I am interested in business forecasting “stories.” For example, the glitch in Google’s flu forecasting program.
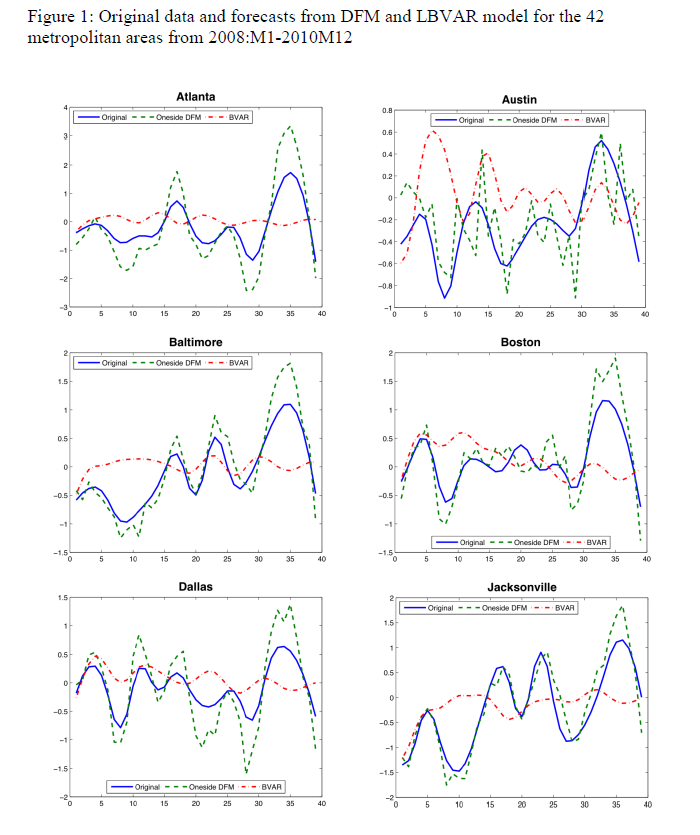
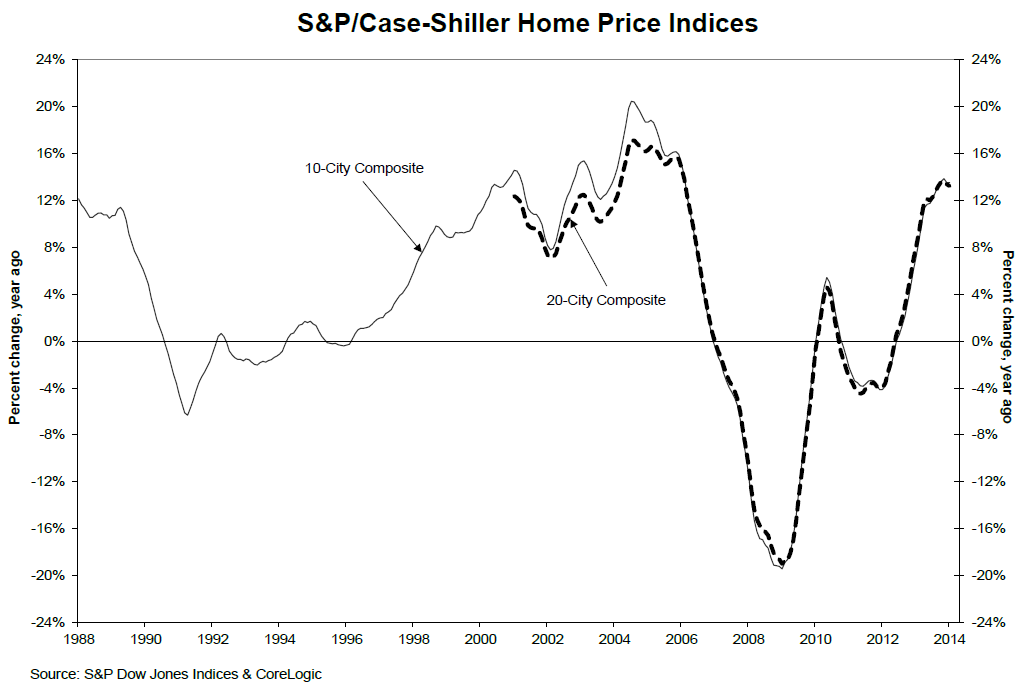
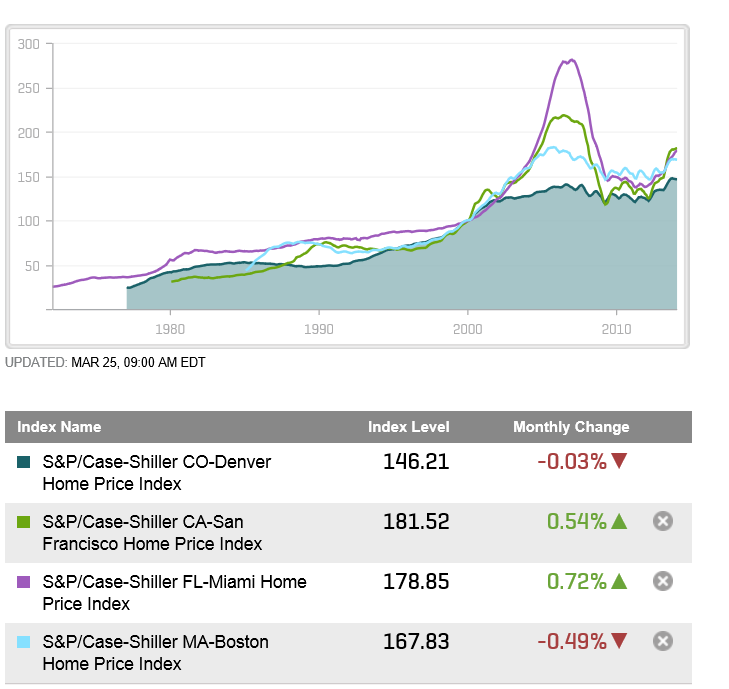
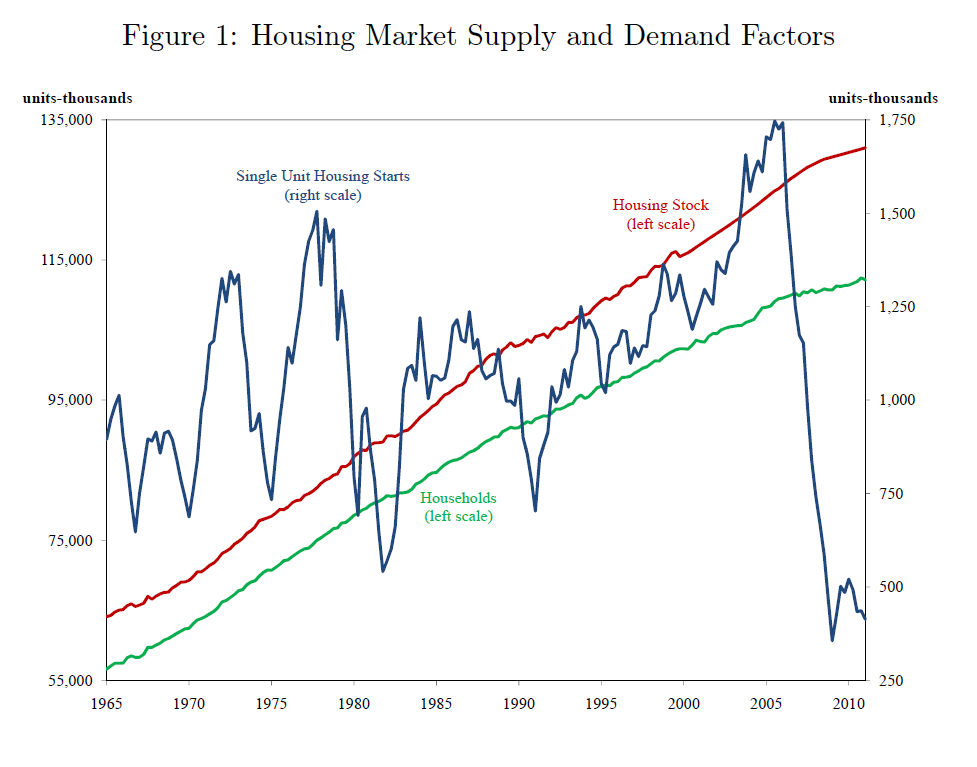
In real estate forecasting, the obvious thing is whether quantitative forecasting models can (or, better yet, did) forecast the collapse in housing prices and starts in the recent 2008-2010 recession (see graphics from the previous post).
There are several ways of going at this.
Who Saw The Housing Bubble Coming?
One is to look back to see whether anyone saw the bursting of the housing bubble coming and what forecasting models they were consulting.
That’s entertaining. Some people, like Ron Paul, and Nouriel Roubini, were prescient.
Roubini earned the soubriquet Dr. Doom for an early prediction of housing market collapse, as reported by the New York Times:
On Sept. 7, 2006, Nouriel Roubini, an economics professor at New York University, stood before an audience of economists at the International Monetary Fund and announced that a crisis was brewing. In the coming months and years, he warned, the United States was likely to face a once-in-a-lifetime housing bust, an oil shock, sharply declining consumer confidence and, ultimately, a deep recession. He laid out a bleak sequence of events: homeowners defaulting on mortgages, trillions of dollars of mortgage-backed securities unraveling worldwide and the global financial system shuddering to a halt. These developments, he went on, could cripple or destroy hedge funds, investment banks and other major financial institutions like Fannie Mae and Freddie Mac.

Roubini was spot-on, of course, even though, at the time, jokes circulated such as “even a broken clock is right twice a day.” And my guess is his forecasting model, so to speak, is presented in Crisis Economics: A Crash Course in the Future of Finance, his 2010 book with Stephen Mihm. It is less a model than whole database of tendencies, institutional facts, areas in which Roubini correctly identifies moral hazard.
I think Ron Paul, whose projections of collapse came earlier (2003), was operating from some type of libertarian economic model. So Paul testified before House Financial Services Committee on Fannie Mae and Freddy Mac, that –
Ironically, by transferring the risk of a widespread mortgage default, the government increases the likelihood of a painful crash in the housing market,” Paul predicted. “This is because the special privileges granted to Fannie and Freddie have distorted the housing market by allowing them to attract capital they could not attract under pure market conditions. As a result, capital is diverted from its most productive use into housing. This reduces the efficacy of the entire market and thus reduces the standard of living of all Americans.
On the other hand, there is Ben Bernanke, who in a CNBC interview in 2005 said:
7/1/05 – Interview on CNBC
INTERVIEWER: Ben, there’s been a lot of talk about a housing bubble, particularly, you know [inaudible] from all sorts of places. Can you give us your view as to whether or not there is a housing bubble out there?
BERNANKE: Well, unquestionably, housing prices are up quite a bit; I think it’s important to note that fundamentals are also very strong. We’ve got a growing economy, jobs, incomes. We’ve got very low mortgage rates. We’ve got demographics supporting housing growth. We’ve got restricted supply in some places. So it’s certainly understandable that prices would go up some. I don’t know whether prices are exactly where they should be, but I think it’s fair to say that much of what’s happened is supported by the strength of the economy.
Bernanke was backed by one of the most far-reaching economic data collection and analysis operations in the United States, since he was in 2005 a member of the Board of Governors of the Federal Reserve System and Chairman of the President’s Council of Economic Advisors.
So that’s kind of how it is. Outsiders, like Roubini and perhaps Paul, make the correct call, but highly respected and well-placed insiders like Bernanke simply cannot interpret the data at their fingertips to suggest that a massive bubble was underway.
I think it is interesting currently that Roubini, in March, promoted the idea that Yellen Is Creating another huge Bubble in the Economy
But What Are the Quantitative Models For Forecasting the Housing Market?
In a long article in the New York Times in 2009, How Did Economists Get It So Wrong?, Paul Krugman lays the problem at the feet of the efficient market hypothesis –
When it comes to the all-too-human problem of recessions and depressions, economists need to abandon the neat but wrong solution of assuming that everyone is rational and markets work perfectly.
Along these lines, it is interesting that the Zillow home value forecast methodology builds on research which, in one set of models, assumes serial correlation and mean reversion to a long-term price trend.

Key research in housing market dynamics includes Case and Shiller (1989) and Capozza et al (2004), who show that the housing market is not efficient and house prices exhibit strong serial correlation and mean reversion, where large market swings are usually followed by reversals to the unobserved fundamental price levels.
Based on the estimated model parameters, Capozza et al are able to reveal the housing market characteristics where serial correlation, mean reversion, and oscillatory, convergent, or divergent trends can be derived from the model parameters.
Here is an abstract from critical research underlying this approach done in 2004.
An Anatomy of Price Dynamics in Illiquid Markets: Analysis and Evidence from Local Housing Markets
This research analyzes the dynamic properties of the difference equation that arises when markets exhibit serial correlation and mean reversion. We identify the correlation and reversion parameters for which prices will overshoot equilibrium (“cycles”) and/or diverge permanently from equilibrium. We then estimate the serial correlation and mean reversion coefficients from a large panel data set of 62 metro areas from 1979 to 1995 conditional on a set of economic variables that proxy for information costs, supply costs and expectations. Serial correlation is higher in metro areas with higher real incomes, population growth and real construction costs. Mean reversion is greater in large metro areas and faster growing cities with lower construction costs. The average fitted values for mean reversion and serial correlation lie in the convergent oscillatory region, but specific observations fall in both the damped and oscillatory regions and in both the convergent and divergent regions. Thus, the dynamic properties of housing markets are specific to the given time and location being considered.
The article is not available for free download so far as I can determine. But it is based on earler research, dating back to the later 1990’s in the pdf The Dynamic Structure of Housing Markets.
The more recent Housing Market Dynamics: Evidence of Mean Reversion and Downward Rigidity by Fannie Mae researchers, lists a lot of relevant research on the serial correlation of housing prices, which is usually locality-dependent.
In fact, the Zillow forecasts are based on ensemble methods, combining univariate and multivariate models – a sign of modernity in the era of Big Data.
So far, though, I have not found a truly retrospective study of the housing market collapse, based on quantitative models. Perhaps that is because only the Roubini approach works with such complex global market phenomena.
We are left, thus, with solid theoretical foundations, validated by multiple housing databases over different time periods, that suggests that people invest in housing based on momentum factors – and that this fairly obvious observation can be shown statistically, too.