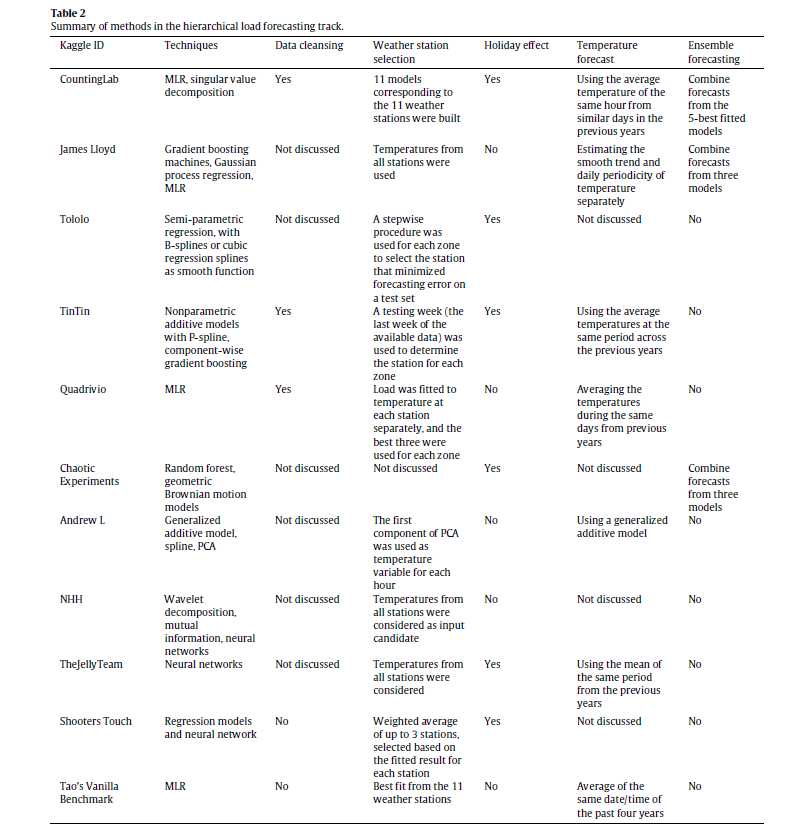
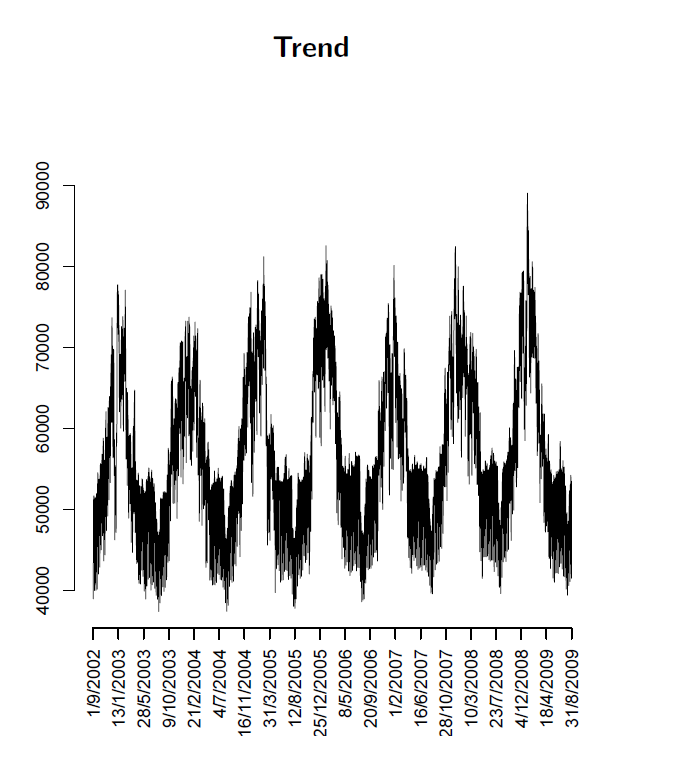
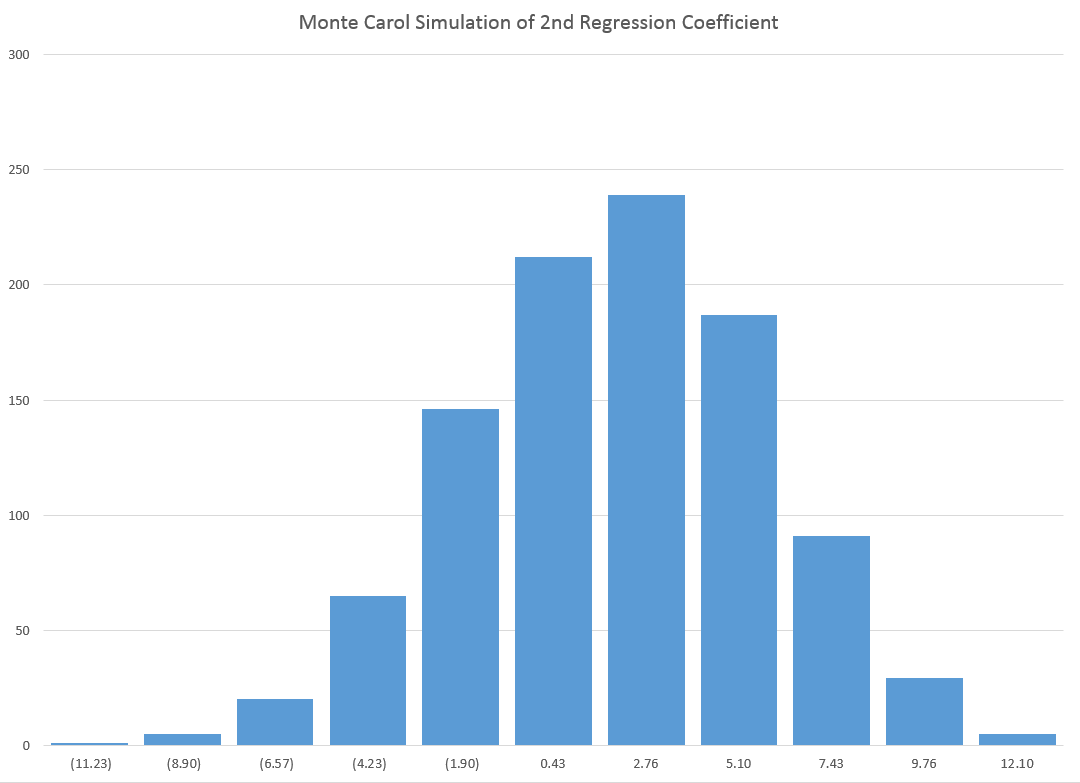
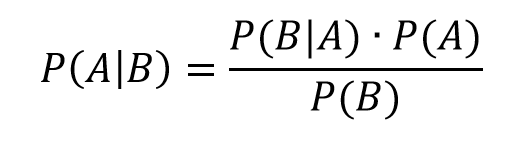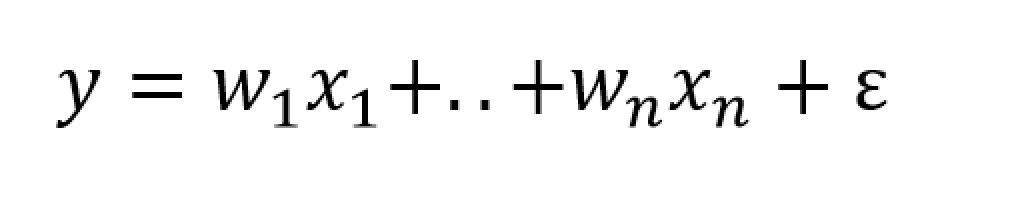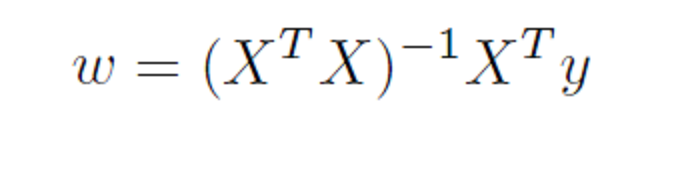The method of principal components regression has achieved new prominence in machine learning, data reduction, and forecasting over the last decade.
It’s highly relevant in the era of Big Data, because it facilitates analyzing “fat” or wide databases. Fat databases have more predictors than observations. So you might have ten years of monthly data on sales, but 1000 potential predictors, meaning your database would be 120 by 1001 – obeying here the convention of stating row depth first and the number of columns second.
After a brief discussion of these Big Data applications and some elements of principal components, I illustrate dimension reduction with a violent crime database from the UC Irvine Machine Learning Repository.
Dynamic Factor Models
In terms of forecasting, a lot of research over the past decade has focused on “many predictors” and reducing the dimensionality of “fat” databases. Key names are James Stock and Mark Watson (see also) and Bai.
Stock and Watson have a white paper that has been updated several times, which can be found in PDF format at this link
stock watson generalized shrinkage June _2012.pdf
They write in the June 2012 update,
We find that, for most macroeconomic time series, among linear estimators the DFM forecasts make efficient use of the information in the many predictors by using only a small number of estimated factors. These series include measures of real economic activity and some other central macroeconomic series, including some interest rates and monetary variables. For these series, the shrinkage methods with estimated parameters fail to provide mean squared error improvements over the DFM. For a small number of series, the shrinkage forecasts improve upon DFM forecasts, at least at some horizons and by some measures, and for these few series, the DFM might not be an adequate approximation. Finally, none of the methods considered here help much for series that are notoriously difficult to forecast, such as exchange rates, stock prices, or price inflation.
Here DFM refers to dynamic factor models, essentially principal components models which utilize PC’s for lagged data.
Note also that this type of autoregressive or classical time series approach does not work well, in Stock and Watson’s judgment, for “series that are notoriously difficult to forecast, such as exchange rates, stock prices, or price inflation.”
Presumably, these series are closer to being random walks in some configuration.
Intermediate Level Concepts
Essentially, you can take any bundle of data and compute the principal components. If you mean-center and (in most cases) standardize the data, the principal components divide up the variance of this data, based on the size of their associated eigenvalues. The associated eigenvectors can be used to transform the data into an equivalent and same size set of orthogonal vectors. Really, the principal components operate to change the basis of the data, transforming it into an equivalent representation, but one in which all the variables have zero correlation with each other.
The Wikipaedia article on principal components is useful, but there is no getting around the fact that principal components can only really be understood with matrix algebra.
Often you see a diagram, such as the one below, showing a cloud of points distributed around a line passing through the origin of a coordinate system, but at an acute angle to those coordinates.
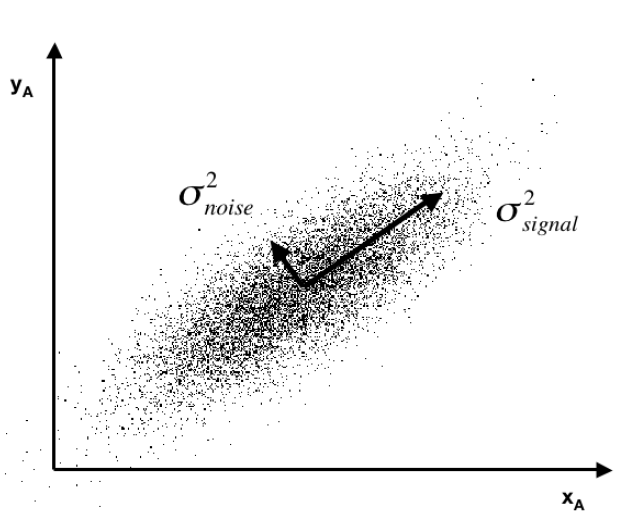
This illustrates dimensionality reduction with principal components. If we express all these points in terms of this rotated set of coordinates, one of these coordinates – the signal – captures most of the variation in the data. Projections of the datapoints onto the second principal component, therefore, account for much less variance.
Principal component regression characteristically specifies only the first few principal components in the regression equation, knowing that, typically, these explain the largest portion of the variance in the data.
An Application to Crime Data
Looking for some non-macroeconomic data to illustrate principal components (PC) regression, I found the Communities and Crime Data Set in the University of California at Irving Machine Learning Repository.
The data do not illustrate “many predictors” in the sense of more predictors than observations.
Here, the crime and other data comprise 128 variables, including a violent crime variable, which are collated for 1994 cities. That is, there are more observations than predictors.
The variables included in the dataset involve the community, such as the percent of the population considered urban, and the median family income, and involving law enforcement, such as per capita number of police officers, and percent of officers assigned to drug units. The per capita violent crimes variable was calculated using population and the sum of crime variables considered violent crimes in the United States: murder, rape, robbery, and assault.
I standardize the data, dropping variables with a lot of missing values. That leaves me 100 variables, including the violent crime metric.
This table gives you a flavor of the variables included – you have to interpret the abbreviations

I developed a comparison of OLS regression with principal components regression, finding that principal component regression can outperform OLS in out-of-sample predictions of violent crimes per capita.
The Matlab program to carry out this analysis is as follows:
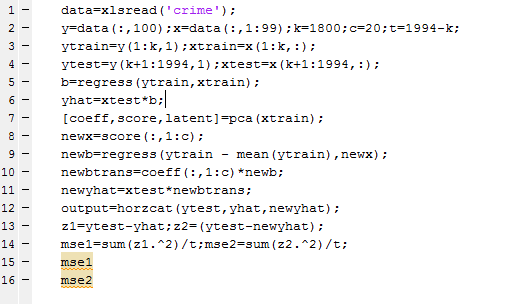
So I used a training set of 1800 cities, and developed OLS and PC regressions to predict violent crime per capita in the remaining 194 cities. I calculate the principal components (coeff) from a training set (xtrain) comprised of the first 1800 cities. Then, I select the first twenty pc’s and translate them back to weightings on all 99 variables for application to the test set (xtest). I also calculate OLS regression coefficients on xtrain.
The mean square prediction error (mse1) of the OLS regression was 0.35 and the mean square prediction error (mse2) of the PC regression was 0.34 – really a marginal difference but large enough to make the point.
What’s really interesting is that I had to use the first twenty (20) principal components to achieve this improvement. Thus, this violent crime database has a quite diverse characteristic, compared with many socioeconomic datasets I have seen, where, as noted above, the first few principal components explain most of the variation in the data.
This method – PC regression – is especially good when there are predictors which are closely correlated (“multicollinearity”) as often is the case with market research surveys of consumer attitudes and income and wealth variables.
The bottom line here is that principal compoments can facilitate data reduction or regression regularization. Quite often, this can improve the prediction capabilities of a regression, when compared with an OLS regression using all the variables. The PC regression assigns higher weights to the most important predictors, in effect performing a kind of variable selection – although the coefficients or pc’s may not zero out variables per se.
I am continuing to work on this data with an eye to implementing k-fold cross-validation as a way of estimating the optimal number of principal components which should be used in the PC regressions.