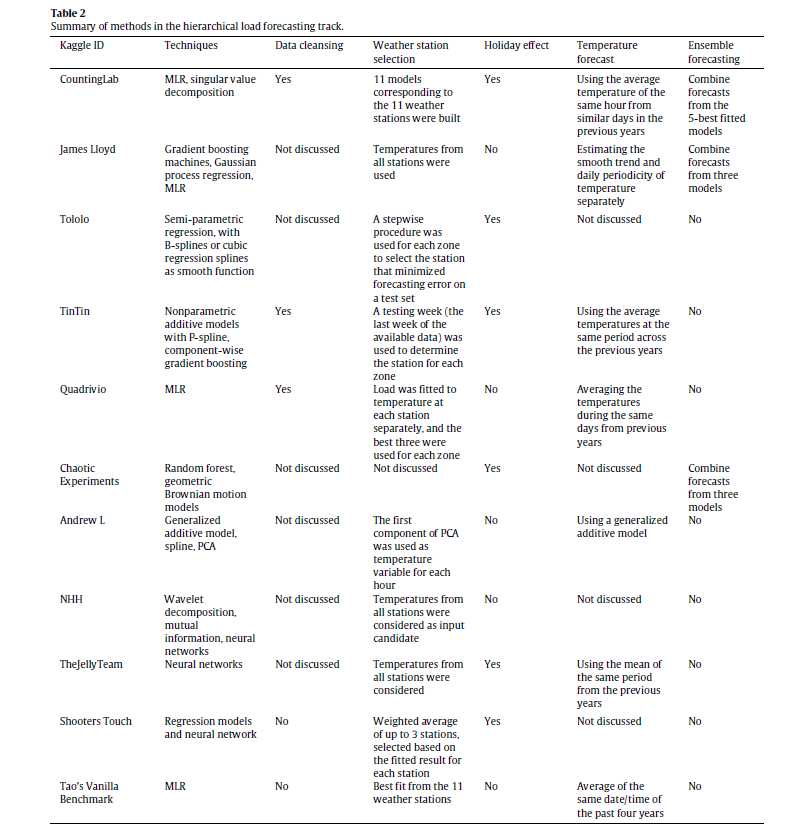
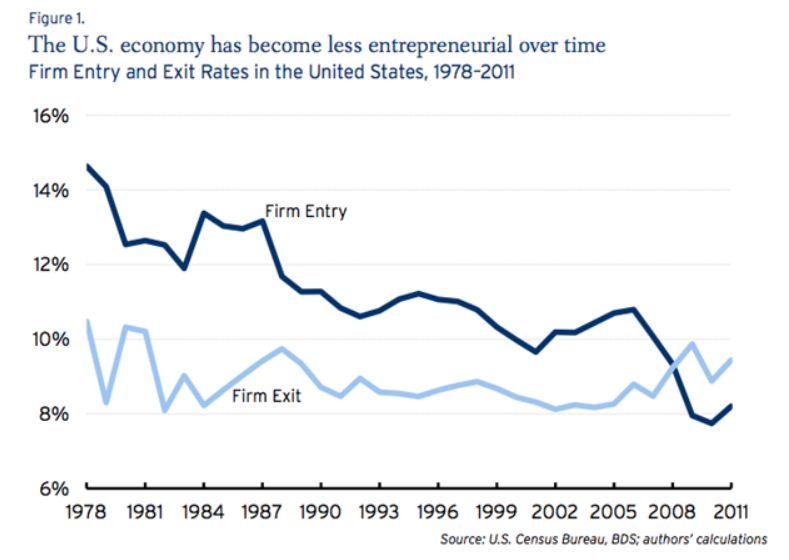
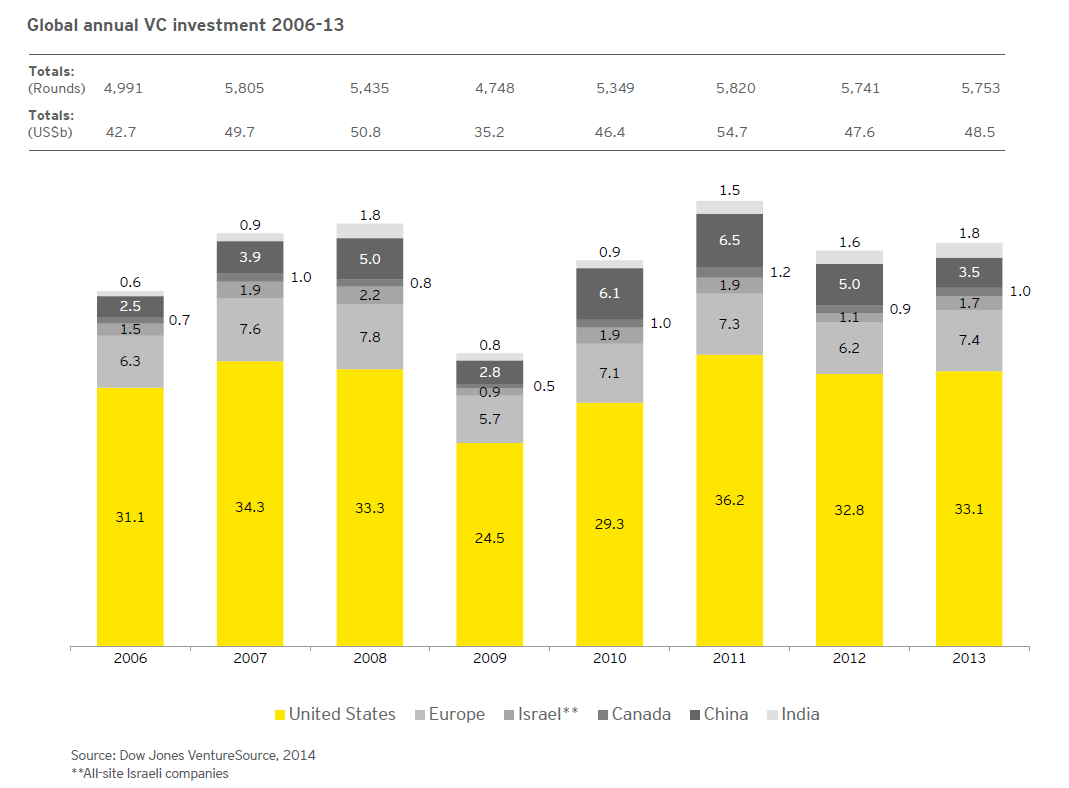
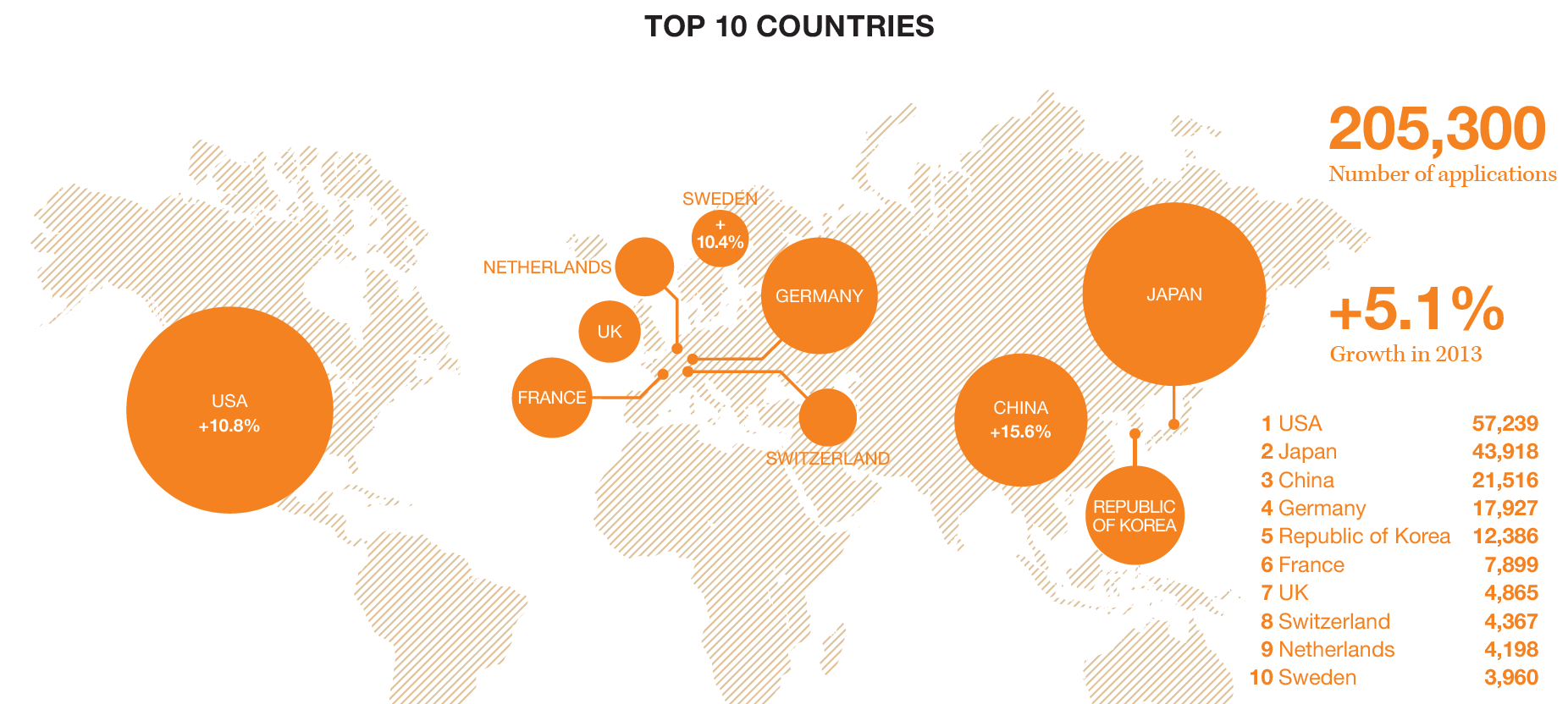
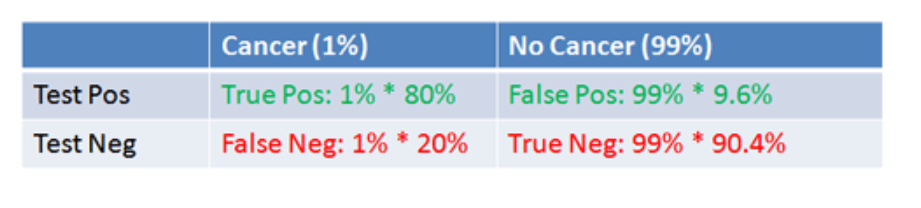
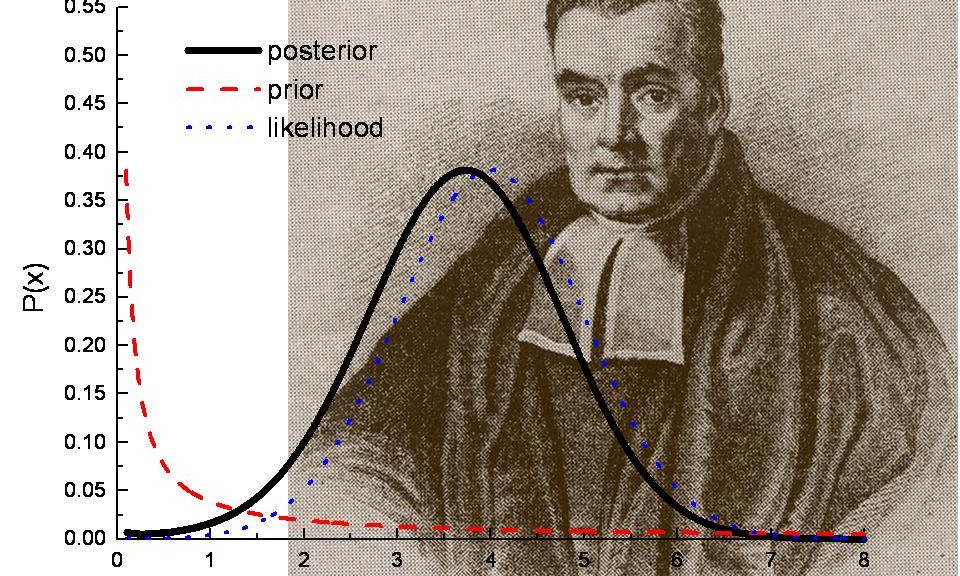
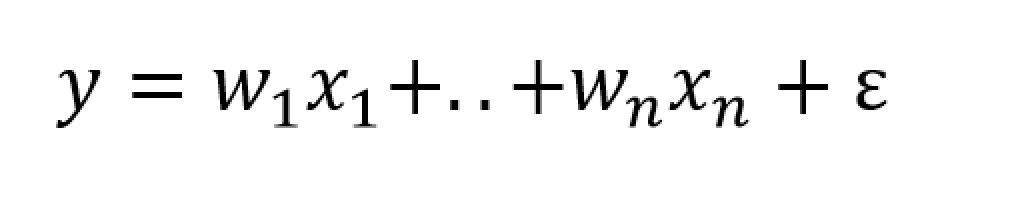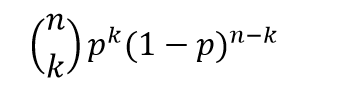The basic idea of Bayesian methods is outstanding. Here is a way of incorporating prior information into analysis, helping to manage, for example, small samples that are endemic in business forecasting.
What I am looking for, in the coming posts on this topic, is what difference does it make.
Bayes Theorem
Just to set the stage, consider the simple statement and derivation of Bayes Theorem –
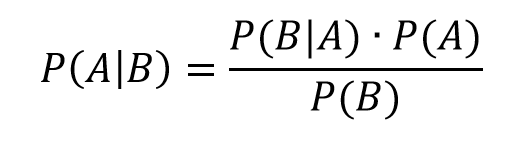
Here A and B are events or occurrences, and P(.) is the probability (of the argument . ) function. So P(A) is the probability of event A. And P(A|B) is the conditional probability of event A, given that event B has occurred.
A Venn diagram helps.
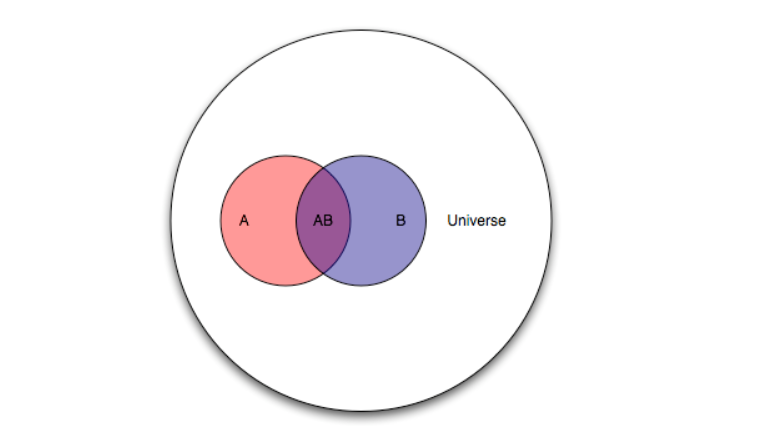
Here, there is the universal set U, and the two subsets A and B. The diagram maps some type of event or belief space. So the probability of A or P(A) is the ratio of the areas A and U.
Then, the conditional probability of the occurrence of A, given the occurrence of B is the ratio of the area labeled AB to the area labeled B in the diagram. Also area AB is the intersection of the areas A and B or A ∩ B in set theory notation. So we have P(A|B)=P(A ∩ B)/P(B).
By the same logic, we can create the expression for P(B|A) = P(B ∩ A)/P(A).
Now to be mathematically complete here, we note that intersection in set theory is commutative, so A ∩ B = B ∩ A, and thus P(A ∩ B)=P(B|A)•P(A). This leads to the initially posed formulation of Bayes Theorem by substitution.
So Bayes Theorem, in its simplest terms, follows from the concept or definition of conditional probability – nothing more.
Prior and Posterior Distributions and the Likelihood Function
With just this simple formulation, one can address questions that are essentially what I call “urn problems.” That is, having drawn some number of balls of different colors from one of several sources (urns), what is the probability that the combination of, say, red and white balls drawn comes from, say, Urn 2? Some versions of even this simple setup seem to provide counter-intuitive values for the resulting P(A|B).
But I am interested primarily in forecasting and data analysis, so let me jump ahead to address a key interpretation of the Bayes Theorem.
Thus, what is all this business about prior and posterior distributions, and also the likelihood function?
Well, considering Bayes Theorem as a statement of beliefs or subjective probabilities, P(A) is the prior distribution, and P(A|B) is the posterior distribution, or the probability distribution that follows revelation of the facts surrounding event (or group of events) B.
P(B|A) then is the likelihood function.
Now all this is more understandable, perhaps, if we reframe Bayes rule in terms of data y and parameters θ of some statistical model.
So we have
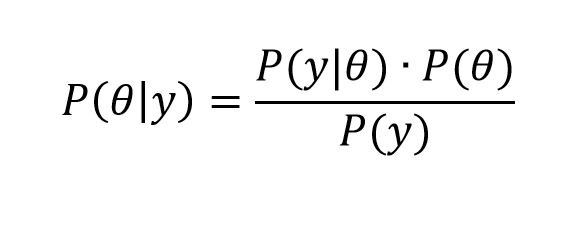
In this case, we have some data observations {y1, y2,…,yn}, and can have covariates x={x1,..,xk}, which could be inserted in the conditional probability of the data, given the parameters on the right hand side of the equation, as P(y|θ,x).
In any case, clear distinctions between the Bayesian and frequentist approach can be drawn with respect to the likelihood function P(y|θ).
So the frequentist approach focuses on maximizing the likelihood function with respect to the unknown parameters θ, which of course can be a vector of several parameters.
As one very clear overview says,
One maximizes the likelihood function L(·) with respect the parameters to obtain the maximum likelihood estimates; i.e., the parameter values most likely to have produced the observed data. To perform inference about the parameters, the frequentist recognizes that the estimated parameters ˆ� result from a single sample, and uses the sampling distribution to compute standard errors, perform hypothesis tests, construct confidence intervals, and the like..
In the Bayesian perspective, the unknown parameters θ are treated as random variables, while the observations y are treated as fixed in some sense.
The focus of attention is then on how the observed data y changes the prior distribution P(θ) into the posterior distribution P(y|θ).
The posterior distribution, in essence, translates the likelihood function into a proper probability distribution over the unknown parameters, which can be summarized just as any probability distribution; by computing expected values, standard deviations, quantiles, and the like. What makes this possible is the formal inclusion of prior information in the analysis.
One difference then is that the frequentist approach optimizes the likelihood function with respect to the unknown parameters, while the Bayesian approach is more concerned with integrating the posterior distribution to obtain values for key metrics and parameters of the situation, after data vector y is taken into account.
Extracting Parameters From the Posterior Distribution
The posterior distribution, in other words, summarizes the statistical model of a phenomenon which we are analyzing, given all the available information.
That sounds pretty good, but the issue is that the result of all these multiplications and divisions on the right hand side of the equation can lead to a posterior distribution which is difficult to evaluate. It’s a probability distribution, for example, and thus some type of integral equation, but there may be no closed form solution.
Prior to Big Data and the muscle of modern computer computations, Bayesian statisticians spent a lot of time and energy searching out conjugate prior’s. Wikipedia has a whole list of these.
So the Beta distribution is a conjugate prior for a Bernoulli distribution – the familiar probability p of success and probability q of failure model (like coin-flipping, when p=q=0.5). This means simply that multiplying a Bernoulli likelihood function by an appropriate Beta distribution leads to a posterior distribution that is again a Beta distribution, and which can be integrated and, also, which supports a sort of loop of estimation with existing and then further data.
Here’s an example and prepare yourself for the flurry of symbolism –
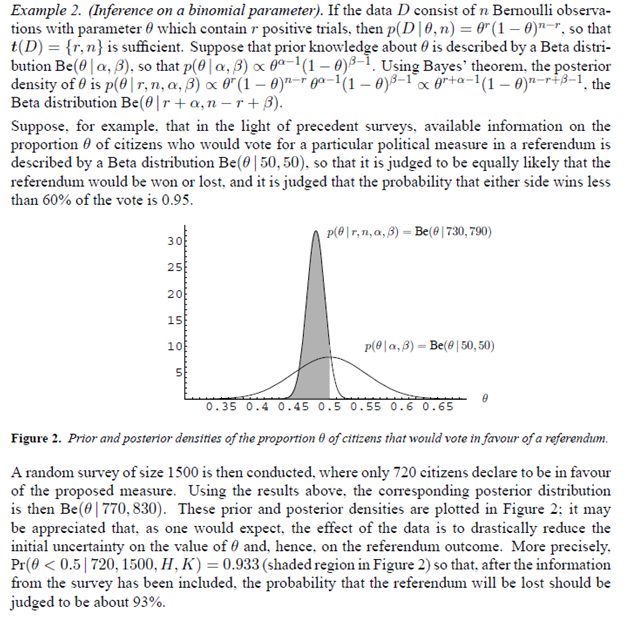
Note the update of the distribution of whether the referendum is won or lost results in a much sharper distribution and increase in the probability of loss of the referendum.
Monte Carlo Methods
Stanislaus Ulam, along with John von Neumann, developed Monte Carlo simulation methods to address what might happen if radioactive materials were brought together in sufficient quantities and with sufficient emissions of neutrons to achieve a critical mass. That is, researchers at Los Alamos at the time were not willing to simply experiment to achieve this effect, and watch the unfolding.
Monte Carlo computation methods, thus, take complicated mathematical relationships and calculate final states or results from random assignments of values of the explanatory variables.
Two algorithms—the Gibbs sampling and Metropolis-Hastings algorithms— are widely used for applied Bayesian work, and both are Markov chain Monte Carlo methods.
The Markov chain aspect of the sampling involves selection of the simulated values along a path determined by prior values that have been sampled.
The object is to converge on the key areas of the posterior distribution.
The Bottom Line
It has taken me several years to comfortably grasp what is going on here with Bayesian statistics.
The question, again, is what difference does it make in forecasting and data analysis? And, also, if it made a difference in comparison with a frequentist interpretation or approach, would that be an entirely good thing?
A lot of it has to do with a reorientation of perspective. So some of the enthusiasm and combative qualities of Bayesians seems to come from their belief that their system of concepts is simply the only coherent one.
But there are a lot of medical applications, including some relating to trials of new drugs and procedures. What goes there? Is the representation that it is not necessary to take all this time required by the FDA to test a drug or procedure, when we can access prior knowledge and bring it to the table in evaluating outcomes?
Or what about forecasting applications? Is there something more productive about some Bayesian approaches to forecasting – something that can be measured in, for example, holdout samples or the like? Or I don’t know whether that violates the spirit of the approach – holdout samples.
I’m planning some posts on this topic. Let me know what you think.
Top picture from Los Alamos laboratories