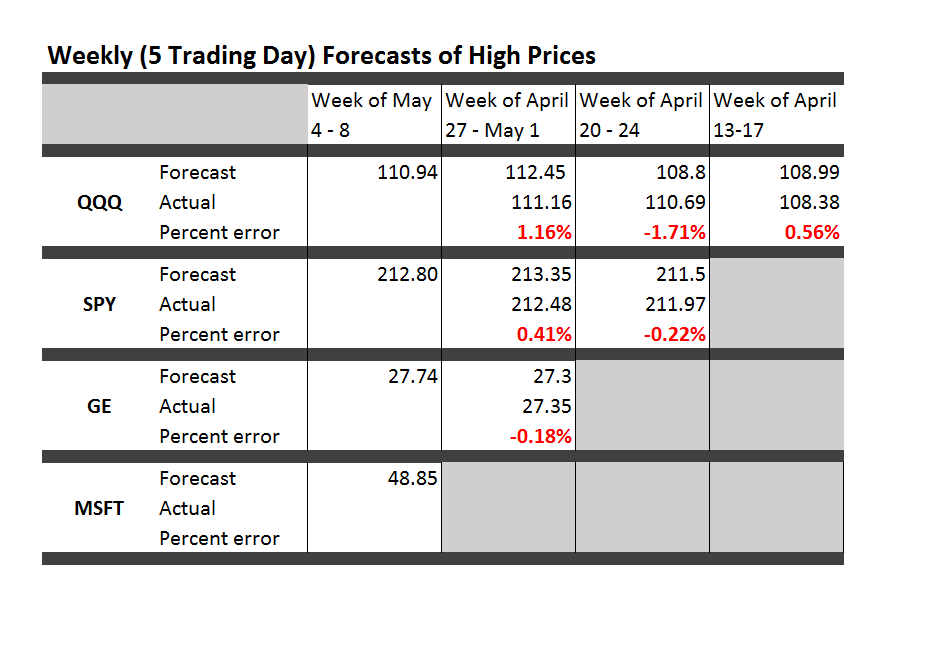
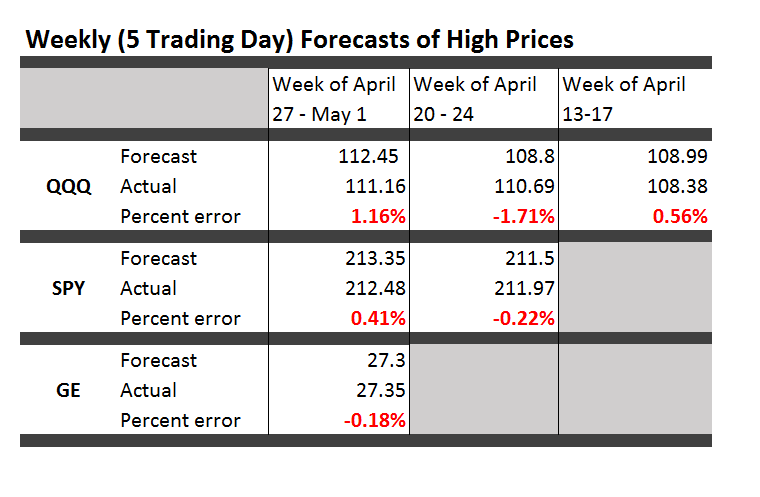
I have been spending a lot of time analyzing stock market forecast algorithms I stumbled on several months ago which I call the New Proximity Algorithms (NPA’s).
There is a white paper on the University of Munich archive called Predictability of the Daily High and Low of the S&P 500 Index. This provides a snapshot of the NPA at one stage of development, and is rock solid in terms of replicability. For example, an analyst replicated my results with Python, and I’ll probably will provide his code here at some point.
I now have moved on to longer forecast periods and more complex models, and today want to discuss month-ahead forecasts of high and low prices of the S&P 500 for this month – June.
Current Month Forecast for S&P 500
For the current month – June 2015 – things look steady with no topping out or crash in sight
With opening price data from June 1, the NPA month-ahead forecast indicates a high of 2144 and a low of 2030. These are slightly above the high and low for May 2015, 2,134.72 and 2,067.93, respectively.
But, of course, a week of data for June already is in, so, strictly speaking, we need a three week forecast, rather than a forecast for a full month ahead, to be sure of things. And, so far, during June, daily high and low prices have approached the predicted values, already.
In the interests of gaining better understanding of the model, however, I am going to “talk this out” without further computations at this moment.
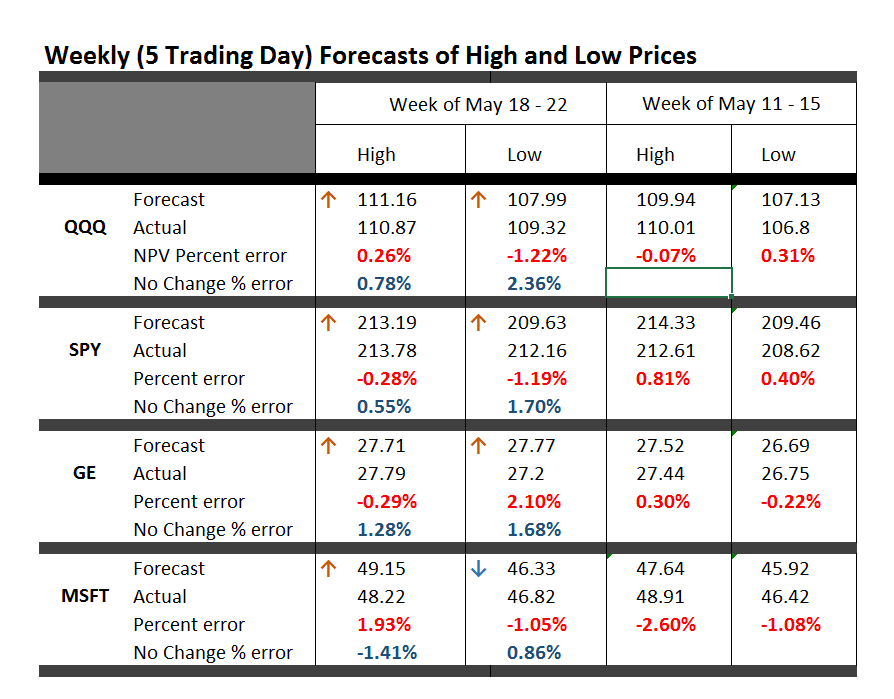
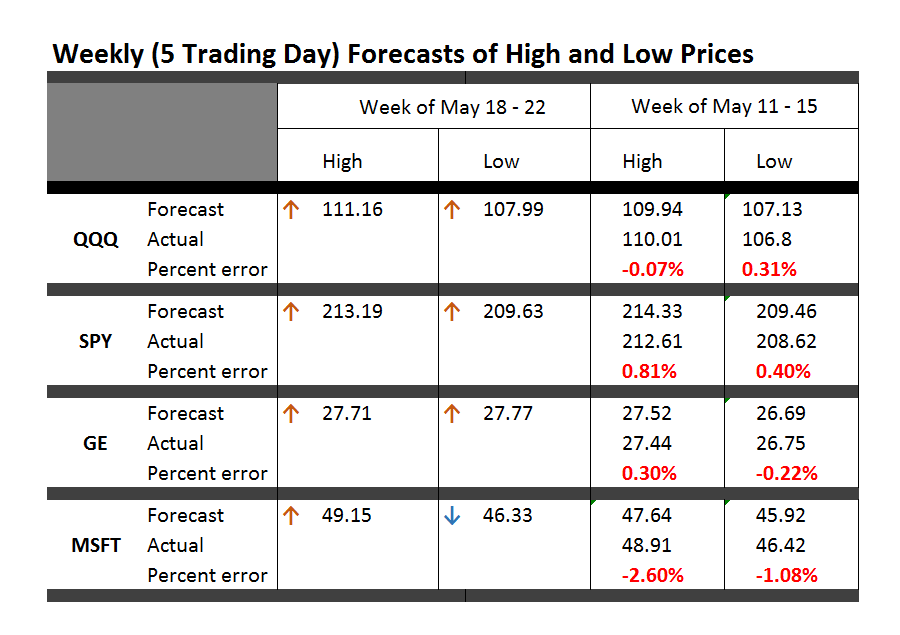
So, one point is that the model for the low is less reliable than the high price forecast on a month-ahead basis. Here, for example, is the track record of the NPA month-ahead forecasts for the past 12 months or so with S&P 500 data.
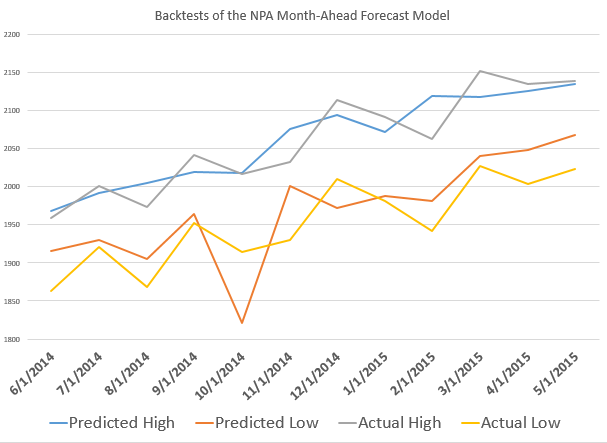
The forecast model for the high tracks along with the actuals within around 1 percent forecast error, plus or minus. The forecast model for the low, however, has a big miss with around 7 percent forecast error in late 2014.
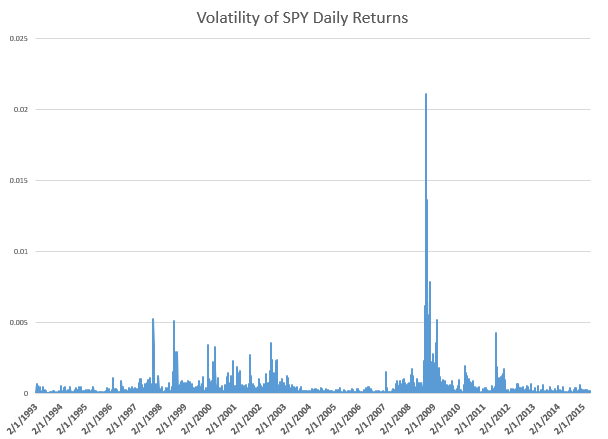
This sort of “wobble” for the NPA forecast of low prices is not unusual, as the following chart, showing backtests to 2003, shows.
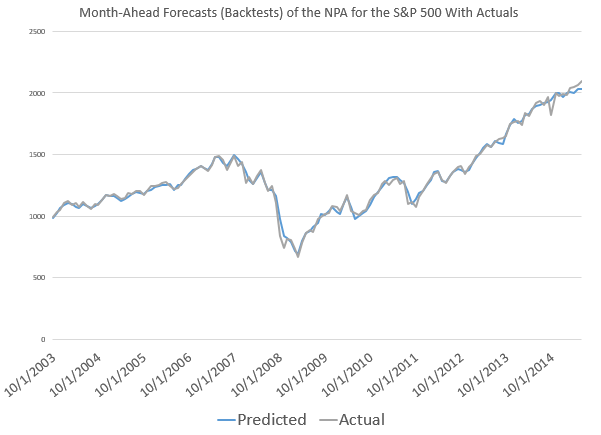
What’s encouraging is the NPA model for the low price adjusts quickly. If large errors signal a new direction in price movement, the model catches that quickly. More often, the wobble in the actual low prices seems to be transitory.
Predicting Turning Points
One reason why the NPA monthly forecast for June might be significant, is that the underlying method does a good job of predicting major turning points.
If a crash were coming in June, it seems likely, based on backtesting, that the model would signal something more than a slight upward trend in both the high and low prices.
Here are some examples.
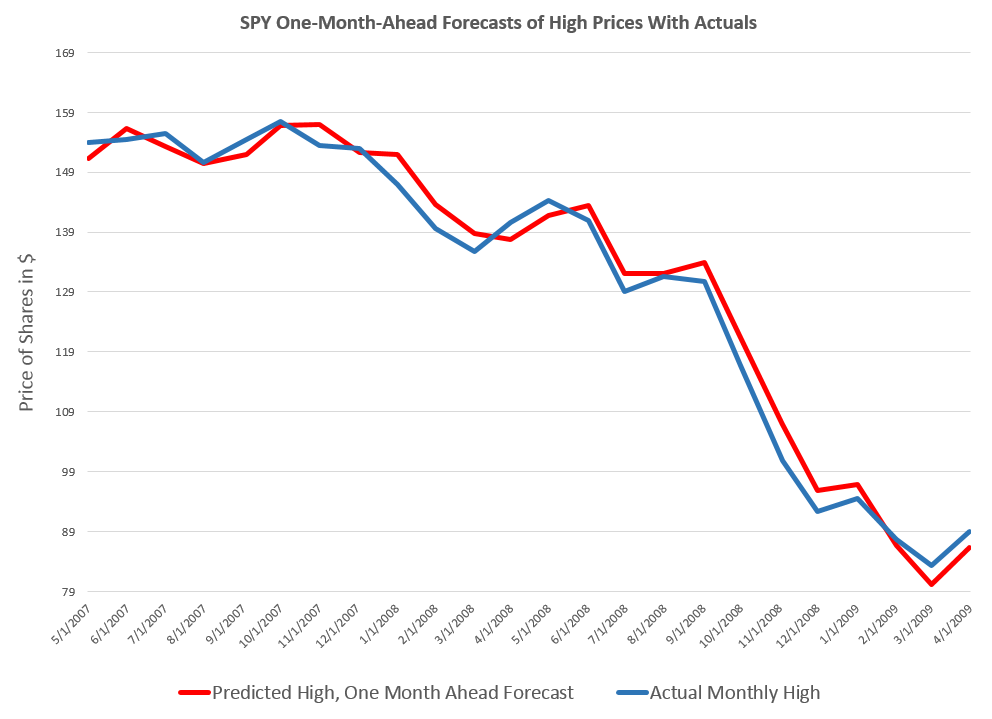
First, the NPA forecast model for the high price of the S&P 500 caught the turning point in 2007 when the market began to go into reverse.
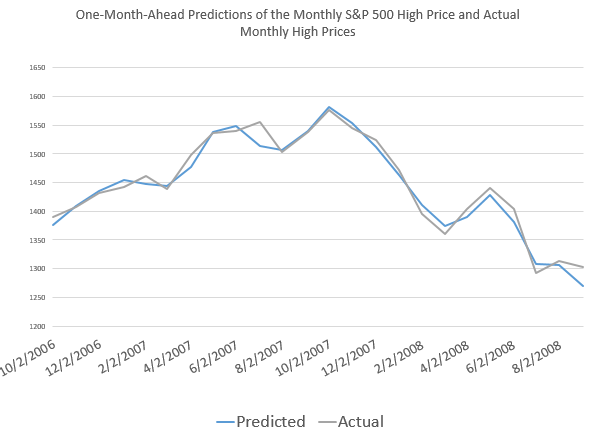
But that is not all.
The NPA model for the month-ahead high price also captures a more recent reversal in the S&P 500.
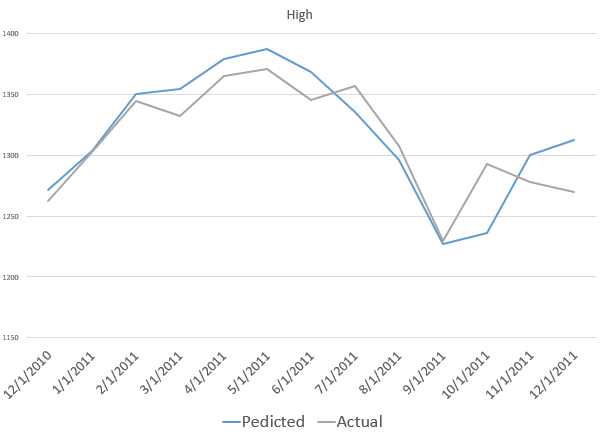
Also, the model for the low did capture the bottom in the S&P 500 in 2009, when the direction of the market changed from decline to increase.
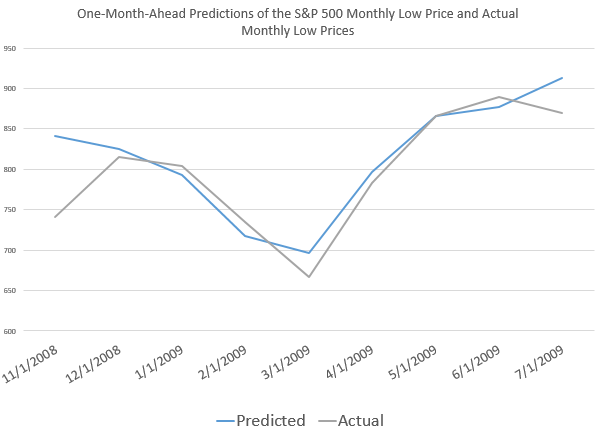
This type of accuracy in timing in forecast modeling is quite remarkable.
It’s something I also saw earlier with the Hong Kong Hang Seng Index, but which seemed at that stage of model development to be confined to Chinese market data.
Now I am confident the NPA forecasts have some capability to predict turning points quite widely across many major indexes, ETF’s, and markets.
Note that all the charts shown above are based on out-of-sample extrapolations of the NPA model. In other words, one set of historical data are used to estimate the parameters of the NPA model, and other data, outside this sample, are then plugged in to get the month-ahead forecasts of the high and low prices.
Where This Is Going
I am compiling materials for presentations relating to the NPA, its capabilities, its forecast accuracy.
The NPA forecasts, as the above exhibits show, work well when markets are going down or turning directions, as when in a steady period of trending growth.
But don’t mistake my focus on these stock market forecasting algorithms for a last minute conversion to the view that nothing but the market is important. In fact, a lot of signals from business and global data suggest we could be in store for some big changes later in 2015 or in 2016.
What I want to do, I think, is understand how stock markets function as sort of prisms for these external developments – perhaps involving Greek withdrawal from the Eurozone, major geopolitical shifts affecting oil prices, and the onset of the crazy political season in the US.