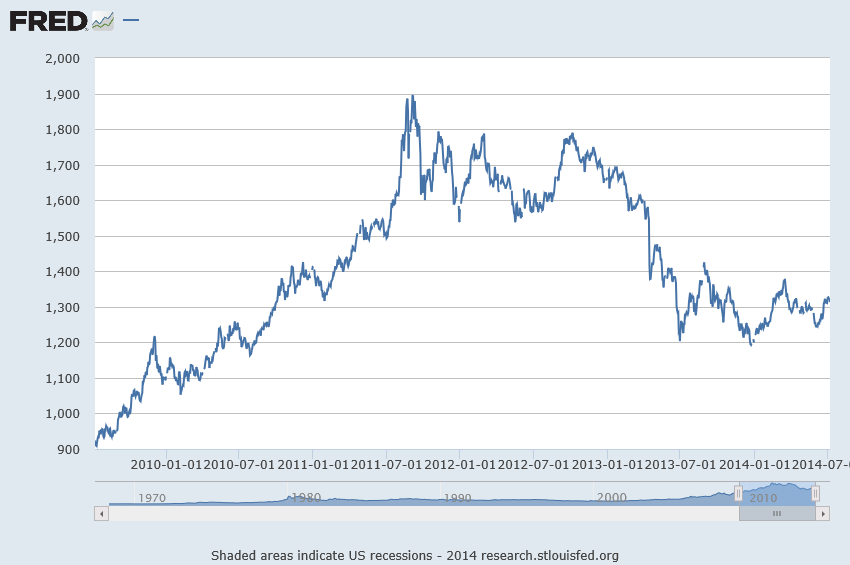
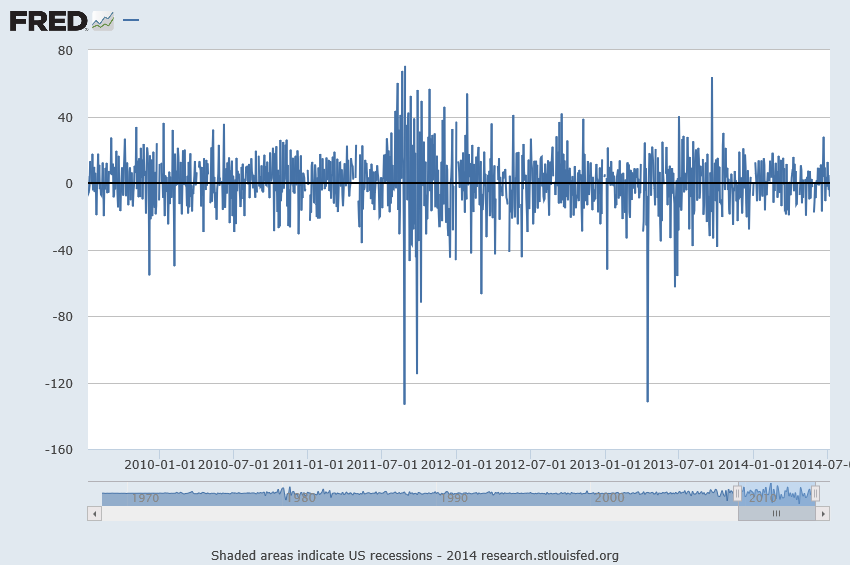
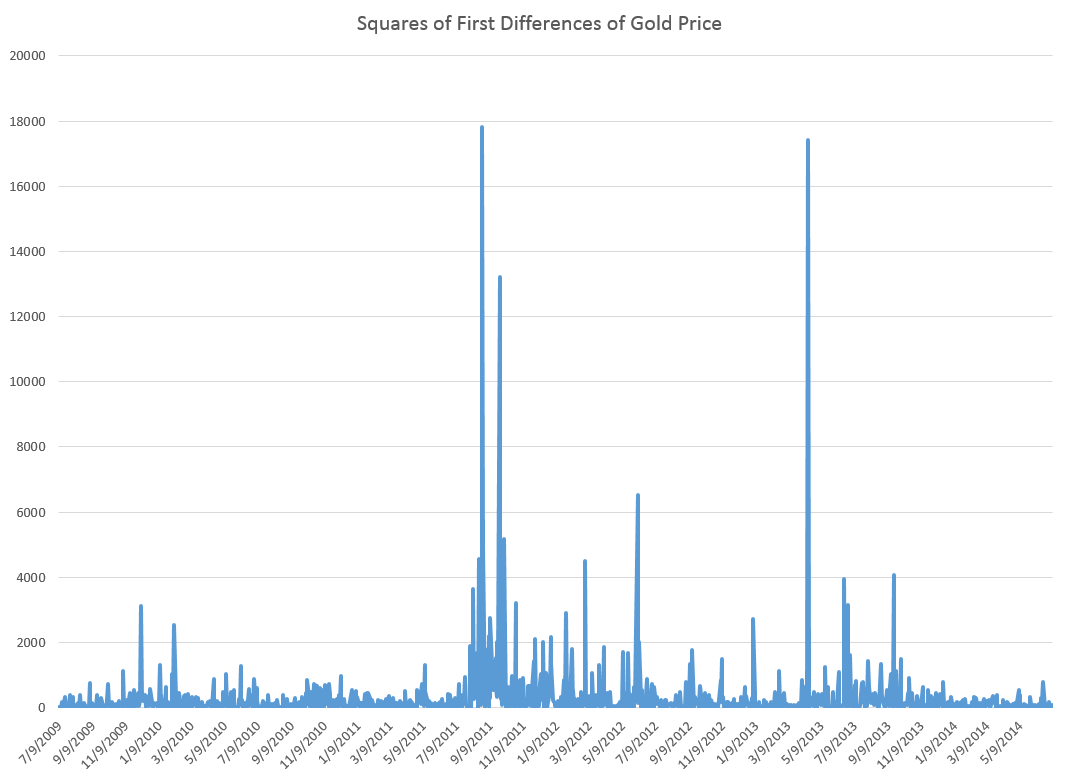
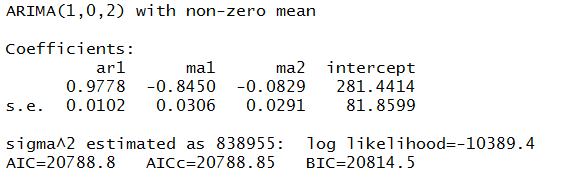
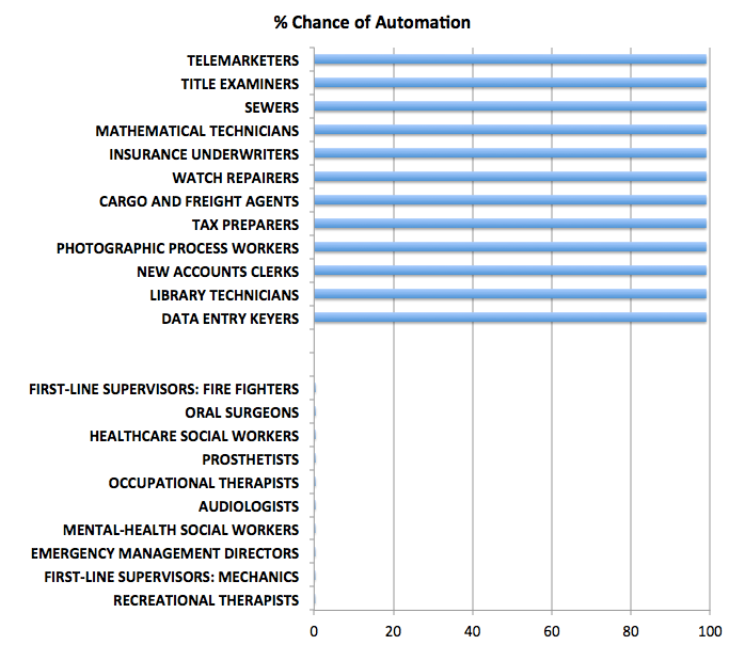
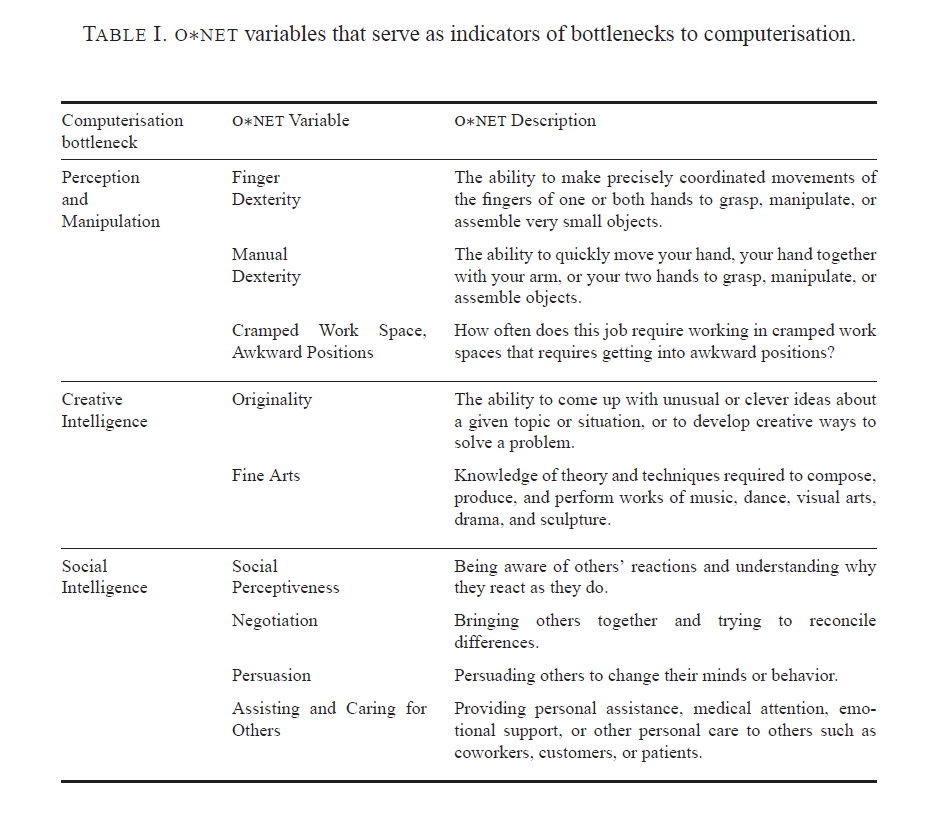
Here is a list of the URL’s for all the YouTube and other videos shown on this blog from January 2014 through May of this year. I encourage you to shop this list, clicking on the links. There’s a lot of good stuff, including several instructional videos on machine learning and other technical topics, a series on robotics, and several videos on climate and climate change.
January 2014
The Polar Vortex Explained in Two Minutes
https://www.youtube.com/watch?v=5eDTzV6a9F4
NASA – Six Decades of a Warming Earth
https://www.youtube.com/watch?v=gaJJtS_WDmI
“CHASING ICE” captures largest video calving of glacier
https://www.youtube.com/watch?v=hC3VTgIPoGU
Machine Learning and Econometrics
https://www.youtube.com/watch?v=EraG-2p9VuE
Can Crime Prediction Software Stop Criminals?
https://www.youtube.com/watch?v=s1-pbJKA3H8
Analytics 2013 – Day 1
https://www.youtube.com/watch?v=LsyOLBroVx4
The birth of a salesman
https://www.youtube.com/watch?v=pWM1dR_V7uw
Economies Improve
https://www.youtube.com/watch?v=5_DeCMIig_M
Kaggle – Energy Applications for Machine Learning
https://www.youtube.com/watch?v=mZZFXTUz-nI
2014 Outlook with Jan Hatzius
https://www.youtube.com/watch?v=Ggv0oC8L3Tk
Nassim Taleb Lectures at the NSF
https://www.youtube.com/watch?v=omsYJBMoIJU
Vernon Smith – Experimental Markets
https://www.youtube.com/watch?v=Uncl-wRfoK8
Forecast Pro – Quick Tour
https://www.youtube.com/watch?v=s8jMp5qS8v4
February 2014
Stephen Wolfram’s Introduction to the Wolfram Language
https://www.youtube.com/watch?v=_P9HqHVPeik
Tornados
https://www.youtube.com/watch?v=TEGhgsiNFJ4
Econometrics – Quantile Regression
https://www.youtube.com/watch?v=P9lMmEkXuBw
Quantile Regression Example
https://www.youtube.com/watch?v=qrriFC_WGj8
Brooklyn Grange – A New York Growing Season
Getting in Shape for the Sport of Data Science
https://www.youtube.com/watch?v=kwt6XEh7U3g
Machine Learning – Decision Trees
https://www.youtube.com/watch?v=-dCtJjlEEgM
Machine Learning – Random Forests
https://www.youtube.com/watch?v=3kYujfDgmNk
Machine Learning – Random Forecasts Applications
https://www.youtube.com/watch?v=zFGPjRPwyFw
Malcolm Gladwell on the 10,000 Hour Rule
https://www.youtube.com/watch?v=XS5EsTc_-2Q
Sornette Talk
https://www.youtube.com/watch?v=Eomb_vbgvpk
Head of India Central Bank Interview
https://www.youtube.com/watch?v=BrVzema7pWE
March 2014
David Stockman
https://www.youtube.com/watch?v=DI718wFmReo
Partial Least Squares Regression
https://www.youtube.com/watch?v=WKEGhyFx0Dg
April 2014
Thomas Piketty on Economic Inequality
https://www.youtube.com/watch?v=qp3AaI5bWPQ
Bonobo builds a fire and tastes marshmellows
https://www.youtube.com/watch?v=GQcN7lHSD5Y
Future Technology
https://www.youtube.com/watch?v=JbQeABIoO6A
May 2014
Ray Kurzweil: The Coming Singularity
https://www.youtube.com/watch?v=1uIzS1uCOcE
Paul Root Wolpe: Kurzweil Critique
https://www.youtube.com/watch?v=qRgMTjTMovc
The Future of Robotics and Artificial Intelligence
https://www.youtube.com/watch?v=AY4ajbu_G3k
Car Factory – KIA Sportage Assembly Line
https://www.youtube.com/watch?v=sjAZGUcjrP8
10 Most Popular Applications for Robots
https://www.youtube.com/watch?v=fH4VwTgfyrQ
Predator Drones
https://www.youtube.com/watch?v=nMh8Cjnzen8
The Future of Robotic Warfare
https://www.youtube.com/watch?v=_atffUtxXtk
Bionic Kangaroo
https://www.youtube.com/watch?v=HUxQM0O7LpQ
Ping Pong Playing Robot
https://www.youtube.com/watch?v=tIIJME8-au8
Baxter, the Industrial Robot
https://www.youtube.com/watch?v=ukehzvP9lqg
Bootstrapping