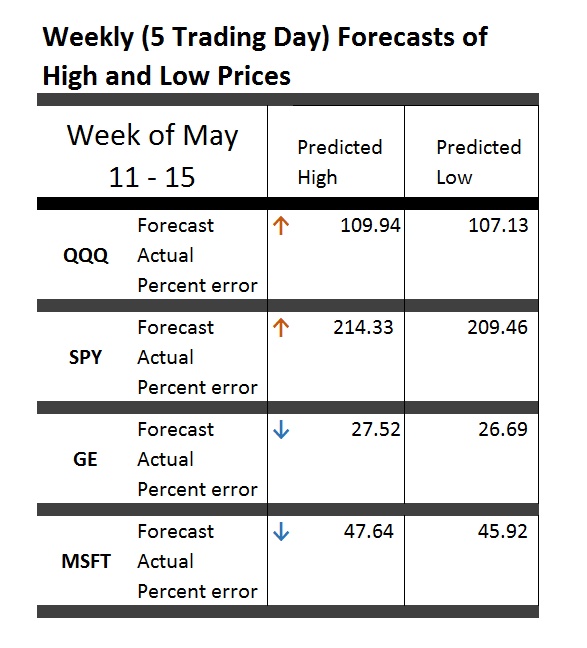
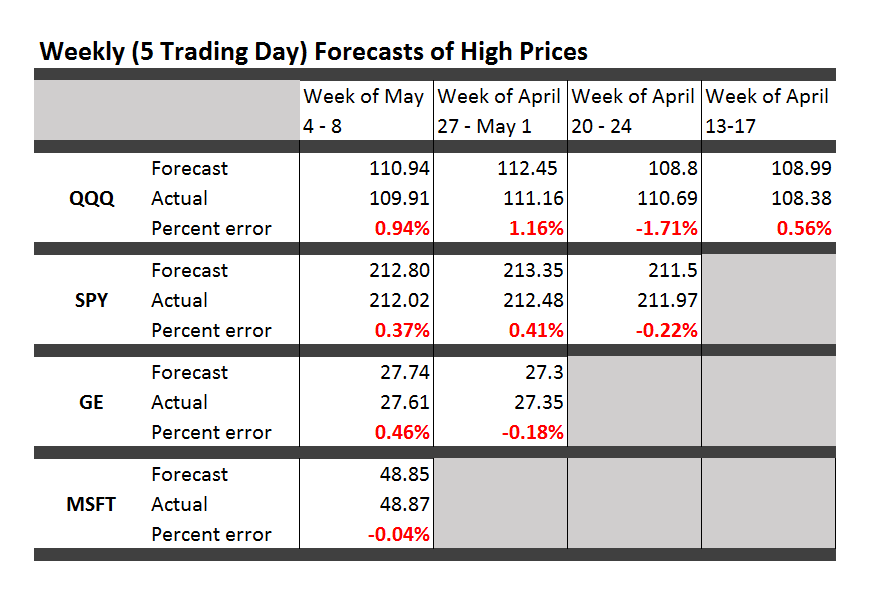
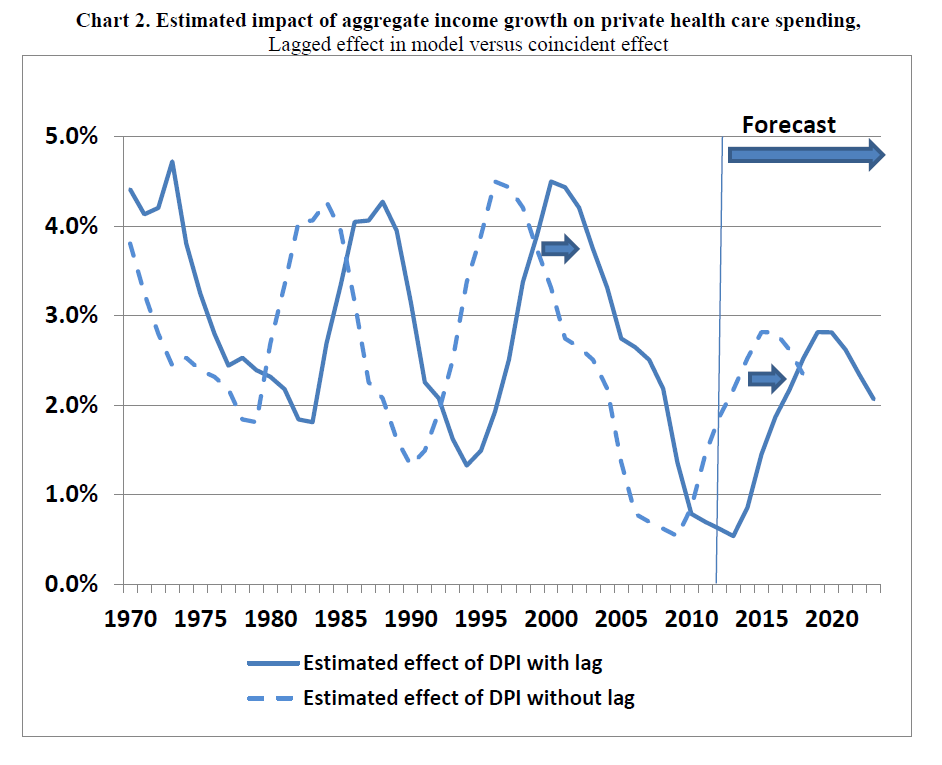
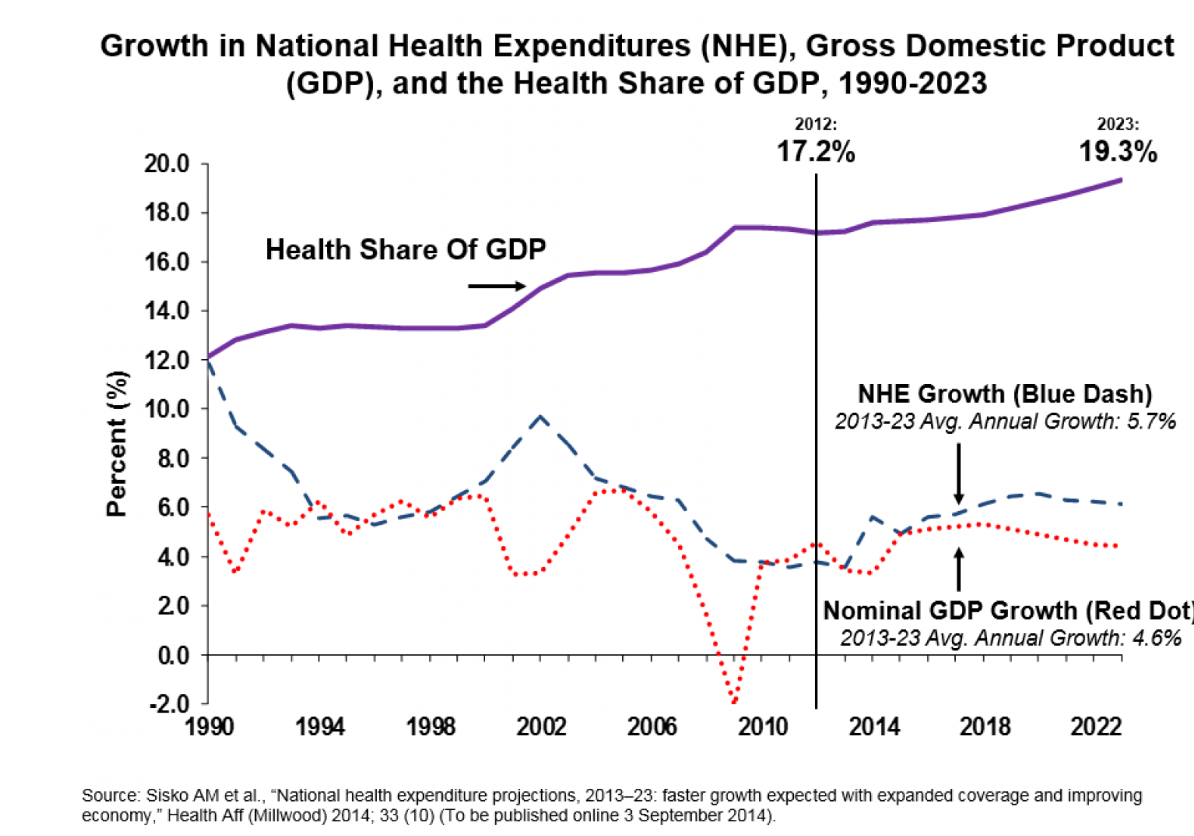
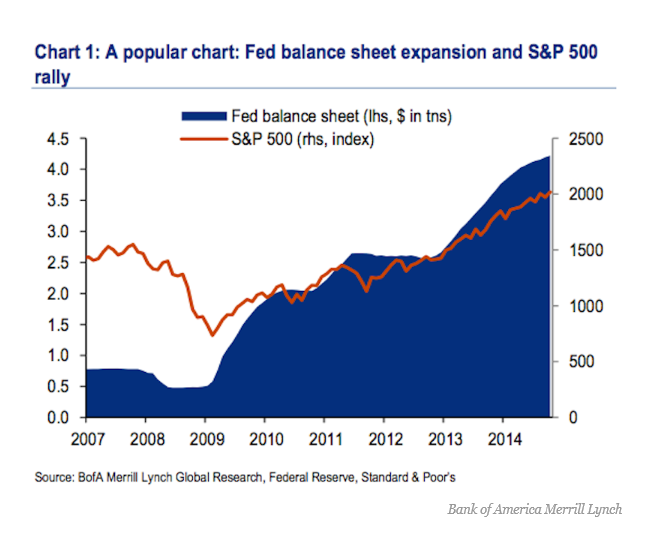
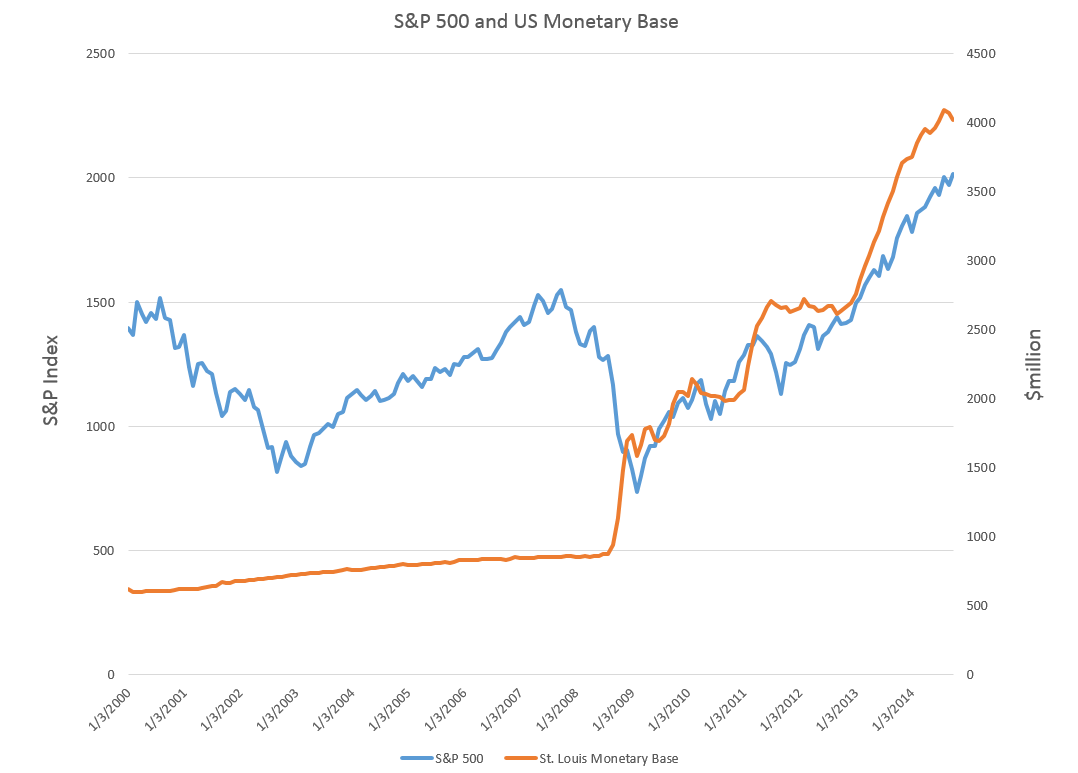
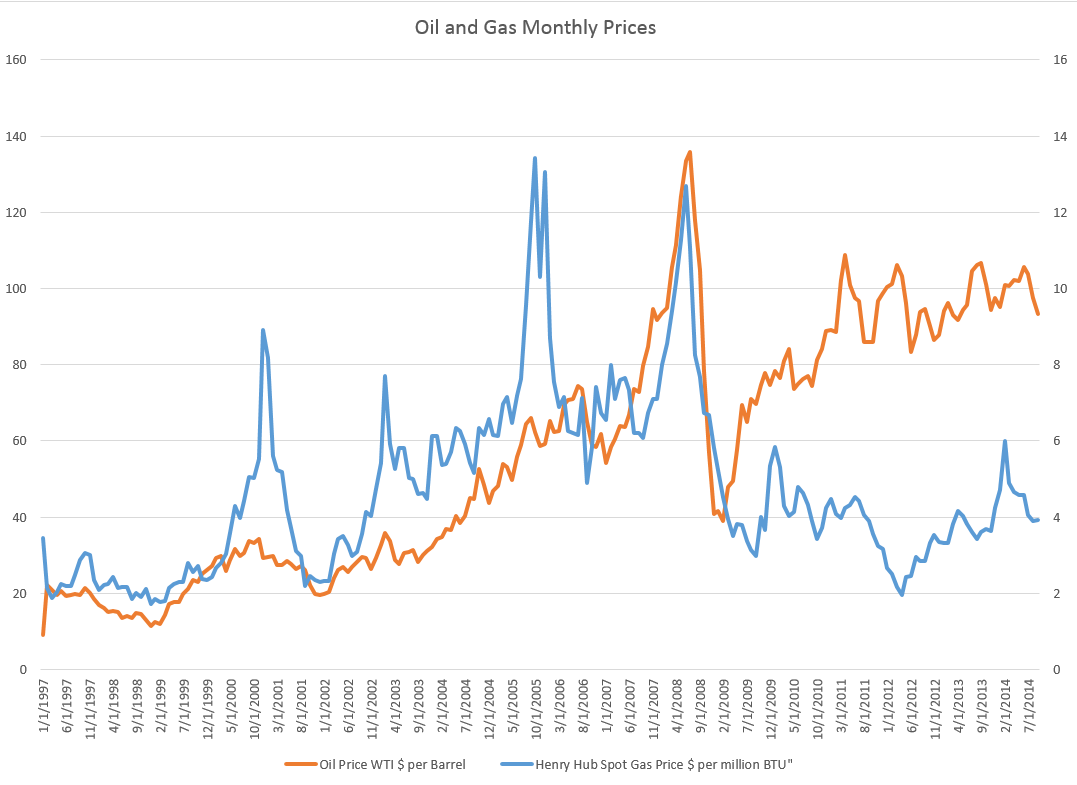
I’ve been studying the April 2014 World Economic Outlook (WEO) of the International Monetary Fund (IMF) with an eye to its longer term projections of GDP.
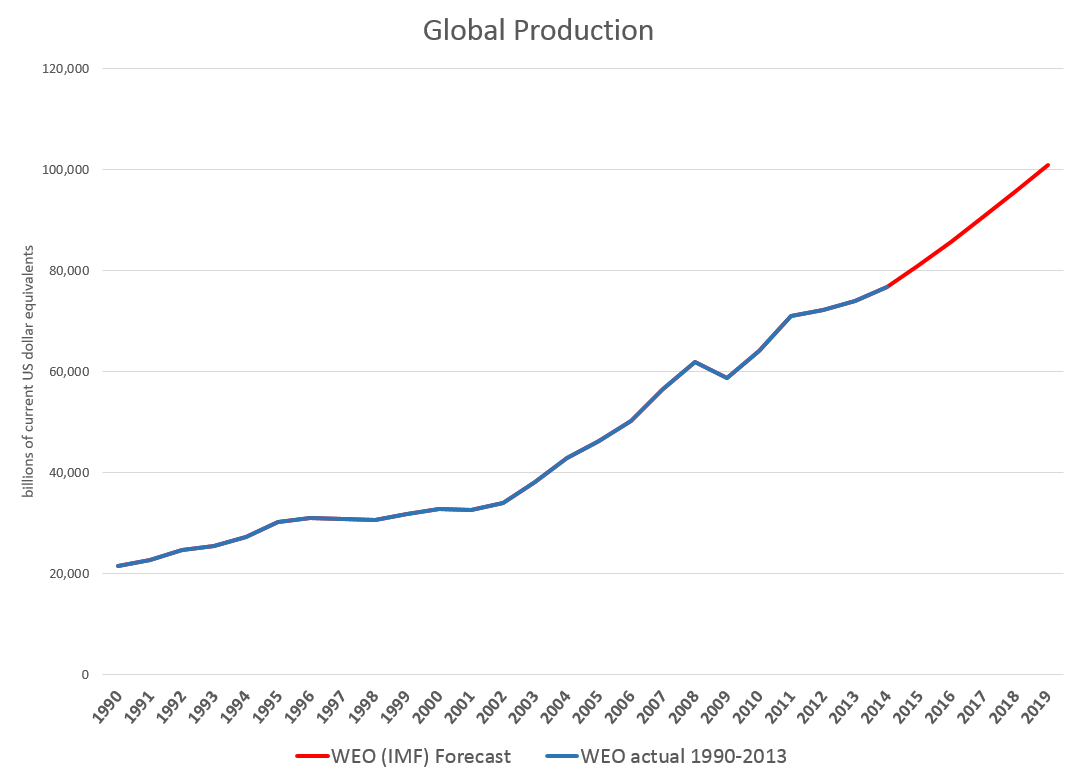
Downloading the WEO database and summing the historic and projected GDP’s suggests this chart.
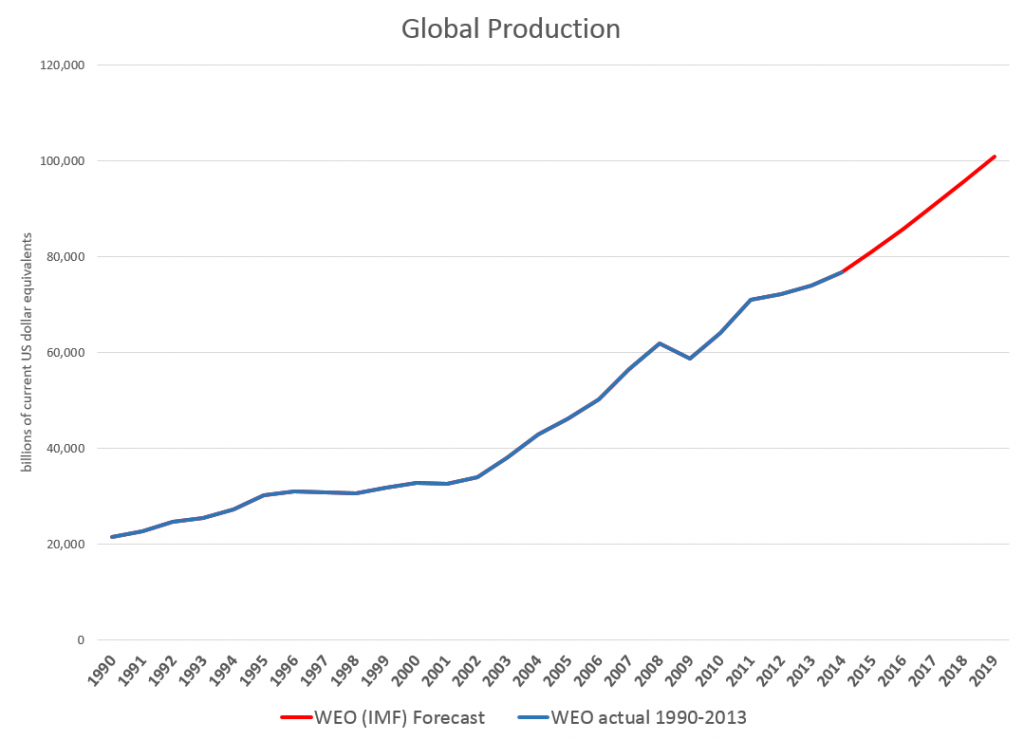
The WEO forecasts go to 2019, almost to our first benchmark date of 2020. Global production is projected to increase from around $76.7 trillion in current US dollar equivalents to just above $100 trillion. An update in July marked the estimated 2014 GDP growth down from 3.7 to 3.4 percent, leaving the 2015 growth estimate at a robust 4 percent.
The WEO database is interesting, because it’s country detail allows development of charts, such as this.
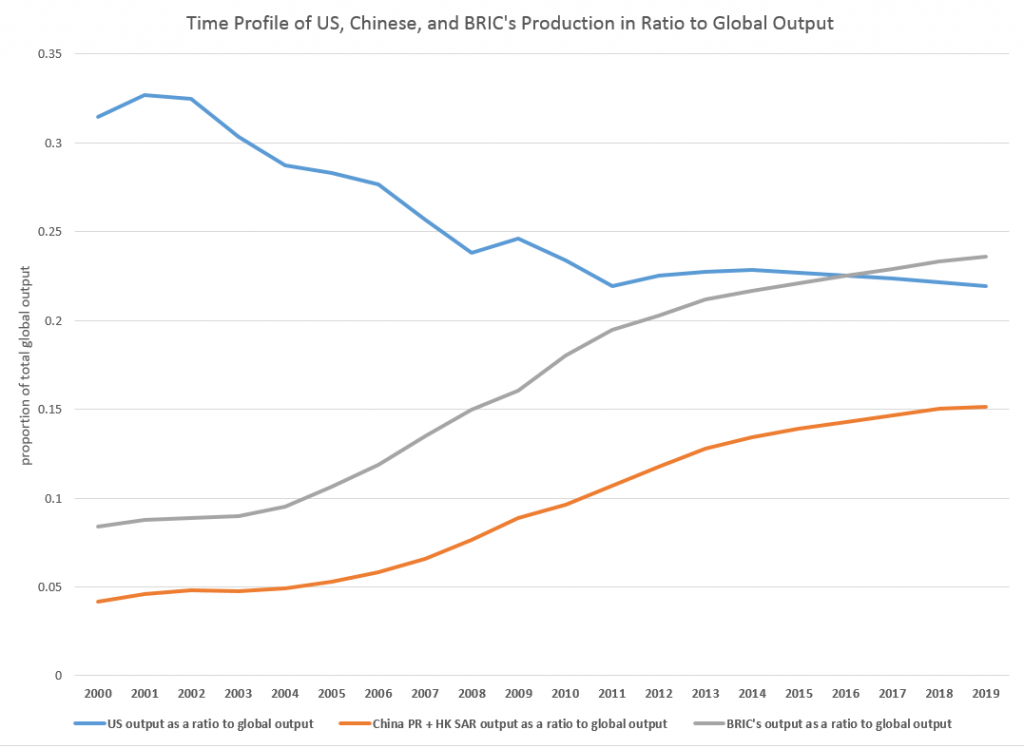
So, based on this country detail on GDP and projections thereof, the BRIC’s (Brazil, Russia, India, and China) will surpass US output, measured in current dollar equivalents, in a couple of years.
In purchasing power parity (PPP) terms, China is currently or will soon pass the US GDP, incidentally. Thus, according to the Big Mac index, a hamburger is 41 percent undervalued in China, compared to the US. So boosting Chinese production 41 percent puts its value greater than US output. However, the global totals would change if you take this approach, and it’s not clear the Chinese proportion would outrank the US yet.
The Impacts of Recession
The method of caging together GDP forecasts to the year 2030, the second benchmark we want to consider in this series of posts, might be based on some type of average GDP growth rate.
However, there is a fundamental issue with this, one I think which may play significantly into the actual numbers we will see in coming years.
Notice, for example, the major “wobble” in the global GDP curve historically around 2008-2009. The Great Recession, in fact, was globally synchronized, although it only caused a slight inflection in Chinese and BRIC growth. Europe and Japan, however, took a major hit, bringing global totals down for those years.
Looking at 2015-2020 and, certainly, 2015-2030, it would be nothing short of miraculous if there were not another globally synchronized recession. Currently, for example, as noted in an earlier post here, the Eurozone, including Germany, moved into zero to negative growth last quarter, and there has been a huge drop in Japanese production. Also, Chinese economic growth is ratcheting down from it atmospheric levels of recent years, facing a massive real estate bubble and debt overhang.
But how to include a potential future recession in economic projections?
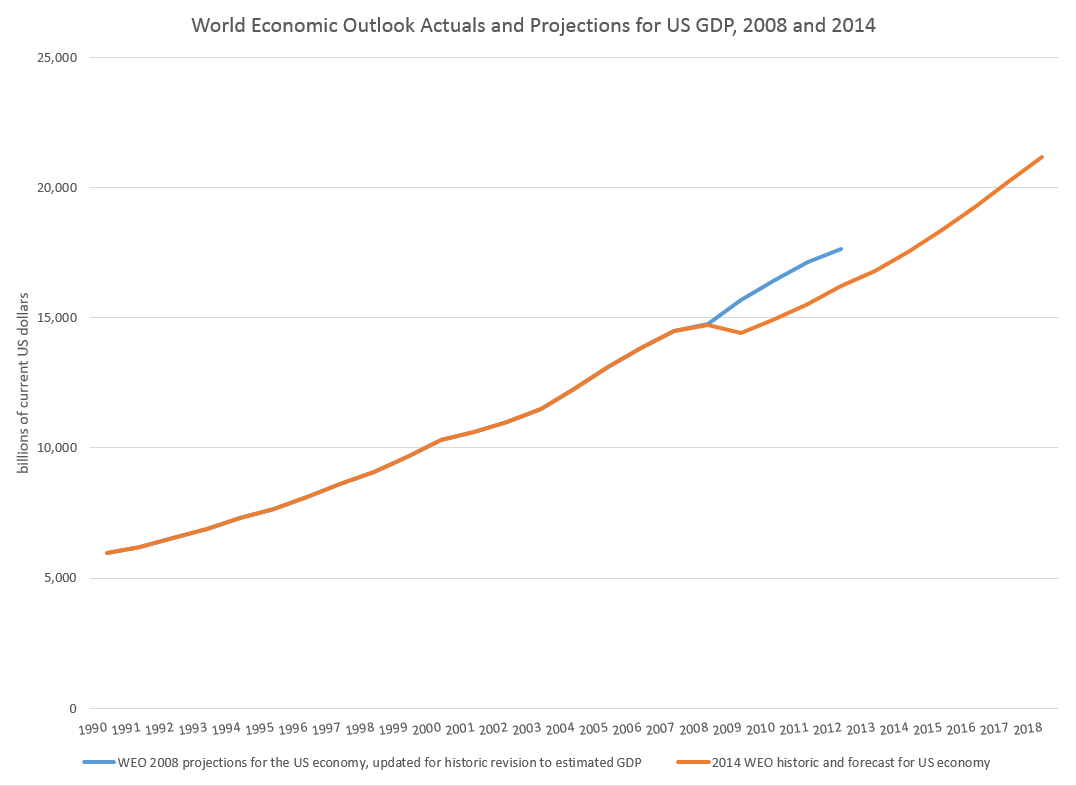
One guide might be to look at how past projections have related to these types of events. Here, for example, is a comparison of the 2008 and 2014 US GDP projections in the WEO’s.
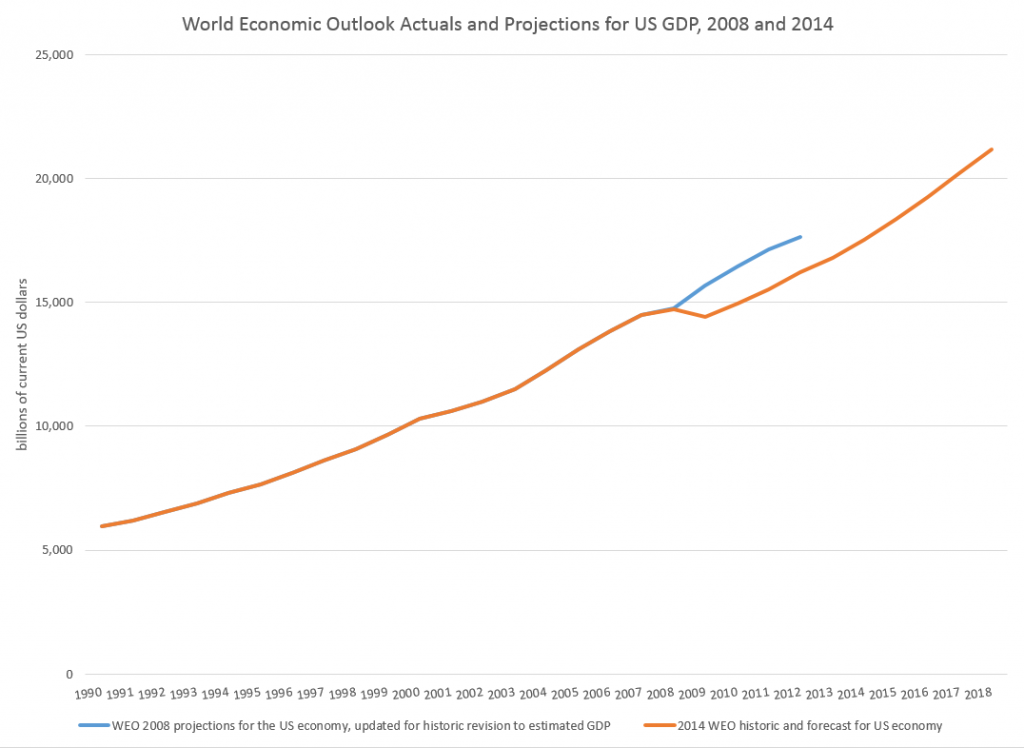
So, according to the IMF, the Great Recession resulted in a continuing loss of US production through until the present.
This corresponds with the concept that, indeed, the GDP time series is, to a large extent, a random walk with drift, as Nelson and Plosser suggested decades ago (triggering a huge controversy over unit roots).
And this chart highlights a meaning for potential GDP. Thus, the capability to produce things did not somehow mysteriously vanish in 2008-2009. Rather, there was no point in throwing up new housing developments in a market that was already massively saturated, Not only that, but the financial sector was unable to perform its usual duties because it was insolvent – holding billions of dollars of apparently worthless collateralized mortgage securities and other financial innovations.
There is a view, however, that over a long period of time some type of mean reversion crops up.
This is exemplified in the 2014 Congressional Budget Office (CBO) projections, as shown in this chart from the underlying detail.
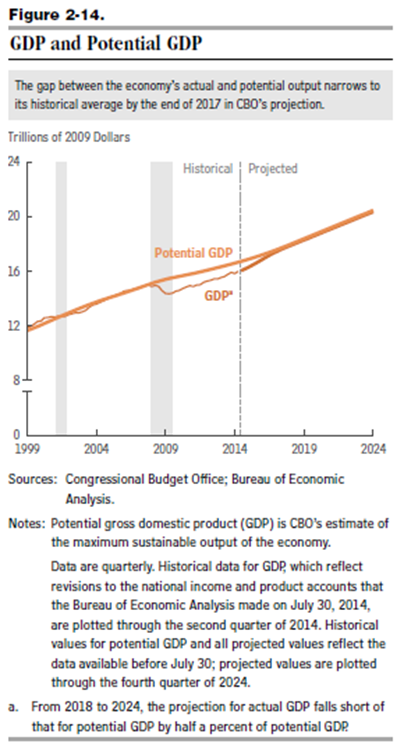
This convergence on potential GDP, which somehow is shown in the diagram with a weaker growth rate just after 2008, is based on the following forecasts of underlying drivers, incidentally.
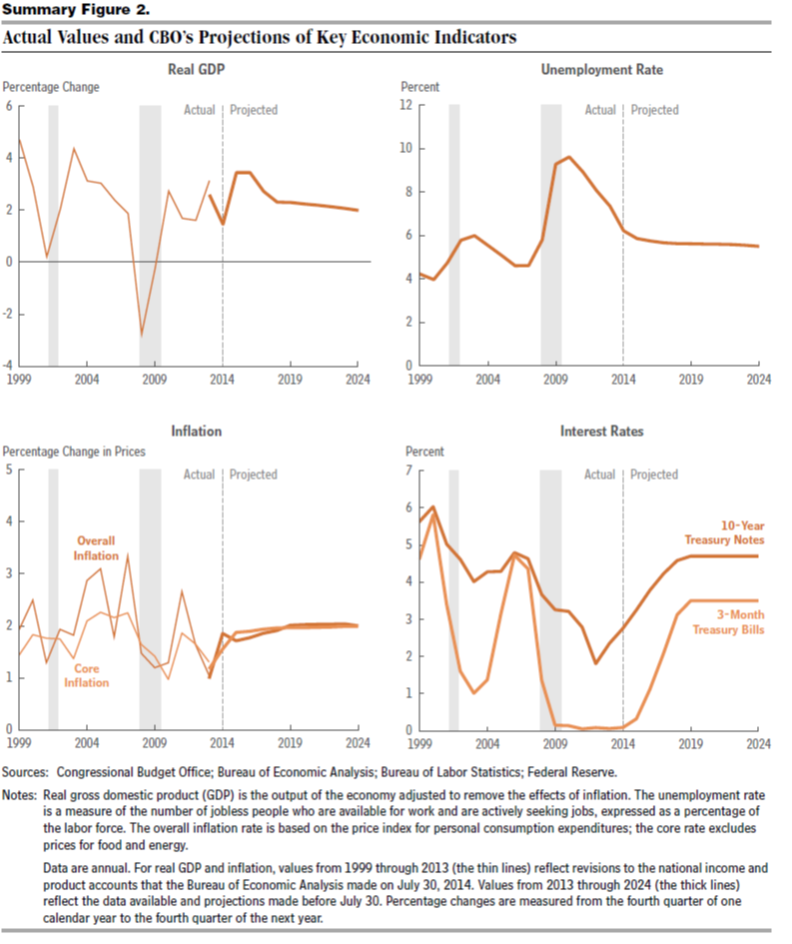
So again, despite the choppy historical detail for US real GDP growth in the chart on the upper left, the forecast adopted by the CBO blithely assumes no recession through 2024 as well as increase in US interest rates back to historic levels by 2019.
I think this clearly suggests the Congressional Budget Office is somewhere in la-la land.
But the underlying question still remains.
How would one incorporate the impacts of an event – a recession – which is probably almost a certainty by the end of these forecast horizons, but whose timing is uncertain?
Of course, there are always scenarios, and I think, particularly for budget discussions, it would be good to display one or two of these.
I’m interested in reader suggestions on this.