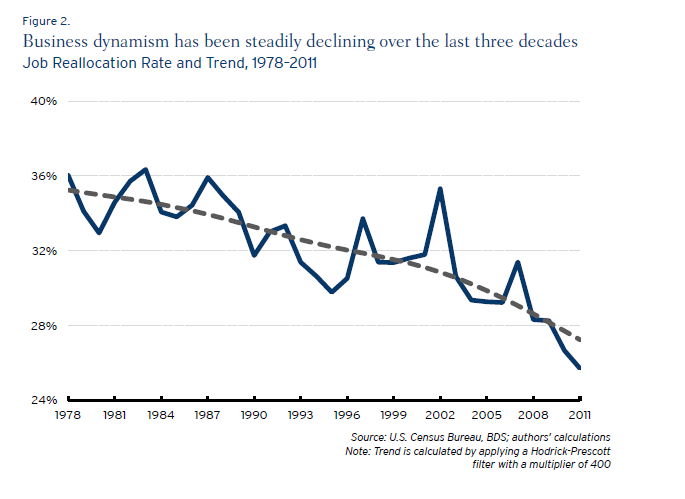
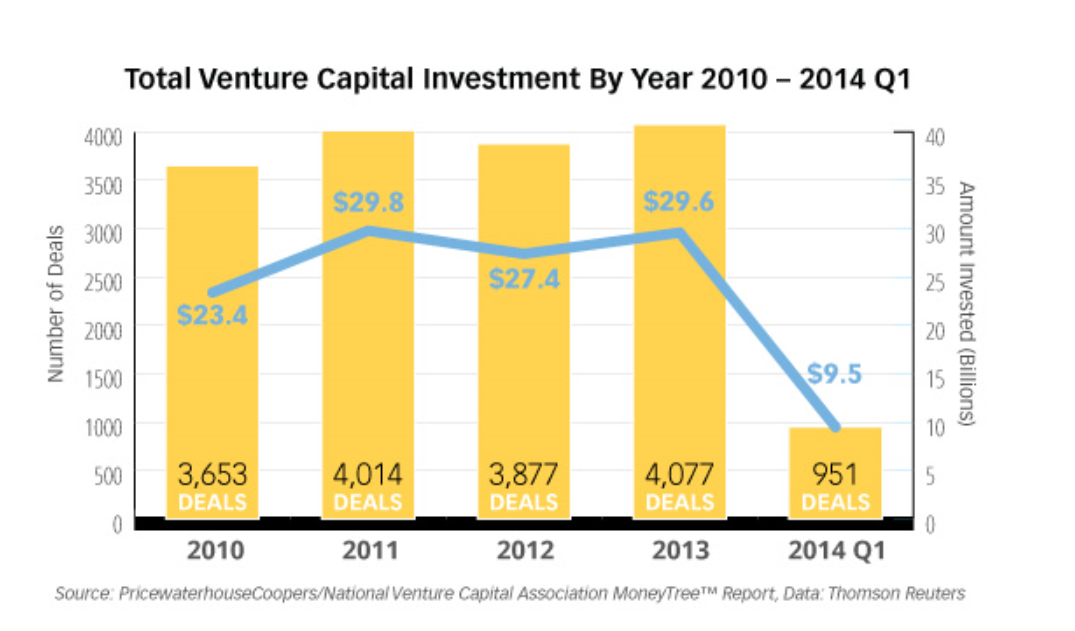
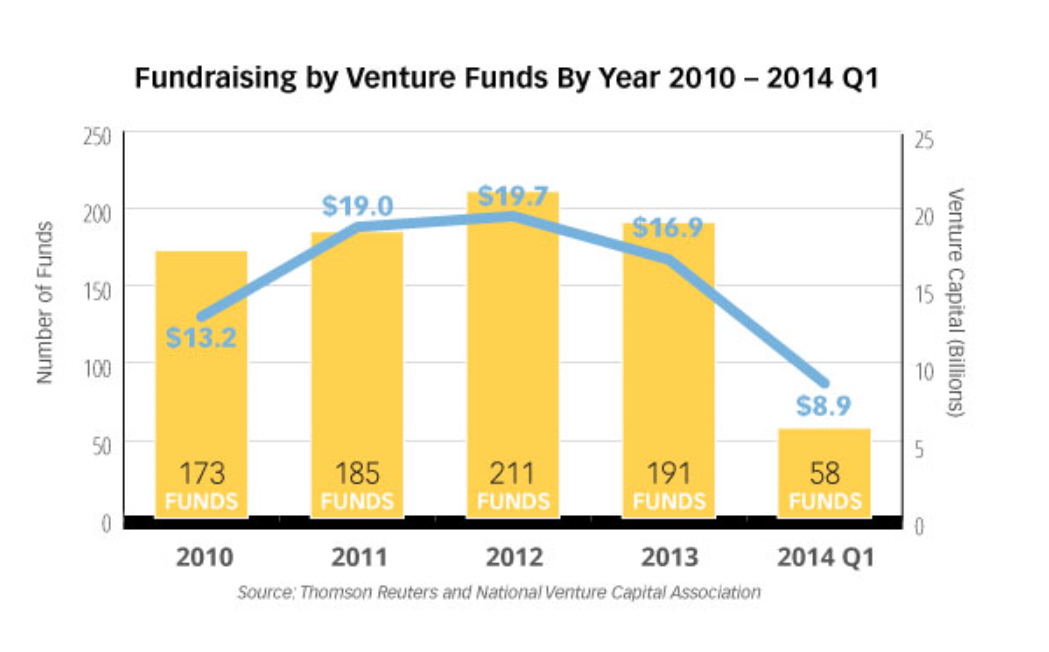
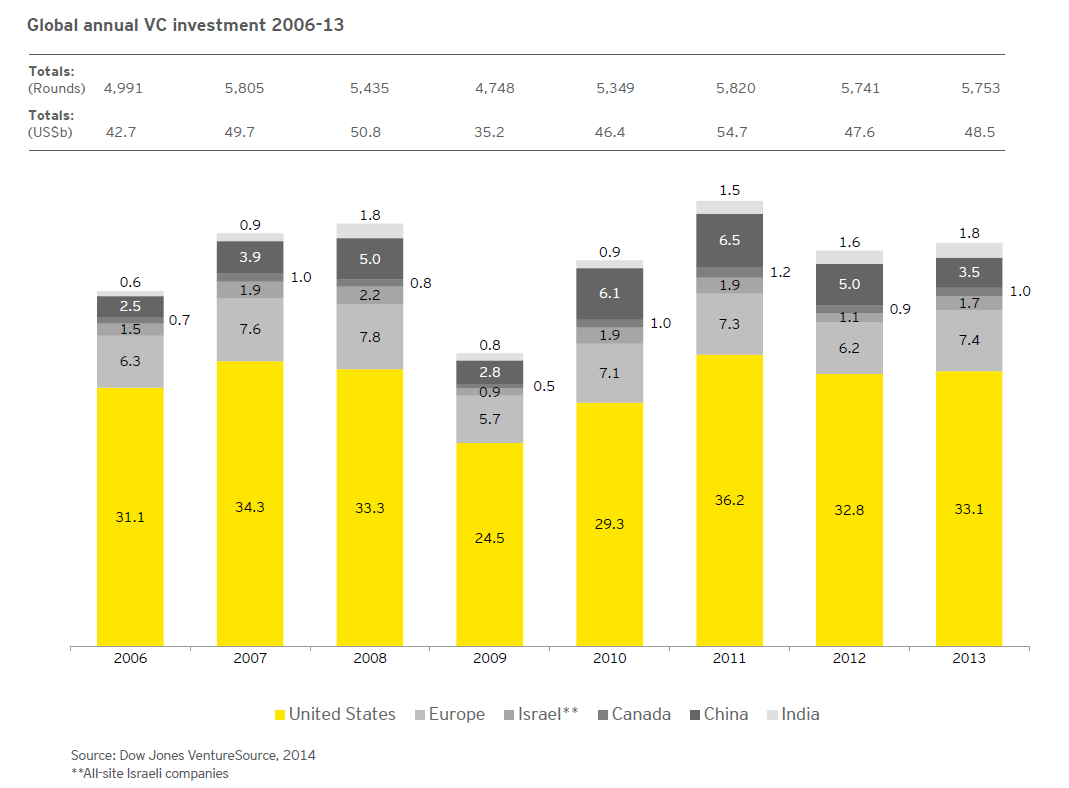
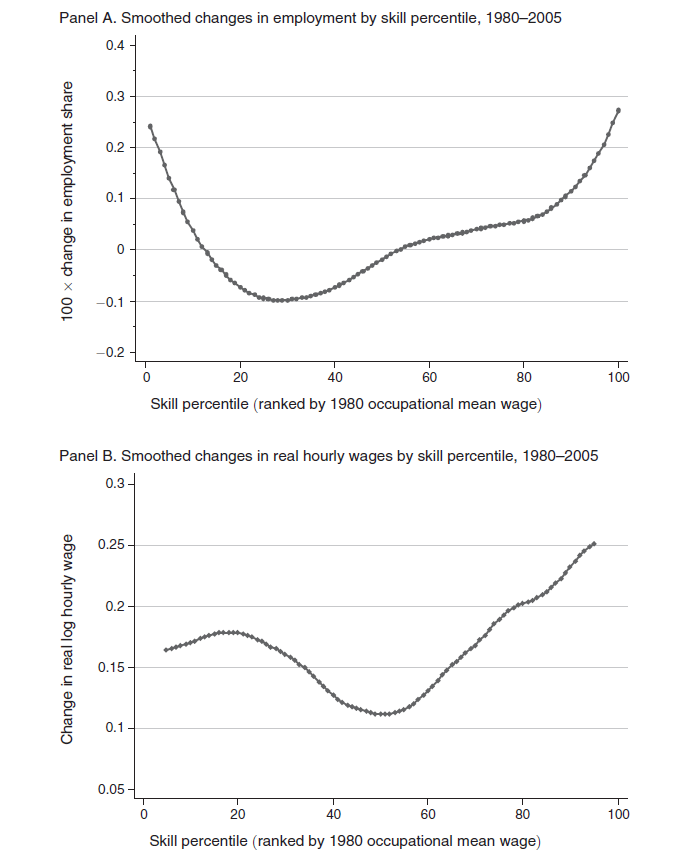
A duo of researchers from Oxford University (Frey and Osborne) made a splash with their analysis of employment and computerization in the US (English spelling). Their research, released September of last year, projects that –
47 percent of total US employment is in the high risk category, meaning that associated occupations are potentially automatable over some unspecified number of years, perhaps a decade or two..
Based on US Bureau of Labor Statistics (BLS) classifications from O*NET Online, their model predicts that most workers in transportation and logistics occupations, together with the bulk of office and administrative support workers, and labour in production occupations, are at risk.
This research deserves attention, if for no other reason than masterful discussions of the impact of technology on employment and many specific examples of new areas for computerization and automation.
For example, I did not know,
Oncologists at Memorial Sloan-Kettering Cancer Center are, for example, using IBM’s Watson computer to provide chronic care and cancer treatment diagnostics. Knowledge from 600,000 medical evidence reports, 1.5 million patient records and clinical trials, and two million pages of text from medical journals, are used for benchmarking and pattern recognition purposes. This allows the computer to compare each patient’s individual symptoms, genetics, family and medication history, etc., to diagnose and develop a treatment plan with the highest probability of success..
There are also specifics of computerized condition monitoring and novelty detection -substituting for closed-circuit TV operators, workers examining equipment defects, and clinical staff in intensive care units.
A followup Atlantic Monthly article – What Jobs Will the Robots Take? – writes,
We might be on the edge of a breakthrough moment in robotics and artificial intelligence. Although the past 30 years have hollowed out the middle, high- and low-skill jobs have actually increased, as if protected from the invading armies of robots by their own moats. Higher-skill workers have been protected by a kind of social-intelligence moat. Computers are historically good at executing routines, but they’re bad at finding patterns, communicating with people, and making decisions, which is what managers are paid to do. This is why some people think managers are, for the moment, one of the largest categories immune to the rushing wave of AI.
Meanwhile, lower-skill workers have been protected by the Moravec moat. Hans Moravec was a futurist who pointed out that machine technology mimicked a savant infant: Machines could do long math equations instantly and beat anybody in chess, but they can’t answer a simple question or walk up a flight of stairs. As a result, menial work done by people without much education (like home health care workers, or fast-food attendants) have been spared, too.
What Frey and Osborne at Oxford suggest is an inflection point, where machine learning (ML) and what they call mobile robotics (MR) have advanced to the point where new areas for applications will open up – including a lot of menial, service tasks that were not sufficiently routinized for the first wave.
In addition, artificial intelligence (AI) and Big Data algorithms are prying open up areas formerly dominated by intellectual workers.
The Atlantic Monthly article cited above has an interesting graphic –
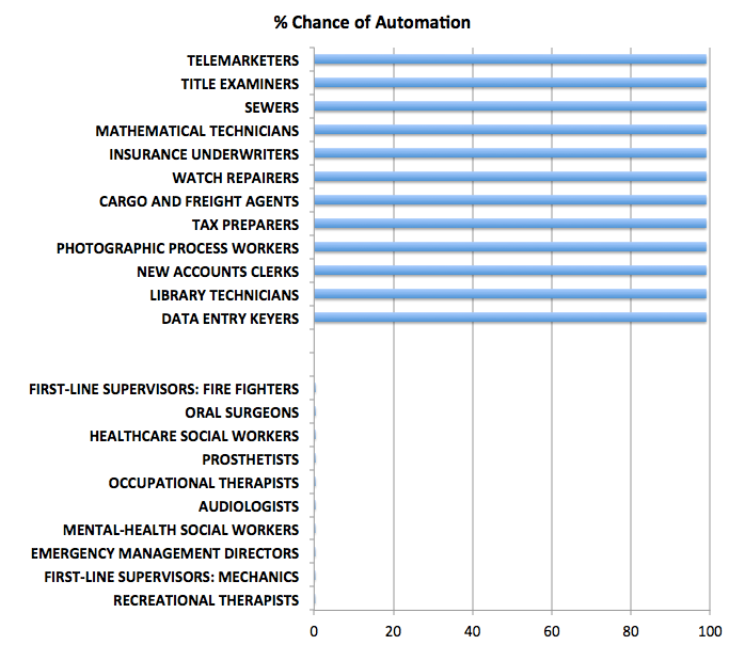 So at the top of this chart are the jobs which are at 100 percent risk of being automated, while at the bottom are jobs which probably will never be automated (although I do think counseling can be done to a certain degree by AI applications).
So at the top of this chart are the jobs which are at 100 percent risk of being automated, while at the bottom are jobs which probably will never be automated (although I do think counseling can be done to a certain degree by AI applications).
The Final Frontier
This blog focuses on many of the relevant techniques in machine learning – basically unsupervised learning of patterns – which in the future will change everything.
Driverless cars are the wow example, of course.
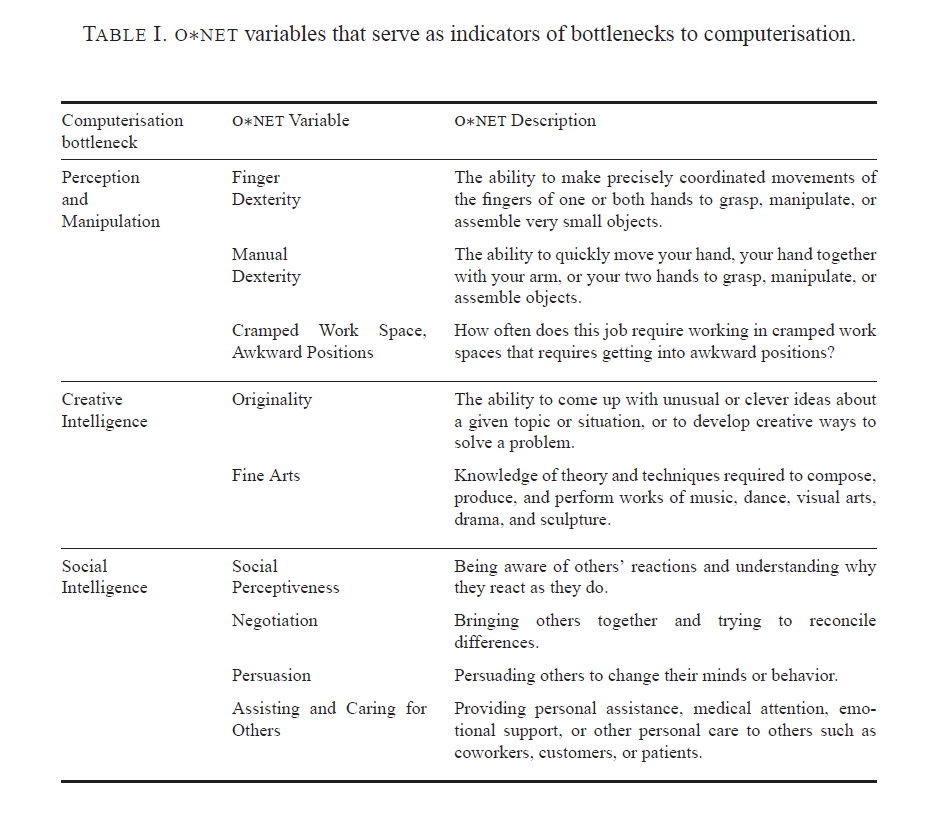
Bottlenecks to moving further up the curve of computerization are highlighted in the following table from the Oxford U report.
As far as dexterity and flexibility goes, Baxter shows great promise, as the following YouTube from his innovators illustrates.
There also are some wonderful examples of apparent creativity by computers or automatic systems, which I plan to detail in a future post.
Frey and Osborn, reflecting on their research in a 2014 discussion, conclude
So, if a computer can drive better than you, respond to requests as well as you and track down information better than you, what tasks will be left for labour? Our research suggests that human social intelligence and creativity are the domains were labour will still have a comparative advantage. Not least, because these are domains where computers complement our abilities rather than substitute for them. This is because creativity and social intelligence is embedded in human values, meaning that computers would not only have to become better, but also increasingly human, to substitute for labour performing such work.
Our findings thus imply that as technology races ahead, low-skill workers will need to reallocate to tasks that are non-susceptible to computerisation – i.e., tasks requiring creative and social intelligence. For workers to win the race, however, they will have to acquire creative and social skills. Development strategies thus ought to leverage the complementarity between computer capital and creativity by helping workers transition into new work, involving working with computers and creative and social ways.
Specifically, we recommend investing in transferable computer-related skills that are not particular to specific businesses or industries. Examples of such skills are computer programming and statistical modeling. These skills are used in a wide range of industries and occupations, spanning from the financial sector, to business services and ICT.
Implications For Business Forecasting
People specializing in forecasting for enterprise level business have some responsibility to “get ahead of the curve” – conceptually, at least.
Not everybody feels comfortable doing this, I realize.
However, I’m coming to the realization that these discussions of how many jobs are susceptible to “automation” or whatever you want to call it (not to mention jobs at risk for “offshoring”) – these discussions are really kind of the canary in the coal mine.
Something is definitely going on here.
But what are the metrics? Can you backdate the analysis Frey and Osborne offer, for example, to account for the coupling of productivity growth and slower employment gains since the last recession?
Getting a handle on this dynamic in the US, Europe, and even China has huge implications for marketing, and, indeed, social control.