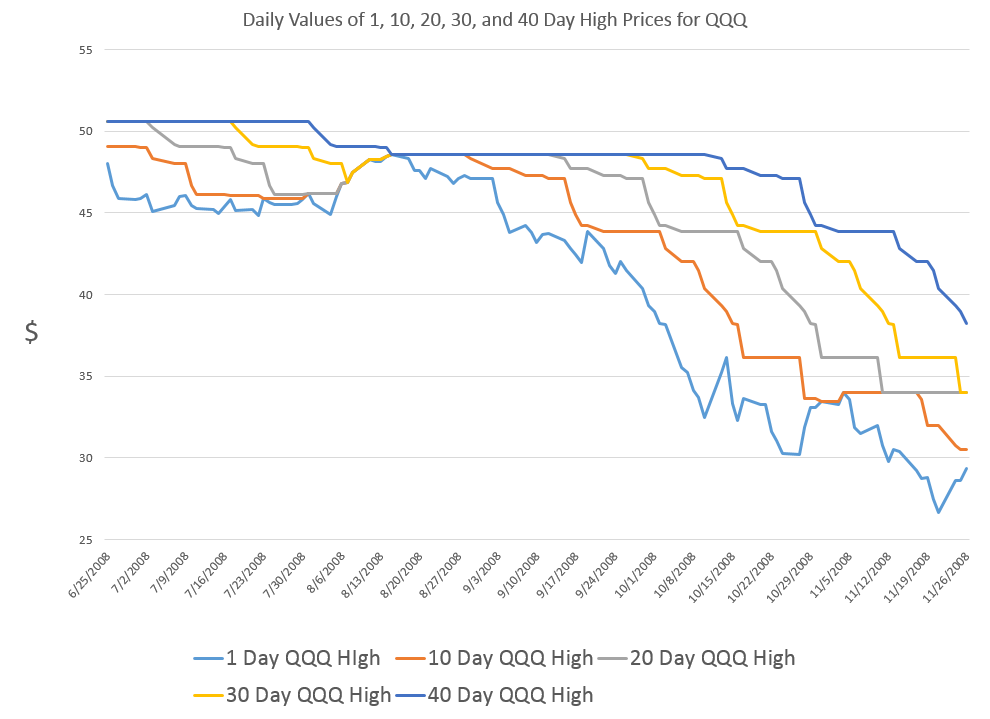
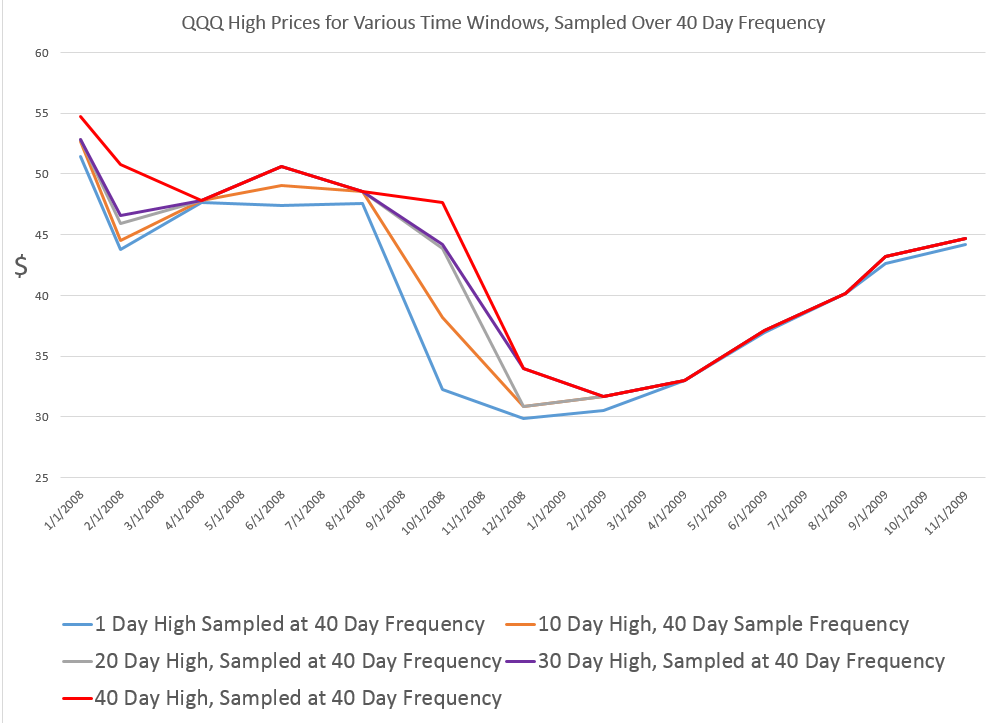
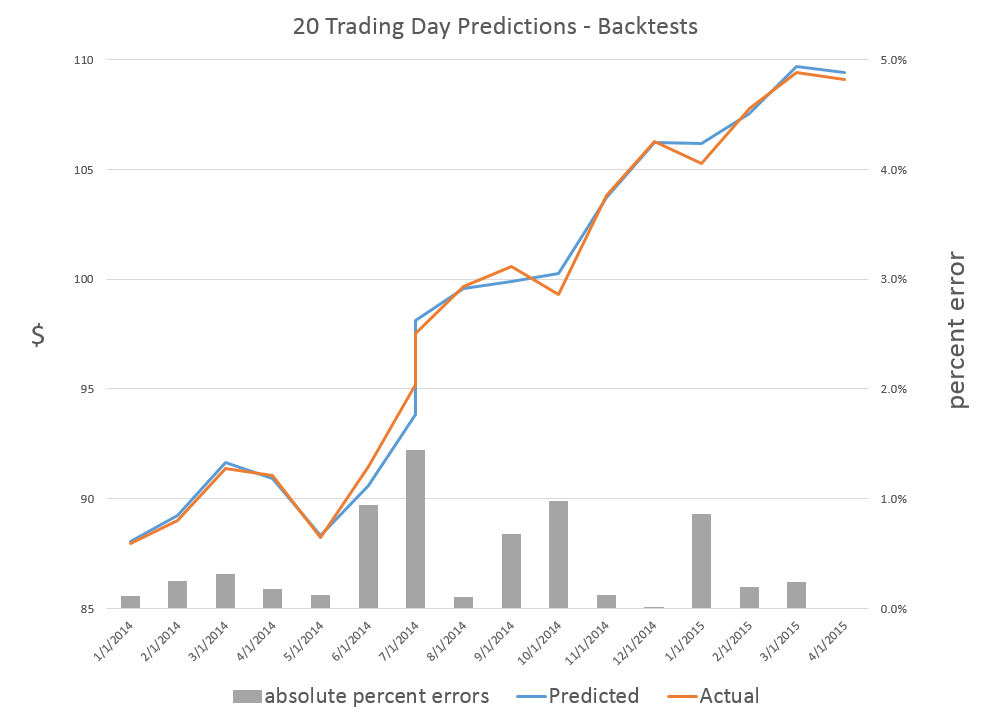
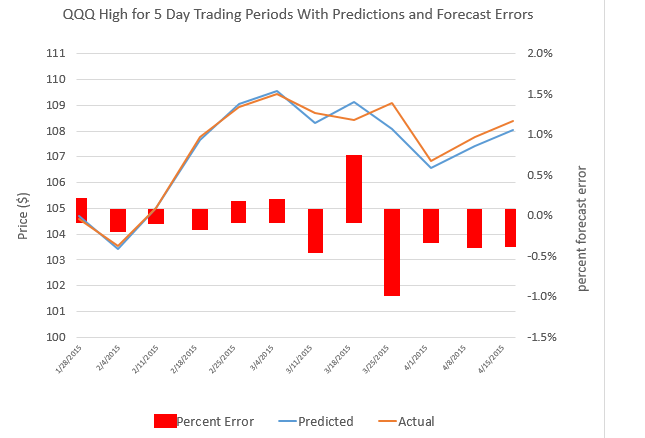
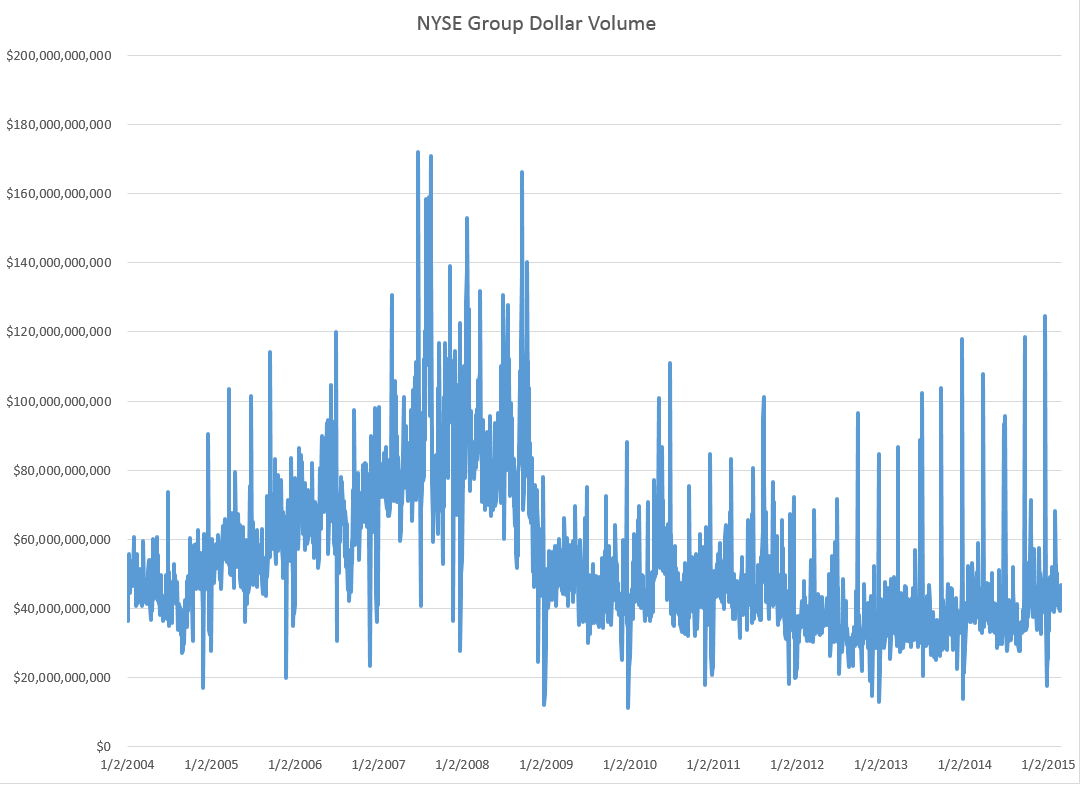
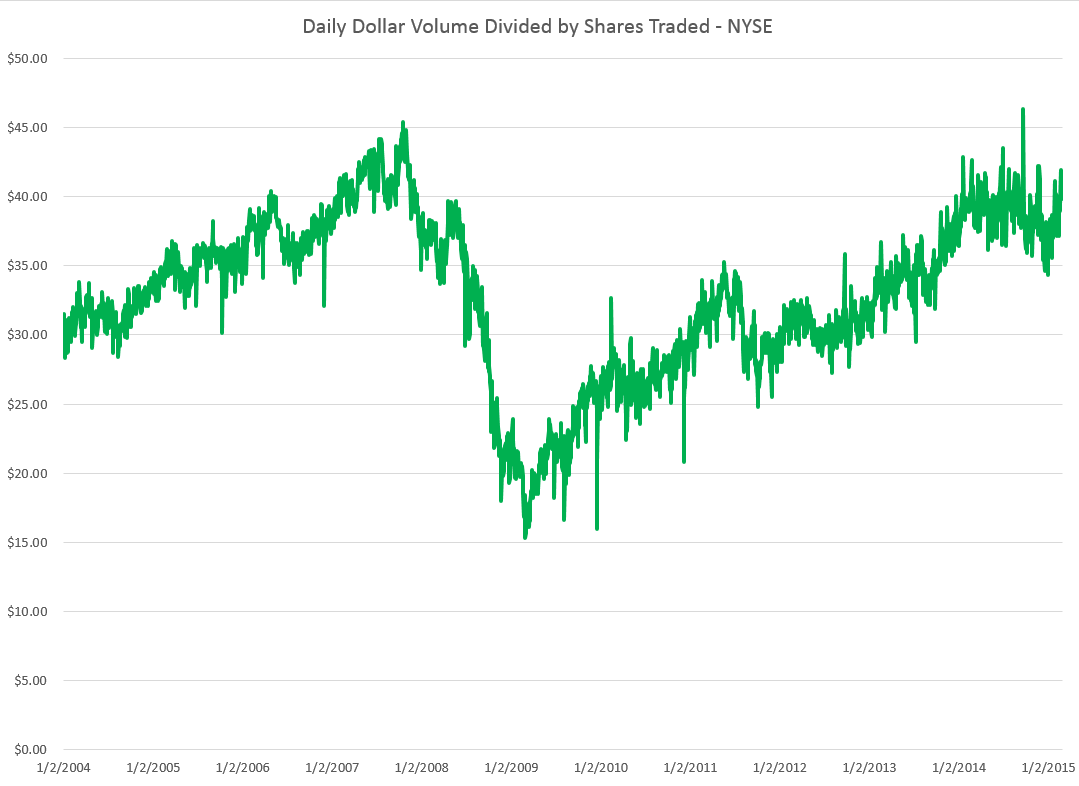
Blogging gets to be enjoyable, although demanding. It’s a great way to stay in touch, and probably heightens personal mental awareness, if you do it enough.
The “Business Forecasting” focus allows for great breadth, but may come with political constraints.
On this latter point, I assume people have to make a living. Populations cannot just spend all their time in mass rallies, and in political protests – although that really becomes dominant at certain crisis points. We have not reached one of those for a long time in the US, although there have been mobilizations throughout the Mid-East and North Africa recently.
Nate Silver brought forth the “hedgehog and fox” parable in his best seller – The Signal and the Noise. “The fox knows many things, but the hedgehog knows one big thing.”
My view is that business and other forecasting endeavors should be “fox-like” – drawing on many sources, including, but not limited to quantitative modeling.
What I Think Is Happening – Big Picture
Global dynamics often are directly related to business performance, particularly for multinationals.
And global dynamics usually are discussed by regions – Europe, North America, Asia-Pacific, South Asia, the Mid-east, South American, Africa.
The big story since around 2000 has been the emergence of the People’s Republic of China as a global player. You really can’t project the global economy without a fairly detailed understanding of what’s going on in China, the home of around 1.5 billion persons (not the official number).
Without delving much into detail, I think it is clear that a multi-centric world is emerging. Growth rates of China and India far surpass those of the United States and certainly of Europe – where many countries, especially those along the southern or outer rim – are mired in high unemployment, deflation, and negative growth since just after the financial crisis of 2008-2009.
The “old core” countries of Western Europe, the United States, Canada, and, really now, Japan are moving into a “post-industrial” world, as manufacturing jobs are outsourced to lower wage areas.
Layered on top of and providing support for out-sourcing, not only of manufacturing but also skilled professional tasks like computer programming, is an increasingly top-heavy edifice of finance.
Clearly, “the West” could not continue its pre-World War II monopoly of science and technology (Japan being in the pack here somewhere). Knowledge had to diffuse globally.
With the GATT (General Agreement on Tariffs and Trade) and the creation of the World Trade Organization (WTO) the volume of trade expanded with reduction on tariffs and other barriers (1980’s, 1990’s, early 2000’s).
In the United States the urban landscape became littered with “Big Box stores” offering shelves full of clothing, electronics, and other stuff delivered to the US in the large shipping containers you see stacked hundreds of feet high at major ports, like San Francisco or Los Angeles.
There is, indeed, a kind of “hollowing out” of the American industrial machine.
Possibly it’s only the US effort to maintain a defense establishment second-to-none and of an order of magnitude larger than anyone elses’ that sustains certain industrial activities shore-side. And even that is problematical, since the chain of contracting out can be complex and difficult and costly to follow, if you are a US regulator.
I’m a big fan of post-War Japan, in the sense that I strongly endorse the kinds of evaluations and decisions made by the Japanese Ministry of International Trade and Investment (MITI) in the decades following World War II. Of course, a nation whose industries and even standing structures lay in ruins has an opportunity to rebuild from the ground up.
In any case, sticking to a current focus, I see opportunities in the US, if the political will could be found. I refer here to the opportunity for infrastructure investment to replace aging bridges, schools, seaport and airport facilities.
In case you had not noticed, interest rates are almost zero. Issuing bonds to finance infrastructure could not face more favorable terms.
Another option, in my mind – and a hat-tip to the fearsome Walt Rostow for this kind of thinking – is for the US to concentrate its resources into medicine and medical care. Already, about one quarter of all spending in the US goes to health care and related activities. There are leading pharma and biotech companies, and still a highly developed system of biomedical research facilities affiliated with universities and medical schools – although the various “austerities” of recent years are taking their toll.
So, instead of pouring money down a rathole of chasing errant misfits in the deserts of the Middle East, why not redirect resources to amplify the medical industry in the US? Hospitals, after all, draw employees from all socioeconomic groups and all ethnicities. The US and other national populations are aging, and will want and need additional medical care. If the world could turn to the US for leading edge medical treatment, that in itself could be a kind of foreign policy, for those interested in maintaining US international dominance.
Tangential Forces
While writing in this vein, I might as well offer my underlying theory of social and economic change. It is that major change occurs primarily through the impact of tangential forces, things not fully seen or anticipated. Perhaps the only certainty about the future is that there will be surprises.
Quite a few others subscribe to this theory, and the cottage industry in alarming predictions of improbable events – meteor strikes, flipping of the earth’s axis, pandemics – is proof of this.
Really, it is quite amazing how the billions on this planet manage to muddle through.
But I am thinking here of climate change as a tangential force.
And it is also a huge challenge.
But it is a remarkably subtle thing, not withstanding the on-the-ground reality of droughts, hurricanes, tornados, floods, and so forth.
And it is something smack in the sweet spot of forecasting.
There is no discussion of suitable responses to climate change without reference to forecasts of global temperature and impacts, say, of significant increases in sea level.
But these things take place over many years and, then, boom a whole change of regime may be triggered – as ice core and other evidence suggests.
Flexibility, Redundancy, Avoidance of Over-Specialization
My brother (by a marriage) is a priest, formerly a tax lawyer. We have begun a dialogue recently where we are looking for some basis for a new politics and new outlook, really that would take the increasing fragility of some of our complex and highly specialized systems into account – creating some backup systems, places, refuges, if you will.
I think there is a general principle that we need to empower people to be able to help themselves – and I am not talking about eliminating the social safety net. The ruling groups in the United States, powerful interests, and politicians would be well advised to consider how we can create spaces for people “to do their thing.” We need to preserve certain types of environments and opportunities, and have a politics that speaks to this, as well as to how efficiency is going to be maximized by scrapping local control and letting global business from wherever come in and have its way – no interference allowed.
The reason Reid and I think of this as a search for a new politics is that, you know, the counterpoint is that all these impediments to getting the best profits possible just result in lower production levels, meaning then that you have not really done good by trying to preserve land uses or local agriculture, or locally produced manufactures.
I got it from a good source in Beijing some years ago that the Chinese Communist Party believes that full-out growth of production, despite the intense pollution, should be followed for a time, before dealing with that problem directly. If anyone has any doubts about the rationality of limiting profits (as conventionally defined), I suggest they spend some time in China during an intense bout of urban pollution somewhere.
Maybe there are abstract, theoretical tools which could be developed to support a new politics. Why not, for example, quantify value experienced by populations in a more comprehensive way? Why not link achievement of higher value differently measured with direct payments, somehow? I mean the whole system of money is largely an artifact of cyberspace anyway.
Anyway – takeaway thought, create spaces for people to do their thing. Pretty profound 21st Century political concept.
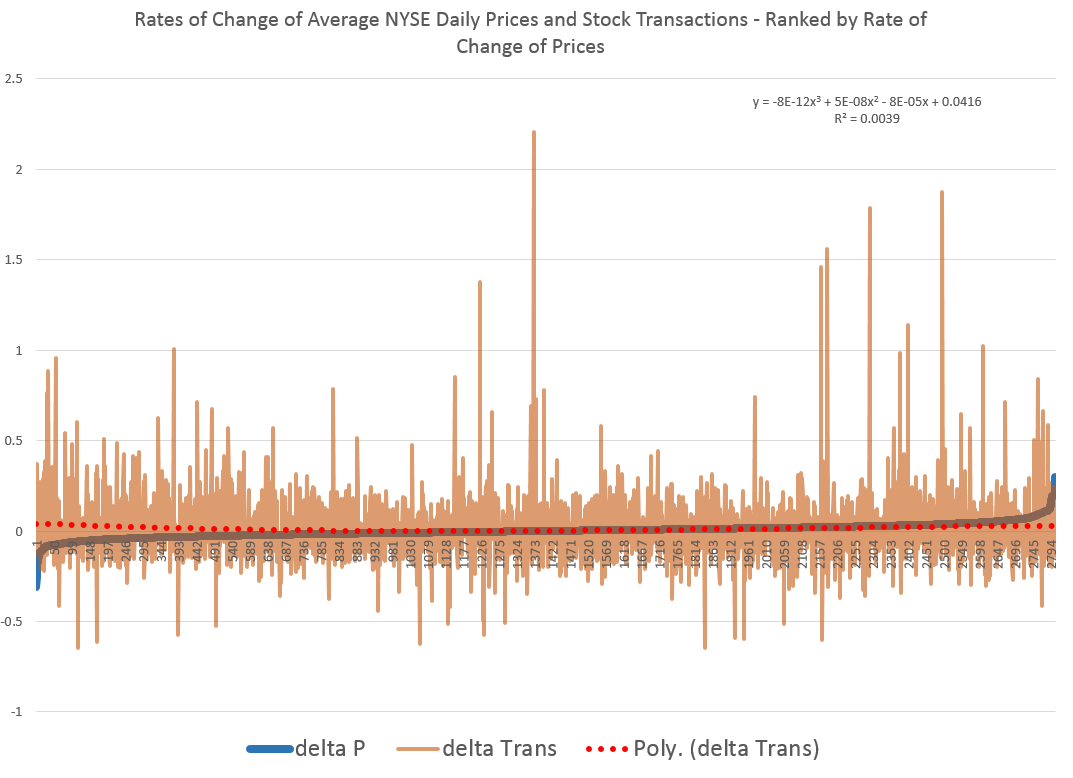
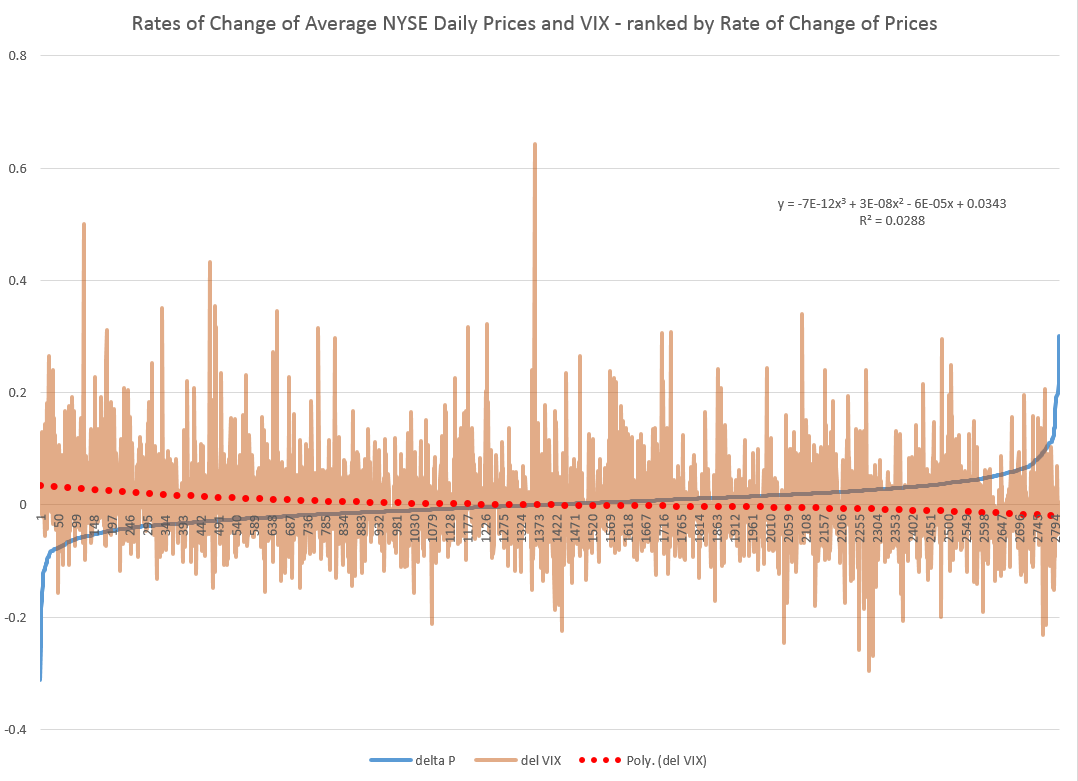
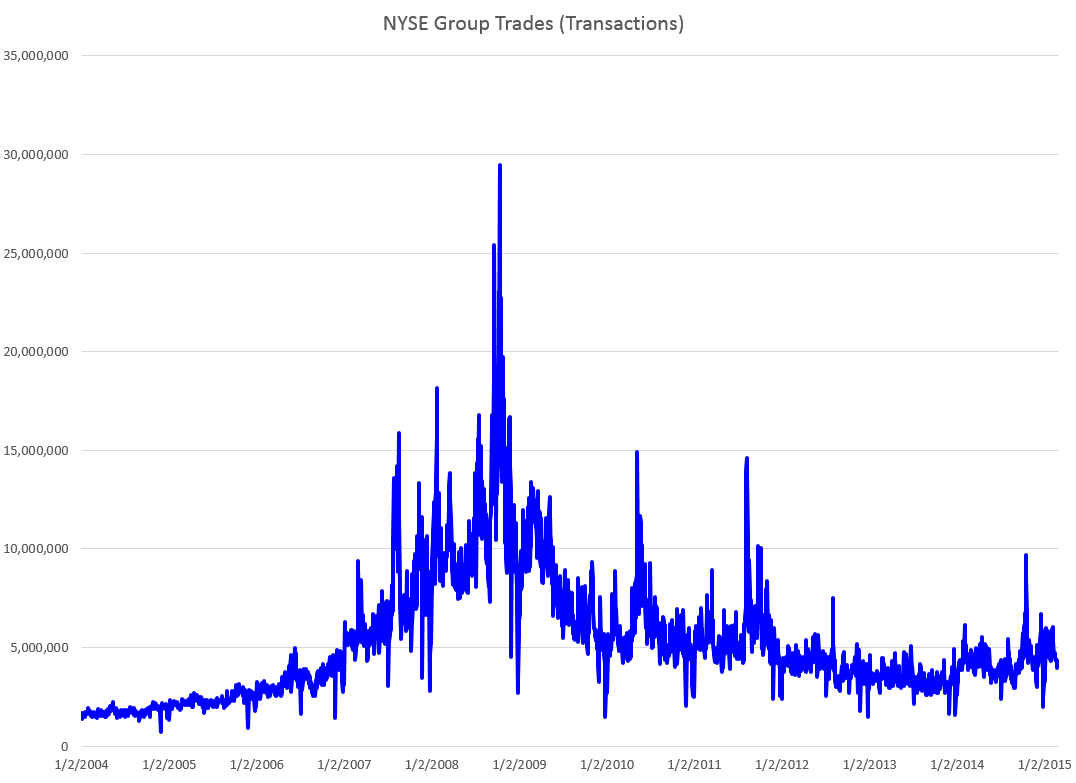
Coming attractions here – more on predicting the stock market (a new approach), summaries of outlooks for the year by major sources (banks, government agencies, leading economists), megatrends, forecasting controversies.
Top picture from FIREBELLY marketing