Can interest rates be nonstationary?
This seems like a strange question, since interest rates are bounded, except in circumstances, perhaps, of total economic collapse.
“Standard” nonstationary processes, by contrast, can increase or decrease without limit, as can conventional random walks.
But, be careful. It’s mathematically possible to define and study random walks with reflecting barriers –which, when they reach a maximum or minimum, “bounce” back from the barrier.
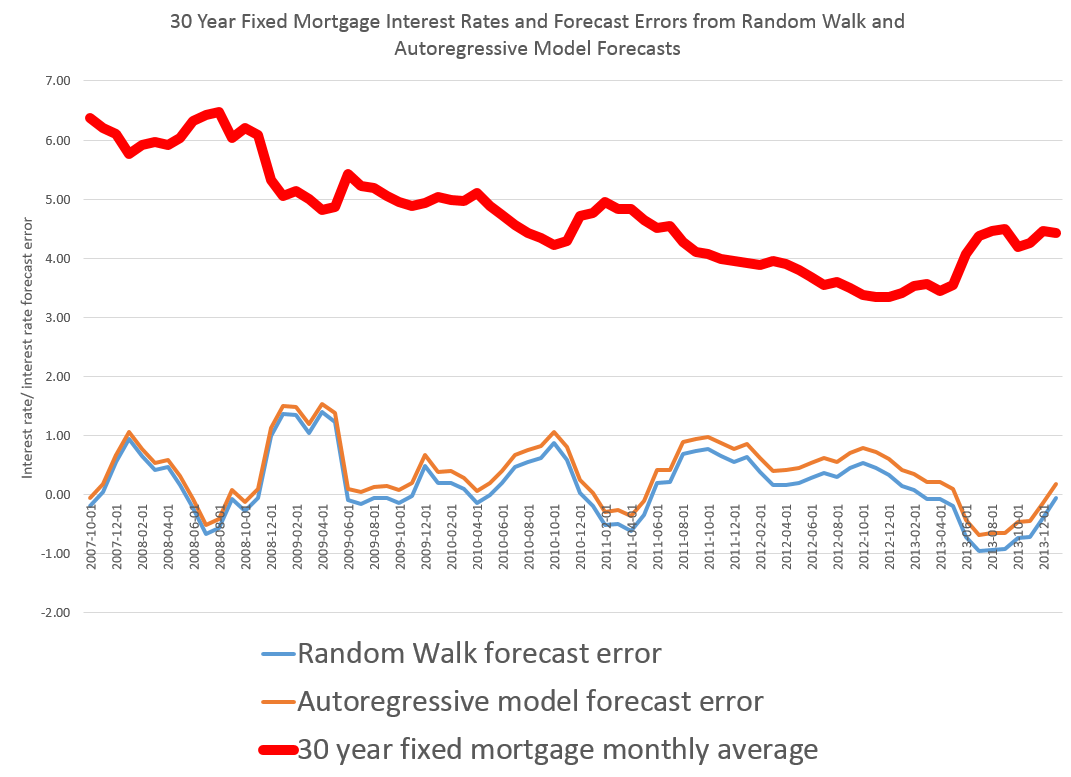
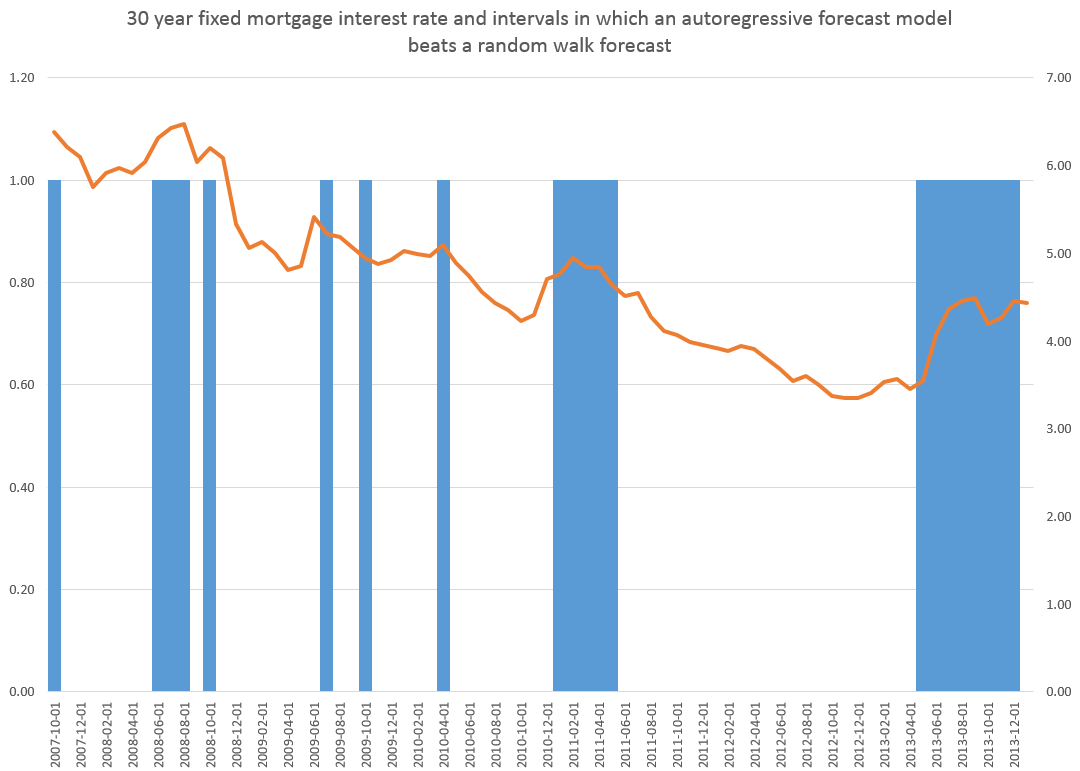
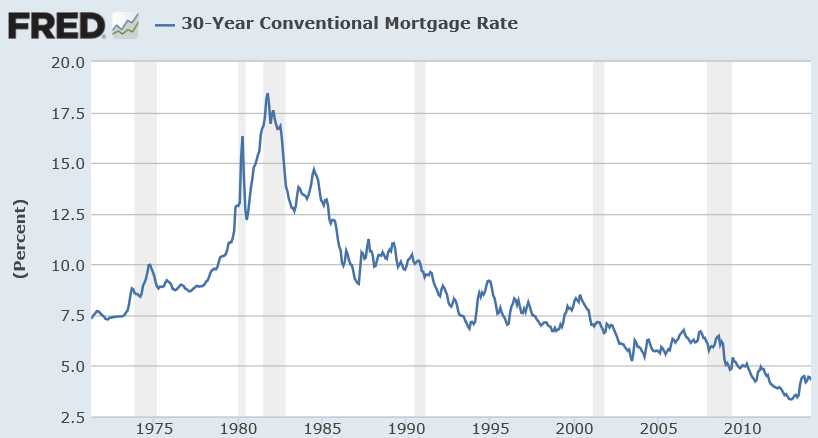
This is more than esoteric, since the 30 year fixed mortgage rate monthly averages series discussed in the previous post has a curious property. It can be differenced many times, and yet display first order autocorrelation of the resulting series.
This contrasts with the 10 year fixed maturity Treasury bond rates (also monthly averages). After first differencing this Treasury bond series, the resulting residuals do not show statistically significant first order autocorrelation.
Here a stationary stochastic process is one in which the probability distribution of the outcomes does not shift with time, so the conditional mean and conditional variance are, in the strict case, constant. A classic example is white noise, where each element can be viewed as an independent draw from a Gaussian distribution with zero mean and constant variance.
30 Year Fixed Mortgage Monthly Averages – a Nonstationary Time Series?
Here are some autocorrelation functions (ACF’s) and partial autocorrelation functions (PACF’s) of the 30 year fixed mortgage monthly averages from April 1971 to January 2014, first differences of this series, and second differences of this series – altogether six charts produced by MATLAB’s plot routines.
Data for this and the following series are downloaded from the St. Louis Fed FRED site.
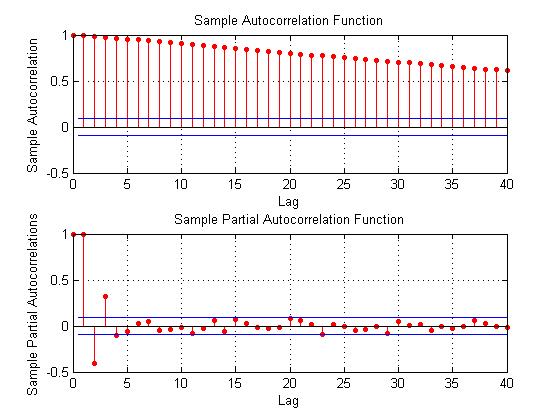
Here the PACF appears to cut off after 4 periods, but maybe not quite, since there are values for lags which touch the statistical significance boundary further out.
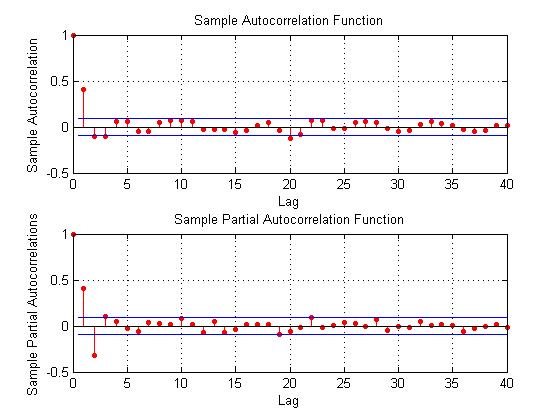
This seems more satisfactory, since there is only one major spike in the ACF and 2-3 initial spikes in the PACF. Again, however, values for lags far out on the horizontal axis appear to touch the boundary of statistical significance.
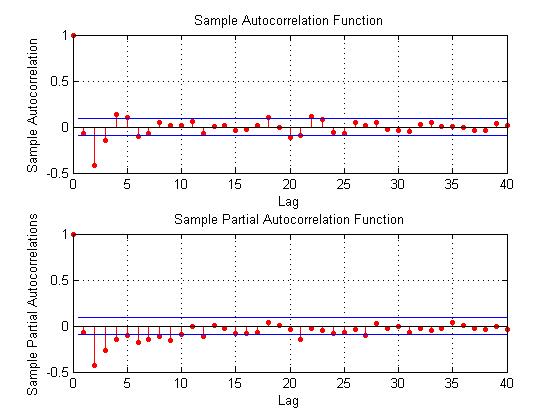
Here are the ACF and PACF’s of the “difference of the first difference” or the second difference, if you like. This spike at period 2 for the ACF and PACF is intriguing, and, for me, difficult to interpret.
The data series includes 514 values, so we are not dealing with a small sample in conventional terms.
I also checked for seasonal variation – either additive or multiplicative seasonal components or factors. After taking steps to remove this type of variation, if it exists, the same pattern of repeated significance of autocorrelations of differences and higher order differences persists.
Forecast Pro, a good business workhorse for automatic forecasting, selects ARIMA(0,1,1) as the optimal forecast model for this 30 year fixed interest mortgage monthly averages. In other words, Forecast Pro glosses over the fact that the residuals from an ARIMA(0,1,1) setup still contain significant autocorrelation.
Here is a sample of the output (click to enlarge)
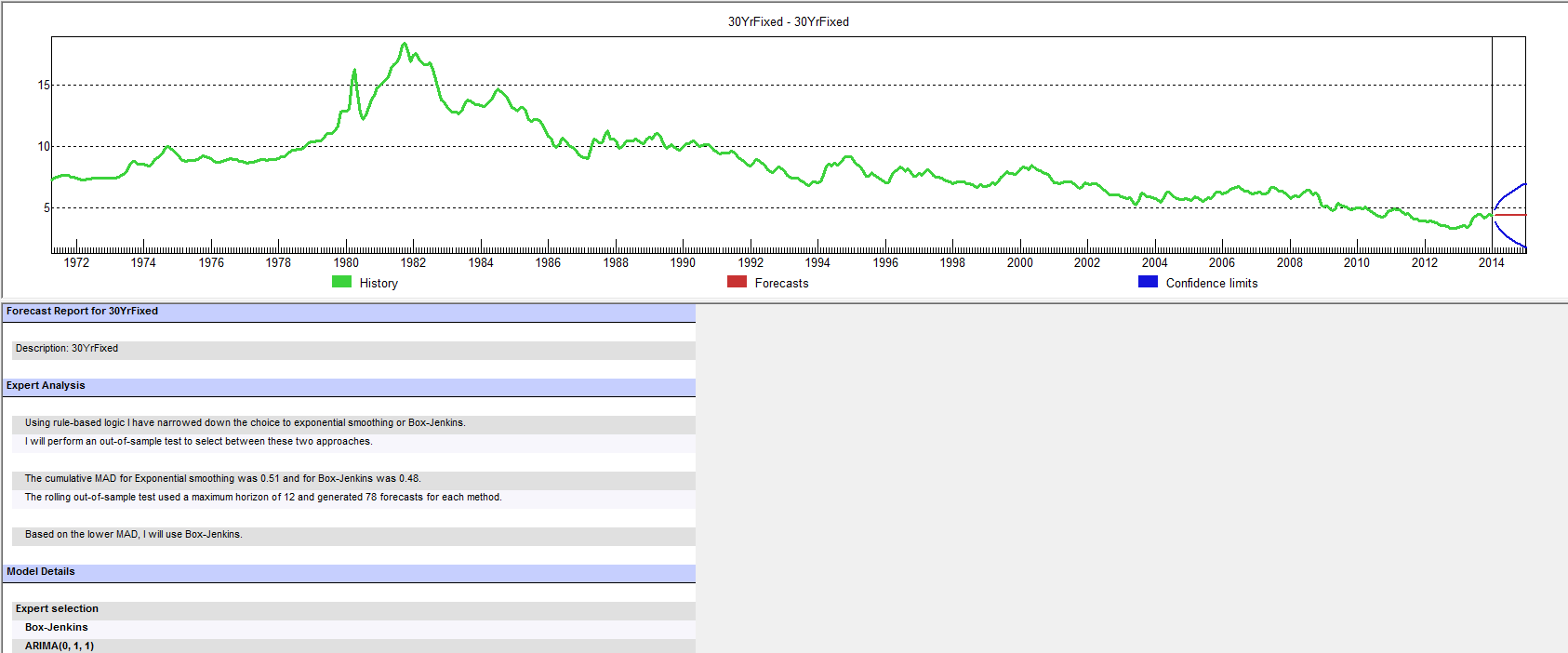
10 Year Treasury Bonds Constant Maturity
The situation is quite different for 10 year Treasury Bonds monthly averages, where the downloaded series starts April 1953 and, again, ends January 2014.
Here is the ordinary least squares (OLS) regression of the first order autocorrelation.
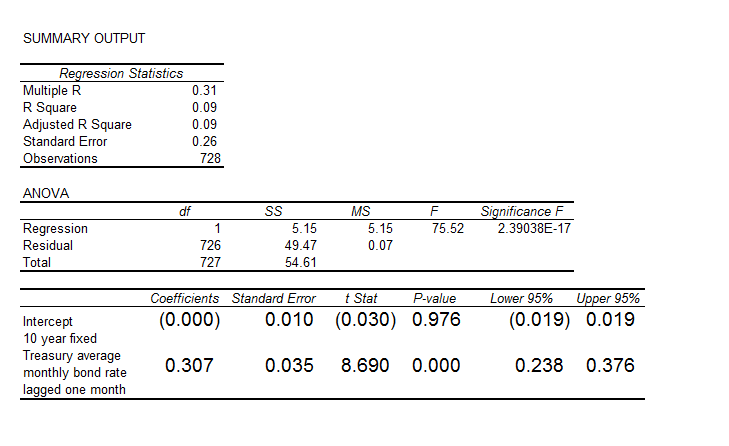 Here the R2 or coefficient of determination is much lower than for the 30 year fixed mortgage monthly averages, but the first order lagged rate is highly significant statistically.
Here the R2 or coefficient of determination is much lower than for the 30 year fixed mortgage monthly averages, but the first order lagged rate is highly significant statistically.
On the other hand, the residuals of this regression do not exhibit a high degree of first order autocorrelation, falling below the 80 percent significance level.
What Does This Mean?
The closest I have come to formulating an explanation for this weird difference between these two “interest rates” is the discussion in a paper from 2002 –
On Mean Reversion in Real Interest Rates: An Application of Threshold Cointegration
The authors of this research paper from the Institute for Advanced Studies in Vienna acknowledge findings that some interests rates may be nonstationary, at least over some periods of time. Their solution is a nonlinear time series approach, but they highlight several of the more exotic statistical features of interest rates in passing – such as evidence of non-normal distributions, excess kurtosis, conditional heteroskedasticity, and long memory.
In any case, I wonder whether the 30 year fixed mortgage monthly averages might be suitable for some type of boosting model working on residuals and residuals of residuals.
I’m going to try that later on this Spring.